高并发系统设计的三利器:缓存、限流、降级,
三利器简述
缓存
缓存比较好理解,在大型高并发系统中,如果没有缓存数据库将分分钟被爆,系统也会瞬间瘫痪。使用缓存不单单能够提升系统访问速度、提高并发访问量,也是保护数据库、保护系统的有效方式。大型网站一般主要是“读”,缓存的使用很容易被想到。在大型“写”系统中,缓存也常常扮演者非常重要的角色。比如累积一些数据批量写入,内存里面的缓存队列(生产消费),以及HBase写数据的机制等等也都是通过缓存提升系统的吞吐量或者实现系统的保护措施。甚至消息中间件,你也可以认为是一种分布式的数据缓存。
降级
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
以下根据限流分类依据不同,简述不同的限流策略。
基于限流位置分类
客户端限流
合法性验证限流:比如验证码、手机验证码等,这些手段可以有效的防止恶意攻击和爬虫采集;
接入端限流
利用流量入口限流:比如 Tomcat、Nginx 等限流手段,
其中 Tomcat 可以设置最大线程数(maxThreads),当并发超过最大线程数会排队等待执行;
而Nginx提供了两种限流手段:一是控制速率,二是控制并发连接数;
第一种:控制速率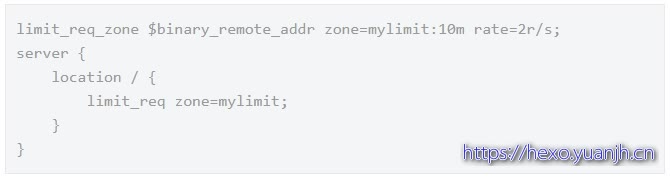
使用 limit_req_zone 用来限制单位时间内的请求数,即速率限制。配置的意思是,限制单个IP访问的速度为 2r/s,因为Nginx的限流统计是基于毫秒的,我们设置的速度是 2r/s,转换一下就是500毫秒内单个IP只允许通过1个请求,从501ms开始才允许通过第2个请求。
第二种:控制并发数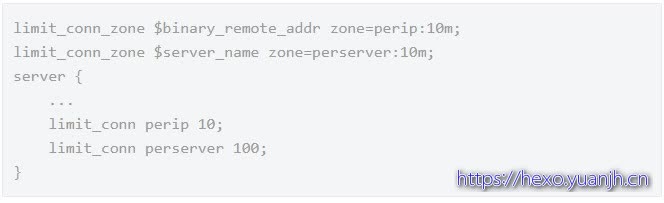
利用 limit_conn_zone 和 limit_conn 两个指令即可控制并发数,其中 limit_conn perip 10 表示限制单个 IP 同时最多能持有 10 个连接;limit_conn perserver 100 表示 server 同时能处理并发连接的总数为 100 个。
注意:只有当 request header 被后端处理后,这个连接才进行计数。
应用层限流
比如在服务器端通过限流算法实现限流,或者IP 黑名单等。
基于限流粒度分类
单机限流
现状的系统基本上都是分布式架构,单机的模式已经很少了,这里说的单机限流更加准确一点的说法是单服务节点限流。单机限流是指请求进入到某一个服务节点后超过了限流阈值,服务节点采取了一种限流保护措施。
分布式限流
分布式限流狭义的说法是在接入层实现多节点合并限流,比如NGINX+redis,分布式网关等,广义的分布式限流是多个节点(可以为不同服务节点)有机整合,形成整体的限流服务。
单机限流防止流量压垮服务节点,缺乏对整体流量的感知。分布式限流适合做细粒度不同的限流控制,可以根据场景不同匹配不同的限流规则。与单机限流最大的区别,分布式限流需要中心化存储,常见的使用redis实现。
常见的2种方式,一种是基于Redis做分布式限流,另一种类似于Sentinel分布式限流。
基于限流算法分类
计数器
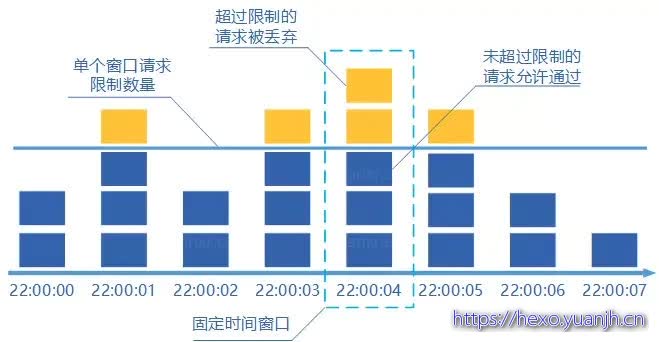
计数器算法主要是通过统计一段时间内的请求次数,当达到上限之后,剩下的请求则被丢弃或者做其他处理,当周期结束时则计数清零。例如:限制一分钟内请求次数60次,则在一分钟之内,每次请求,计数加一,当计数达到60之后的请求做其他处理。一分钟之后计数清零。
计数器算法的实现比较简单,但这个算法有时会让通过请求量允许为限制的两倍。就说上面那个列子,假如在第一个一分钟的最后1秒收到了60个请求,之后计数清零,下一个一分钟的第一秒又收到了60个请求,这样看来就是在 2 秒中收到了120个请求。
简单点实现,例如限制1秒请求1000次,则可以通过redis的incr命令,key则为当前的时间(到秒),计算一秒内的请求次数,当value大于1000时,其余的请求丢弃。(这种方式并不严谨,比如前秒尾部1000,后秒头部1000,则1秒内实际2000了)。
漏桶算法
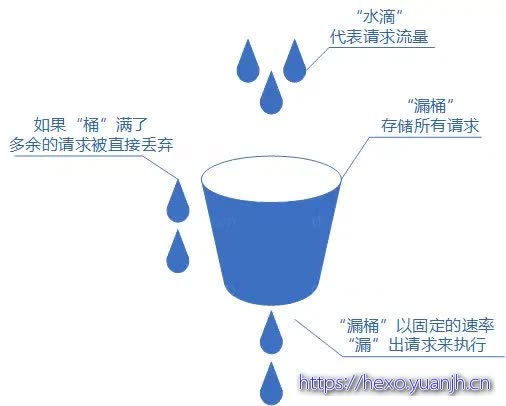
漏桶算法这个名字就很形象,算法内部有一个容器,类似生活用到的漏斗,当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。不管服务调用方多么不稳定,通过漏桶算法进行限流,每10毫秒处理一次请求。因为处理的速度是固定的,请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在桶里,既然是个桶,肯定是有容量上限,如果桶满了,那么新进来的请求就丢弃。
在算法实现方面,可以准备一个队列,用来保存请求,另外通过一个线程池来定期从队列中获取请求并执行,可以一次性获取多个并发执行。
漏桶算法的缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。
令牌桶算法
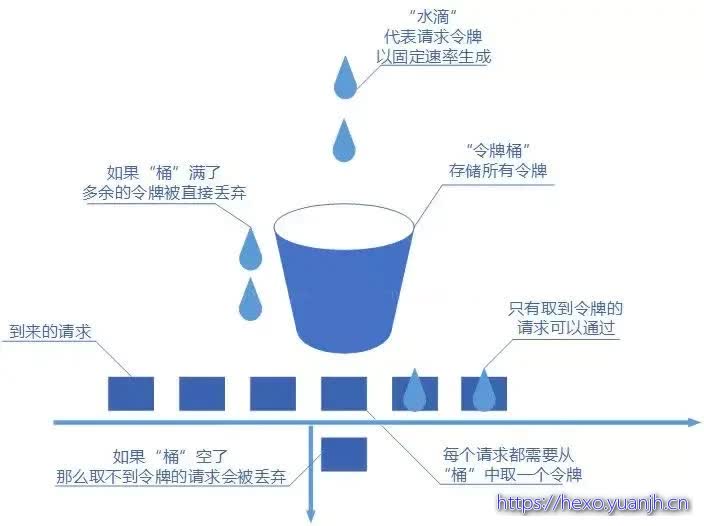
令牌桶算法和漏桶算法效果一样但方向相反的算法。系统会按固定的时间往桶里面添加令牌,如果桶已经满了就不再加。新请求来临时,会各自拿走一个令牌,如果没有令牌可拿了就阻塞或者做其他处理。这样即使短时间内突然访问量增加,也会在令牌用完之后才会做其他处理。
令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
参考
高并发系统下的限流方案:https://blog.csdn.net/suifeng629/article/details/103386587
6种常见的限流方案:https://blog.csdn.net/wangxy_job/article/details/106313398
常见限流方案设计与实现:https://www.jianshu.com/p/aaa249703e7b
程序员必知的几种限流方案:https://blog.csdn.net/javachengzi/article/details/113343409
架构设计和高并发系列
读书_大型网站技术架构01_李智慧
读书_大型网站技术架构02_李智慧
读书_大型网站技术架构03_李智慧
读书_高并发设计40问之一基础
读书_高并发设计40问之二数据库
读书_高并发设计40问之三缓存
读书_高并发设计40问之四消息队列
读书_高并发设计40问之五分布式服务
读书_w3c架构师01通用设计与方法论
读书_w3c架构师02典型架构实践
读书_w3c架构师03数据库与缓存
分布式事务
高并发之缓存
高并发之降级
高并发之限流
数据库_读写分离
消息队列_01消息队列入门
消息队列_02rabbitMQ入门
消息队列_03rabbitMQ安装和使用