Web缓存是用于临时存储(缓存)Web文档(如HTML页面和图像),以减少服务器延迟的一种信息技术。Web缓存系统会保存下通过这套系统的文档的副本;如果满足某些条件,则可以由缓存满足后续请求。
缓存的作用
减少网络带宽消耗:当Web缓存副本被使用时,只会产生极小的网络流量,可以有效的降低运营成本。
降低服务器压力:给网络资源设定有效期之后,用户可以重复使用本地的缓存,减少对源服务器的请求,间接降低服务器的压力。同时,搜索引擎的爬虫机器人也能根据过期机制降低爬取的频率,也能有效降低服务器的压力。
减少网络延迟,加快页面打开速度:带宽对于个人网站运营者来说是十分重要,缓存的使用能够明显加快页面打开速度,达到更好的体验。
web缓存有哪些?
数据库缓存:避免频繁的数据库查询,将查询的数据放入内存中,下次从内存中直接返回。
服务器缓存:服务器缓存一些经常会被用的资源,当多个用户访问时,因为他们共同需要访问的资源已经被缓存了,可以有效降低服务器压力。
浏览器缓存:缓存一些最近用到的图片,数据,页面等,提高网页打开速度。
缓存特征
缓存的特征
命中率 = 命中数 / (命中数+ 没有命中数)
命中率越高 , 说明使用缓存的收益越好 , 应用性能越好, 响应的时间越短 , 吞吐量越高 ,抗并发的能力越强
最大元素(空间)
代表缓存中可以存放的最大元素的数量 , 一旦缓存中元素的数量超过最大空间 ,是指缓存数据所在空间超过最大支持的空间, 将会触发清空策略 . 根据不同的场景合理的设置最大元素值, 可以在一定程度上提高缓存的命中率, 从而更有效的使用缓存 .
redis持久化策略
首先,redis支持RDB(默认)和AOF两种持久化策略。
a) RDB:Redis Database。RDB是Redis默认的持久化方式。每隔必定的时间周期就将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。经过配置文件中的save参数能够设置生成快照的时间周期。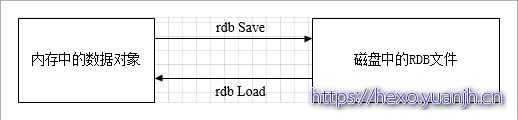
RDB的优缺点:
1 | 优势: |
b) AOF:Append Only File。将Redis每次执行的写命令记录到单独的日志文件中,当重启Redis时,会从持久化的日志文件中从新恢复数据。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。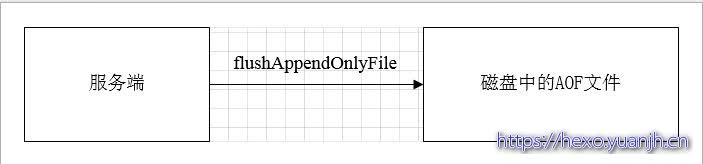
AOF优缺点:
1 | 优势: |
c) 对RDB和AOF二者进行对比:
若是同时配置了RDB和AOF,则优先加载AOF。
1 | 1、AOF文件比RDB更新频率高,优先使用AOF还原数据; |
缓存回收策略(何时回收)
1.基于空间
基于空间指的是缓存设置了存储空间大小,如20MB,当缓存数据达到设置的空间上限时,则按照策略淘汰数据。(redis.conf maxmemory)
2.基于容量
基于容量指的是缓存设置了数量条目限制。当缓存的条目超过数量上限时,则按照策略淘汰数据。
3.基于时间
基于时间分为两类:
TTL(Time To Live):缓存的存活时间,当缓存数据被放入存活到一定时间段时,会自动到期移除。
TTI(Time To Idle):缓存的空闲期,即缓存经过一定时间没有被访问,就会自动被移除。
4.基于Java引用
这里主要指的是软引用和弱引用。
软引用:当JVM在垃圾回收时,如果内存不足,则会回收软引用指向的对象内存空间。
弱引用:当JVM在垃圾回收时,发现了弱引用,则会回收弱引用指向的对象内存空间。相比软引用,它不会判断内存是否够用,都会回收空间。
5.基于算法
常见的缓存淘汰算法有如下:
FIFO:先进先出算法。即最先放入的数据最先被淘汰。
LRU:最近最少被使用算法。上次使用时间距离现在最久的那个数据被淘汰。
LFU:最不常用算法。即一定时间段内使用次数(频率)最少的那个被淘汰。
过时键的删除策略
使用过Redis的都知道,Redis是key-value的数据库,咱们能够设置redis缓存中key的过时时间,一般采用如下三种过时键的删除策略,Redis中同时使用惰性过时和按期过时两种过时策略。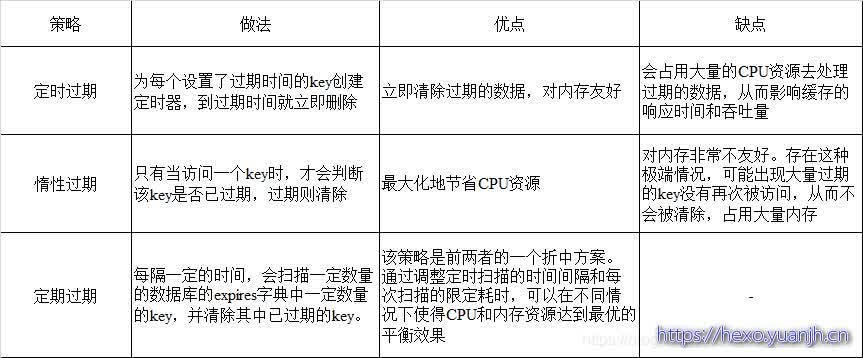
缓存淘汰策略(如何回收,逻辑上在何时回收之后,二者有重叠)
Redis的内存淘汰策略是指用于缓存的内存不足时,怎么处理须要新写入且须要申请额外空间的数据。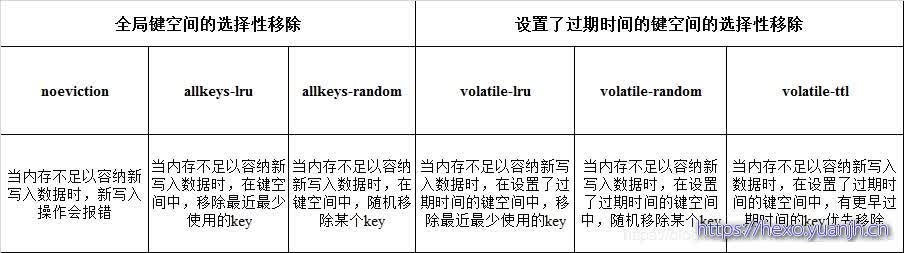
FIFO first in first out先进先出
最先进入缓存空间的数据 , 在缓存不够的情况下, 或者缓存数量超过最大元素的情况下 ,会被优先清除掉 , 以腾出空间缓存新的数据, 这个清除算法主要是比较缓存元素的创建时间.在数据实时性要求场景下可以使用该策略 ,优先保证最新数据可用 .
LFU least frequently used最少使用策略
该策略是根据元素的使用次数来判断 , 无论缓存元素是否过期 , 清除使用次数最少的元素来释放空间.这个策略的算法主要比较元素的命中次数.在保证高频数据有效性的场景下 , 可以使用此类策略.
LRU Least Recently Used 最近最少使用策略
它是指无论是否过期 , 根据元素最后一次被使用的时间戳 , 清除最远使用时间戳的元素 , 这个策略的算法主要比较元素的最近一次被 get使用时间, 在热点数据的场景下较适用 , 优先保证热点数据的有效性 .
过期时间
根据过期时间来判断 , 清理过期时间最长的元素, 还可以根据过期时间来判读, 来清理最近要过期的元素 .
随机
随机清理元素
缓存相关问题
缓存一致性问题
一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。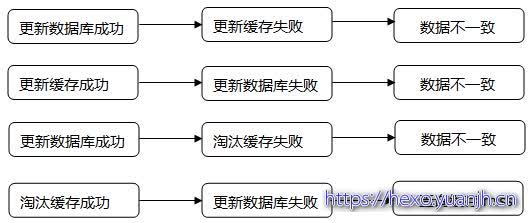


缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
导致问题的原因是同一时间查,同一时间写缓存,导致并发下缓存也没用,所以考虑使用单线程等方法将写缓存保证只有一个去查了写,其他的使用缓存。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
1.使用互斥锁(mutex key)
2. “提前”使用互斥锁(mutex key):
3. “永远不过期”:
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。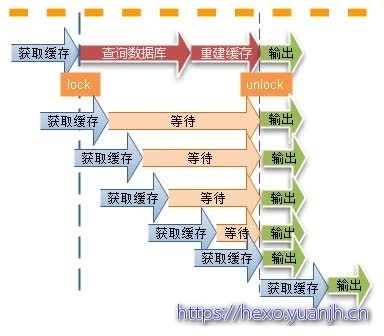
缓存穿透问题
在高并发场景下,如果某一个key被高并发访问,没有被命中,出于对容错性考虑,会尝试去从后端数据库中获取,从而导致了大量请求达到数据库,而当该key对应的数据本身就是空的情况下,这就导致数据库中并发的去执行了很多不必要的查询操作,从而导致巨大冲击和压力。
可以通过下面的几种常用方式来避免缓存传统问题:
01,缓存空对象。
为了避免大量占用空间,过期时间会很短,最长不超过五分钟。
02,单独过滤处理,
布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。比较适合命中不高,但是更新不频繁的数据。
缓存的雪崩现象
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
关键字:** 时间岔开**,确保大家的key不会落在同一个expire点上。
缓存颠簸问题
缓存的颠簸问题,有些地方可能被成为“缓存抖动”,可以看做是一种比“雪崩”更轻微的故障,但是也会在一段时间内对系统造成冲击和性能影响。一般是由于缓存节点故障导致。业内推荐的做法是通过一致性Hash算法来解决。
缓存的读写策略(todo)
Cache Aside策略
读请求
在读请求时,先查询缓存:1. 缓存中存在,直接返回;2. 缓存中不存在,查询数据库,然后将结果写入缓存。
写请求
在写请求时,先更新数据库,然后直接删除对应缓存。
问题:写请求时,可以先删除缓存,后更新数据库吗?
答案:不能。可能会造成数据不一致问题。如:请求 1 对数据 A 发起写请求,先删除数据 A 的缓存,这时请求 2 对数据 A 发起读请求,由于缓存不存在,会先读取数据库中的 A 的值,然后写入缓存;之后请求1 更新数据库(此时数据 A 在缓存中的值和数据库中的值已经不一致了)。那么当下次对数据 A 的读请求来临时,由于缓存中存在数据 A ,直接返回,但是此时缓存中 A 的数据和数据库中 A 的数据不一致。
问题:写请求时,先更新数据库,后删除缓存就一定没有问题吗?
答案:不一定,但大概率没有问题。如:请求 1 对数据 A 发起读请求,缓存中不存在,这时请求 2 对数据 A 发起写请求,先更新数据库中的 A 的值,然后删除缓存;之后请求1 将自己读取到的数据写入缓存。这个时候数据 A 在缓存和数据库中的值也不一致了。但是由于缓存写入速度远高于数据库写入速度,请求 1 写入缓存一般比请求 2 写入数据库然后删除缓存先完成。
该模式适合读多的场景。
旁路缓存模式的缺点
第一次读取时肯定会先读取数据库。
解决方案:事先将热点数据载入缓存(缓存预热)。
写操作频繁时会频繁删除缓存中的数据,导致缓存命中率较低。
解决方案:1. 更新数据库的同时更新缓存,注意不是删除缓存,这通常需要加锁来保证这两个操作的原子性。适用于数据强一致性的场景。2. 更新数据库的同时更新缓存,并给缓存设置一个较短的存活时间,并且不需要加锁,但会出现数据不一致的问题。适用于可以接受短暂的数据不一致的场景。
Read/Write Through
Read/Write Through Pattern 译为读写穿透模式。该模式以缓存为主,数据库为辅。
读请求
和旁路缓存模式类似,先查询缓存:1. 缓存中存在,直接返回;2. 缓存中不存在,缓存服务自动从数据库中读取数据写入缓存,然后返回。
和旁路缓存模式的区别就是,旁路缓存模式是我们手动写入缓存,而读写穿透模式是自动从数据库中读取数据并写入缓存。
写请求
在写请求时,先查询缓存中存不存在:1. 不存在,直接写入数据库。2. 存在,先更新缓存,然后同步更新数据库。
Write Behind Pattern
Write Behind Pattern 又称 Write Back 。类似于前面的 Read/Write Through Pattern,都是以缓存为主,数据库为辅。主要策略如下:
读请求
和 Read/Write Through Pattern 一样。
写请求
在写请求时,先查询缓存中存不存在:1. 不存在,直接写入数据库。2. 存在,先更新缓存,然后异步批量更新数据库。
这种模式写性能非常好,因为都是直接写缓存,但问题是数据不是强一致性的,还可能会导致数据丢失。适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
缓存高可用
客户端方案
客户端方案就是在客户端配置多个缓存的节点,通过缓存写入和读取算法策略来实现分布式,从而提高缓存的可用性。
数据分片,主从,多副本
中间代理层
中间代理层方案就是在应用代码和缓存节点之间增加代理层,客户端所有的写入和读取的请求都通过代理层,而代理层中会内置高可用策略,帮助提升缓存系统的高可用。
业界也有很多中间代理层方案,比如 Facebook 的Mcrouter,Twitter 的Twemproxy,豌豆荚的Codis。它们的原理基本上可以由一张图来概括: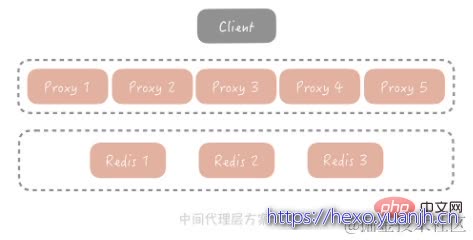
服务端方案
服务端方案就是redis 2.4版本后提出的Redis Sentinel方案。
Redis 在 2.4 版本中提出了 Redis Sentinel 模式来解决主从 Redis 部署时的高可用问题,它可以在主节点挂了以后自动将从节点提升为主节点,保证整体集群的可用性,整体的架构如下图所示: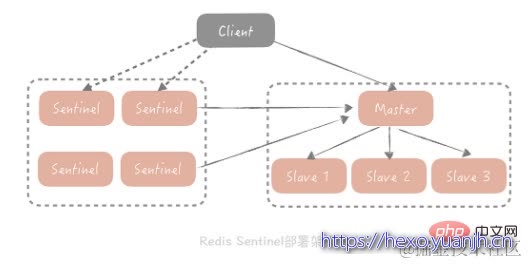
redis Sentinel 也是集群部署的,这样可以避免 Sentinel 节点挂掉造成无法自动故障恢复的问题,每一个 Sentinel 节点都是无状态的。
缓存命中率的影响因素(如何提高缓存命中率)
业务场景和业务需求
缓存适合 读多写少 的业务场景, 否则使用其意义不大,命中率会很低 .业务需求也决定了对实时性的要求, 直接影响到缓存的过期时间和更新策略,实时性要求越低就越适合缓存 .在相同 key 和相同请求数的情况下 ,缓存的时间越长, 命中率就会越高.
缓存的设计(粒度和策略)
通常情况下 , 缓存的粒度越小, 命中率就会越高.
缓存的容量和淘汰算法和架构
缓存的容量有限, 就容易引起缓存的失效和淘汰. 目前多少的缓存框架都使用了 LRU 这个算法 .同时缓存的技术选型也是很重要的 .比如采用应用内置的本地缓存,就容易出现单机瓶颈 , 而采用分布式缓存 ,它就更容易扩展, 所以要做好系统容量的规划 ,并考虑是否可以扩展 , 另外不同的缓存中间件, 其效率和稳定性都是有差异的.除此之外, 还有其他的一些会影响缓存命中率 , 比如某个缓存节点挂掉的时候 , 要避免缓存失效, 并最大程度的降低影响 . 比较典型的做法就是 一致性hash算法 , 或者通过节点冗余的方式来避免这个问题 .
缓存与应用的耦合度分类
分类为本地缓存和分布式缓存.
本地缓存(高耦合,快,无网络,容量小且不共享)
本地缓存是指缓存中的应用组件, 它最大的优点是应用和 cache , 是在同一个进程的内部, 请求缓存非常的快速.没有过多的网络开销等,在单应用中,不需要集群支持 , 各节点不需要互相通知的情景下, 适合使用本地缓存.
它的缺点也是显而易见的, 由于缓存和应用耦合度较高, 多个应用无法共享缓存 ,各个应用都需要单独维护自己的缓存 ,对内存也是一种浪费, 资源能节省就节省. 在实际实现中 , 都是同成员变量, 局部变量, 静态变量 来实现, 也还有一些框架 比如 Guava Cache
分布式缓存(耦合,慢,有网络,容量大共享)
它是指应用分离的缓存组件或服务, 最大的优点是自身是一个独立的应用 ,与本地应用是隔离的,多个应用可以直接共享缓存. 比如 常用的Redis
更新缓存 VS 淘汰缓存
更新缓存 VS 淘汰缓存
什么是更新缓存:数据不但写入数据库,还会写入缓存
什么是淘汰缓存:数据只会写入数据库,不会写入缓存,只会把数据淘汰掉
更新缓存的优点:缓存不会增加一次miss,命中率高
淘汰缓存的优点:简单
那到底是选择更新缓存还是淘汰缓存呢,主要取决于“更新缓存的复杂度”。
例如,上述场景,只是简单的把余额money设置成一个值,那么:
(1)淘汰缓存的操作为deleteCache(uid)
(2)更新缓存的操作为setCache(uid, money)
更新缓存的代价很小,此时更倾向于更新缓存,以保证更高的缓存命中率
如果余额是通过很复杂的数据计算得出来的,更新缓存的代价很大,此时我们应该更倾向于淘汰缓存。
however,淘汰缓存操作简单,并且带来的副作用只是增加了一次cache miss,建议作为通用的处理方式。
缓存和数据库的操作时序
OK,当写操作发生时,假设淘汰缓存作为对缓存通用的处理方式,又面临两种抉择:
(1)先写数据库,再淘汰缓存
(2)先淘汰缓存,再写数据库
究竟采用哪种时序呢?
对于一个不能保证事务性的操作,一定涉及“哪个任务先做,哪个任务后做”的问题,解决这个问题的方向是:
如果出现不一致,谁先做对业务的影响较小,就谁先执行。
由于写数据库与淘汰缓存不能保证原子性,谁先谁后同样要遵循上述原则。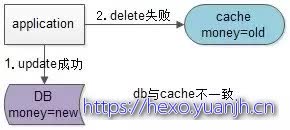
假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。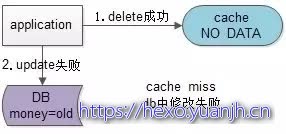
假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。
结论:数据和缓存的操作时序,结论是清楚的:先淘汰缓存,再写数据库。
缓存和数据库架构简析
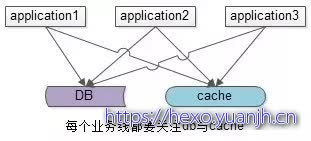
上述缓存架构有一个缺点:业务方需要同时关注缓存与DB,有没有进一步的优化空间呢?有两种常见的方案,一种主流方案,一种非主流方案(一家之言,勿拍)。
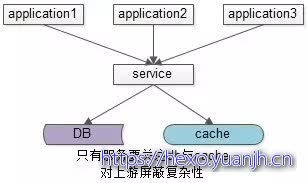
主流优化方案是服务化:加入一个服务层,向上游提供帅气的数据访问接口,向上游屏蔽底层数据存储的细节,这样业务线不需要关注数据是来自于cache还是DB。

非主流方案是异步缓存更新:业务线所有的写操作都走数据库,所有的读操作都总缓存,由一个异步的工具来做数据库与缓存之间数据的同步,具体细节是:
(1)要有一个init cache的过程,将需要缓存的数据全量写入cache
(2)如果DB有写操作,异步更新程序读取binlog,更新cache
在(1)和(2)的合作下,cache中有全部的数据,这样:
(a)业务线读cache,一定能够hit(很短的时间内,可能有脏数据),无需关注数据库
(b)业务线写DB,cache中能得到异步更新,无需关注缓存
这样将大大简化业务线的调用逻辑,存在的缺点是,如果缓存的数据业务逻辑比较复杂,async-update异步更新的逻辑可能也会比较复杂。
参考
缓存在高并发场景下的常见问题:https://www.cnblogs.com/dinglang/p/6133501.html
高并发缓存处理之——缓存穿透的几种形式及解决方案:https://blog.csdn.net/doujinlong1/article/details/82024340
Java 高并发之缓存;https://blog.csdn.net/Andy86869/article/details/79781272
谈谈高并发之缓存:https://www.wangt.cc/2021/01/谈谈高并发之缓存/
高并发场景下缓存处理的一些思路:https://blog.csdn.net/wnvalentin/article/details/92761720
缓存架构设计细节二三事:https://mp.weixin.qq.com/s/CY4jntpM7VNkBrz1FKRsOw
java高并发系统设计之缓存篇;https://www.php.cn/java/base/461021.html
常见缓存读写策略:https://blog.csdn.net/qq_39340792/article/details/112383445
缓存的使用姿势(二):缓存如何做到高可用?:https://www.jianshu.com/p/5292ae041c81
高并发系统三大利器:限流、降级、缓存:https://baijiahao.baidu.com/s?id=1684500581792415737&wfr=spider&for=pc
redis持久化机制、删除策略、淘汰策略、数据一致性问题及布隆过滤器详解:https://www.shangmayuan.com/a/79b3ffdf51d2499ba2bf5a33.html
架构设计和高并发系列
读书_大型网站技术架构01_李智慧
读书_大型网站技术架构02_李智慧
读书_大型网站技术架构03_李智慧
读书_高并发设计40问之一基础
读书_高并发设计40问之二数据库
读书_高并发设计40问之三缓存
读书_高并发设计40问之四消息队列
读书_高并发设计40问之五分布式服务
读书_w3c架构师01通用设计与方法论
读书_w3c架构师02典型架构实践
读书_w3c架构师03数据库与缓存
分布式事务
高并发之缓存
高并发之降级
高并发之限流
数据库_读写分离
消息队列_01消息队列入门
消息队列_02rabbitMQ入门
消息队列_03rabbitMQ安装和使用