12,缓存:数据库成为瓶颈后,动态数据的查询要如何加速?
什么是缓存:位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存
缓存作为一种常见的 空间换时间的性能优化手段,
- 缓存案例(略)
- 缓存与缓冲区
缓冲区则是一块临时存储数据的区域,这些数据后面会被传输到其他设备上。 缓冲区更像「消息队列篇」中即将提到的消息队列,用以弥补高速设备和低速设备通信时的速度差。缓存分类
常见的缓存主要就是静态缓存、分布式缓存和热点本地缓存这三种。
缓存的不足
通过了解上面的内容,你不难发现,缓存的主要作用是提升访问速度,从而能够抗住更高的并发。那么,缓存是不是能够解决一切问题?显然不是。事物都是具有两面性的,缓存也不例外,我们要了解它的优势的同时也需要了解它有哪些不足,从而扬长避短,将它的作用发挥到最大。
首先,缓存比较适合于读多写少的业务场景,并且数据最好带有一定的热点属性。 这是因为缓存毕竟会受限于存储介质不可能缓存所有数据,那么当数据有热点属性的时候才能保证一定的缓存命中率。比如说类似微博、朋友圈这种 20% 的内容会占到 80% 的流量。所以,一旦当业务场景读少写多时或者没有明显热点时,比如在搜索的场景下,每个人搜索的词都会不同,没有明显的热点,那么这时缓存的作用就不明显了。
其次,缓存会给整体系统带来复杂度,并且会有数据不一致的风险。 当更新数据库成功,更新缓存失败的场景下,缓存中就会存在脏数据。对于这种场景,我们可以考虑使用较短的过期时间或者手动清理的方式来解决。
再次,之前提到缓存通常使用内存作为存储介质,但是内存并不是无限的。 因此,我们在使用缓存的时候要做数据存储量级的评估,对于可预见的需要消耗极大存储成本的数据,要慎用缓存方案。同时,缓存一定要设置过期时间,这样可以保证缓存中的会是热点数据。
最后,缓存会给运维也带来一定的成本, 运维需要对缓存组件有一定的了解,在排查问题的时候也多了一个组件需要考虑在内。
一种设计思想
缓存不仅仅是一种组件的名字,更是一种设计思想,你可以认为任何能够加速读请求的组件和设计方案都是缓存思想的体现。而这种加速通常是通过两种方式来实现:
使用更快的介质,比方说课程中提到的内存;
缓存复杂运算的结果,比方说前面 TLB 的例子就是缓存地址转换的结果。
那么,当你在实际工作中碰到“慢”的问题时,缓存就是你第一时间需要考虑的
13,缓存的使用姿势 1:如何选择缓存的读写策略?
今天,我们先讲讲缓存的读写策略。你可能觉得缓存的读写很简单,只需要优先读缓存,缓存不命中就从数据库查询,查询到了就回种缓存。实际上,针对不同的业务场景,缓存的读写策略也是不同的。
Cache Aside(旁路缓存)策略
这个策略数据 以数据库中的数据为准,缓存中的数据是按需加载的 。它可以分为读策略和写策略,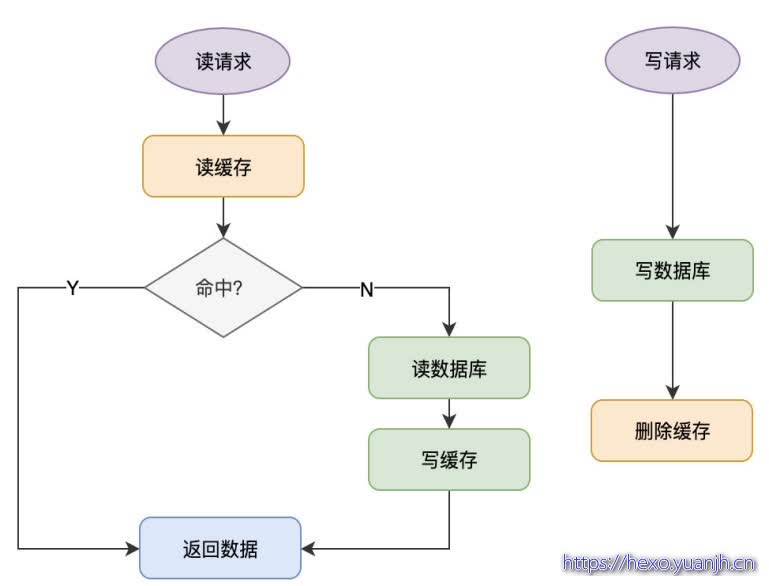
读策略的步骤是:
从缓存中读取数据;
如果缓存命中,则直接返回数据;
如果缓存不命中,则从数据库中查询数据;
查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
更新数据库中的记录;
删除缓存记录。
你也许会问了,在写策略中,能否先删除缓存,后更新数据库呢? 答案是不行的, 因为这样也有可能出现缓存数据不一致的问题
那么像 Cache Aside 策略这样先更新数据库,后删除缓存就没有问题了吗?其实在理论上还是有缺陷的。
不过这种问题出现的几率并不高,原因是缓存的写入通常远远快于数据库的写入,
Cache Aside 策略是我们日常开发中最经常使用的缓存策略不过我们在使用时也要学会依情况而变。 比如说当新注册一个用户,按照这个更新策略,你要写数据库,然后清理缓存(当然缓存中没有数据给你清理)。可当我注册用户后立即读取用户信息,并且数据库主从分离时 ,会出现因为主从延迟所以读不到用户信息的情况。
而解决这个问题的办法 恰恰是在插入新数据到数据库之后写入缓存,这样后续的读请求就会从缓存中读到数据了。并且因为是新注册的用户,所以不会出现并发更新用户信息的情况 。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。 如果业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。
Read/Write Through(读穿 / 写穿)策略
这个策略的核心原则是用户只与缓存打交道,由缓存和数据库通信,写入或者读取数据 。
Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做 Write Miss(写失效)。
一般来说,我们可以选择两种 Write Miss 方式:
Write Allocate(按写分配)
做法是写入缓存相应位置,再由缓存组件同步更新到数据库中;
No-write allocate(不按写分配)
做法是不写入缓存中,而是直接更新到数据库中
在 Write Through 策略中,一般选择 No-write allocate 方式,原因是无论采用哪种 Write Miss 方式,我们都需要同步将数据更新到数据库中,而No-write allocate 方式相比 Write Allocate 还减少了一次缓存的写入,能够提升写入的性能。
Read Through 策略就简单一些,先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据。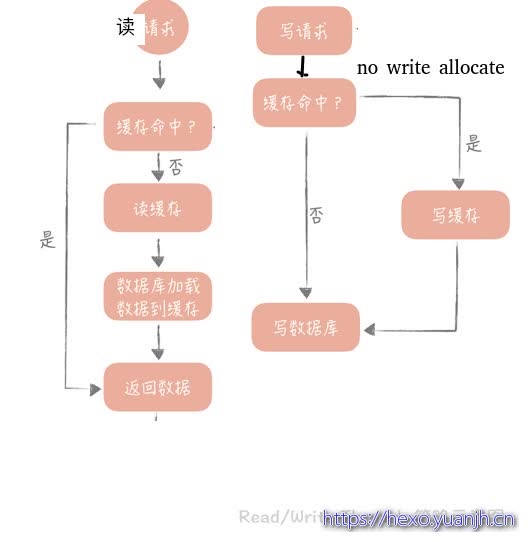
Read Through/Write Through 策略的特点是 由缓存节点而非用户来和数据库打交道 **,开发过程中相比 Cache Aside 策略要少见一些,原因是我们常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库,或者自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略,比如说在上一节中提到的本地缓存 Guava Cache 中的 Loading Cache 就有 Read Through 策略的影子。
我们看到 Write Through 策略中写数据库是同步的** ,这对于性能来说会有比较大的影响,因为相比于写缓存,同步写数据库的延迟就要高很多了。那么我们可否异步地更新数据库?这就是我们接下来要提到的 Write Back 策略。
Write Back(写回)策略
策略的核心思想是 在写入数据时只写入缓存,并且把缓存块儿标记为 「脏」 的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。
其实这种策略不能被应用到我们常用的数据库和缓存的场景中,它是计算机体系结构中的设计,比如我们在向磁盘中写数据时采用的就是这种策略。无论是操作系统层面的 Page Cache,还是日志的异步刷盘,亦或是消息队列中消息的异步写入磁盘,大多采用了这种策略。因为这个策略在性能上的优势毋庸置疑,它避免了直接写磁盘造成的随机写问题,毕竟写内存和写磁盘的随机 I/O 的延迟相差了几个数量级呢。
但因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏块儿数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
当然,你依然可以在一些场景下使用这个策略,在使用时,我想给你的落地建议是: 你在向低速设备写入数据的时候,可以在内存里先暂存一段时间的数据,甚至做一些统计汇总,然后定时地刷新到低速设备上。比如说,你在统计你的接口响应时间的时候,需要将每次请求的响应时间打印到日志中,然后监控系统收集日志后再做统计。但是如果每次请求都打印日志无疑会增加磁盘 I/O,那么不如把一段时间的响应时间暂存起来,经过简单的统计平均耗时,每个耗时区间的请求数量等等,然后定时地,批量地打印到日志中。
14,缓存的使用姿势 2:缓存如何做到高可用?
客户端方案
在客户端方案中,你需要关注缓存的写和读两个方面:
写入数据时,需要把被写入缓存的数据分散到多个节点中,即进行数据分片;
读数据时,可以利用多组的缓存来做容错,提升缓存系统的可用性。关于读数据,这里可以使用主从和多副本两种策略,两种策略是为了解决不同的问题而提出的。
缓存数据如何分片
单一的缓存节点受到机器内存、网卡带宽和单节点请求量的限制,不能承担比较高的并发,因此我们考虑将数据分片,依照分片算法将数据打散到多个不同的节点上,每个节点上存储部分数据。
这样在某个节点故障的情况下,其他节点也可以提供服务,保证了一定的可用性。这就好比不要把鸡蛋放在同一个篮子里,这样一旦一个篮子掉在地上,摔碎了,别的篮子里还有没摔碎的鸡蛋,不至于一个不剩。
用一致性 Hash 算法可以很好地解决增加和删减节点时,命中率下降的问题。不过,事物总有两面性。虽然这个算法对命中率的影响比较小,但它还是存在问题:缓存节点在圆环上分布不平均,会造成部分缓存节点的压力较大;当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成压力。容易造成链式崩溃,A崩溃导致B无法承载而崩溃,继而触发C也崩溃。可以在一致性 Hash 算法中引入虚拟节点的概念。
一致性 Hash 算法的脏数据问题。思考下,为什么会产生脏数据呢?
解决办法:使用一致性 Hash 算法时一定要设置缓存的过期时间,
中间代理层方案
虽然客户端方案已经能解决大部分的问题,但是只能在单一语言系统之间复用。例如微博使用 Java 语言实现了这么一套逻辑,我使用 PHP 就难以复用,需要重新写一套,很麻烦。 而中间代理层的方案就可以解决这个问题。
服务端方案
Redis 在 2.4 版本中提出了 Redis Sentinel 模式来解决主从 Redis 部署时的高可用问题,它可以在主节点挂了以后自动将从节点提升为主节点,保证整体集群的可用性
15,缓存的使用姿势 3:缓存穿透了怎么办?
对于缓存来说,命中率是它的生命线。
什么是缓存穿透
那如何解决缓存穿透呢?一般来说我们会有两种解决方案: 回种空值以及使用布隆过滤器。
回种空值虽然能够阻挡大量穿透的请求,但如果有大量获取未注册用户信息的请求,缓存内就会有有大量的空值缓存,也就会浪费缓存的存储空间,如果缓存空间被占满了,还会剔除掉一些已经被缓存的用户信息反而会造成缓存命中率的下降。
所以这个方案,我建议你在使用的时候应该评估一下缓存容量是否能够支撑。 如果需要大量的缓存节点来支持,那么就无法通过通过回种空值的方式来解决,这时你可以考虑使用布隆过滤器。
布隆过滤器主要有两个缺陷:
它在判断元素是否在集合中时是有一定错误几率的,比如它会把不是集合中的元素判断为处在集合中;
不支持删除元素。
总结
回种空值是一种最常见的解决思路,实现起来也最简单,如果评估空值缓存占据的缓存空间可以接受,那么可以优先使用这种方案;
布隆过滤器会引入一个新的组件,也会引入一些开发上的复杂度和运维上的成本。所以只有在存在海量查询数据库中,不存在数据的请求时才会使用,在使用时也要关注布隆过滤器对内存空间的消耗;
对于极热点缓存数据穿透造成的狗桩效应,可以通过设置分布式锁或者后台线程定时加载的方式来解决。
除此之外,你还需要了解的是,数据库是一个脆弱的资源,它无论是在扩展性、性能还是承担并发的能力上,相比缓存都处于绝对的劣势,所以我们解决缓存穿透问题的 核心目标在于减少对于数据库的并发请求。
16,CDN:静态资源如何加速?
静态资源访问的关键点是 就近访问。
了解了 CDN 对静态资源进行加速的原理和使用的核心技术,这里你需要了解的重点有以下几点:
DNS 技术是 CDN 实现中使用的核心技术,可以将用户的请求映射到 CDN 节点上;
DNS 解析结果需要做本地缓存,降低 DNS 解析过程的响应时间;
GSLB 可以给用户返回一个离着他更近的节点,加快静态资源的访问速度。
加餐,数据的迁移应该如何做?(略)
架构设计和高并发系列
读书_大型网站技术架构01_李智慧
读书_大型网站技术架构02_李智慧
读书_大型网站技术架构03_李智慧
读书_高并发设计40问之一基础
读书_高并发设计40问之二数据库
读书_高并发设计40问之三缓存
读书_高并发设计40问之四消息队列
读书_高并发设计40问之五分布式服务
读书_w3c架构师01通用设计与方法论
读书_w3c架构师02典型架构实践
读书_w3c架构师03数据库与缓存
分布式事务
高并发之缓存
高并发之降级
高并发之限流
数据库_读写分离
消息队列_01消息队列入门
消息队列_02rabbitMQ入门
消息队列_03rabbitMQ安装和使用