其他辅助组件相关问题
Config
对于微服务还不是很多的时候,各种服务的配置管理起来还相对简单,但是当成百上千的微服务节点起来的时候,服务配置的管理变得会复杂起来。
分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。在Spring Cloud中,有分布式配置中心组件Spring Cloud Config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在Cpring Cloud Config 组件中,分两个角色,一是Config Server,二是Config Client。
Config Server用于配置属性的存储,存储的位置可以为Git仓库、SVN仓库、本地文件等,Config Client用于服务属性的读取。
Spring cloud config的安全保护
生产环境中我们的配置中心肯定是不能随随便便被人访问的,我们可以加上适当的保护机制,由于微服务是构建在 Spring Boot 之上,所以整合 Spring Security是最方便的方式。
1、在 springcloud config server 项目添加依赖:
1 | <dependency> |
2、在 springcloud config server 项目的 application.properties 中配置用户名密码:
1 | spring.security.user.name=wkcto |
3、在 springcloud config client 上 bootstrap.properties 配置用户名和密码:
1 | spring.cloud.config.username=wkcto |
Bus
在(5)Spring Cloud Config中,我们知道的配置文件可以通过Config Server存储到Git等地方,通过Config Client进行读取,但是我们的配置文件不可能是一直不变的,当我们的配置文件放生变化的时候如何进行更新?
一种最简单的方式重新一下Config Client进行重新获取,但Spring Cloud绝对不会让你这样做的,Spring Cloud Bus正是提供一种操作使得我们在不关闭服务的情况下更新我们的配置。
SpringCloud Config Refresh
SpringCloud学习系列之五—–配置中心(Config)和消息总线(Bus)完美使用版:https://blog.csdn.net/qazwsxpcm/article/details/88803428
不使用Spring Cloud Bus获取配置信息流程图: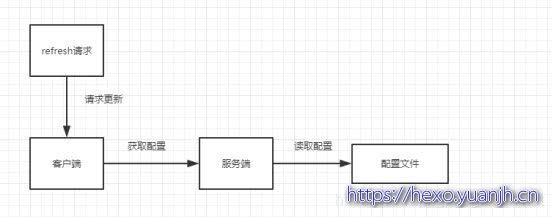
使用Spring Cloud Bus获取配置信息流程图: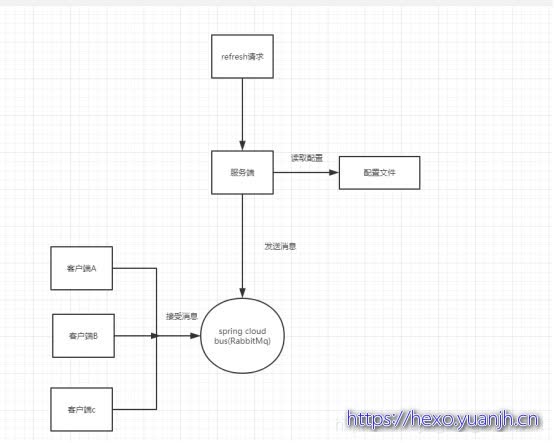
其他问题
请求瓶颈相关三个问题
问题一:Zuul端转发请求的线程数与后端Service处理请求的线程数不一致,它们之间是什么关系呢?
问题二:Zuul为什么会在Serivce正常的情况下出现服务熔断呢?
问题三:为什么后端Service的并发线程数量达到200后没有随并发用户数的进一步增大而增大呢?
下面,我们按照由易到难的顺序进行剖析这些问题,探究Zuul如何进行调优。
问题三
问题剖析
为什么后端Service的并发线程数量达到200后没有随并发用户数的增大而增大呢?
SpringBoot默认使用8.5版本的Tomcat作为内嵌的Web容器。因此Zuul或Service接收到的请求时,都是由Tomcat中Connector的线程池数量决定,也就是worker线程数。
Tomcat中默认的worker线程数的最大值为200(官方文档中有说明),可以在yaml中增加server.tomcat.max-threads属性来设置worker线程数的最大值。
配置调优
因此,问题三的解决方案是在Zuul端和Service端的yaml中增加如下配置:
1 | #增大tomcat中worker的最大线程数量 |
问题二
问题剖析
为什么Zuul会在Serivce正常的情况下出现服务熔断呢?
默认情况下,当某微服务请求的失败比例大于50%(且请求总数大于20次)时,会触发Zuul中断路器的开启,后续对该微服务的请求会发生熔断,直到微服务的访问恢复正常。在Serivce正常时出现服务熔断,有可能是请求端或网络的问题,但通常是由于hystrix的信号量小于Zuul处理请求的线程数造成的。Zuul默认使用semaphores信号量机制作为Hystrix的隔离机制,当Zuul对后端微服务的请求数超过最大信号量数时会抛出异常,通过配置zuul.semaphore.max-semaphores可以设置Hystrix中的最大信号量数。也就是说zuul.semaphore.max-semaphores设置的值小于server.tomcat.max-threads,会导致hystrix的信号量无法被acquire,继而造成服务熔断。
问题解决
确保zuul.semaphore.max-semaphores属性值大于server.tomcat.max-threads。
问题一
问题剖析
Zuul端转发请求的线程数与后端Service处理请求的线程数之间是什么关系呢?
Zuul集成了Ribbon与Hystrix,当使用Service ID配置Zuul的路由规则时,Zuul会通过Ribbon实现负载均衡,通过Hystrix实现服务熔断。这个过程可以理解为这三个动作:Zuul接收请求,Zuul转发请求,Service接收请求。其中第一个和第三个动作,由问题三可知,分别由Zuul和Service的server.tomcat.max-threads属性配置。
第二个动作使用了Ribbon实现负载均衡,通过设置ribbon.MaxConnectionsPerHost属性(默认值50)和ribbon.MaxTotalConnections属性(默认值200)可以配置Zuul对后端微服务的最大并发请求数,这两个参数分别表示单个后端微服务实例请求的并发数最大值和所有后端微服务实例请求并发数之和的最大值。
第二个动作同时使用Hystrix实现熔断,Zuul默认使用semaphores信号量机制作为Hystrix的隔离机制,当Zuul对后端微服务的请求数超过最大信号量数时会抛出异常,通过配置zuul.semaphore.max-semaphores可以设置Hystrix中的最大信号量数。
因此通过配置上述三个属性可以增加每个路径下允许转发请求的线程数。这三个属性的关系用下图粗略的进行表示: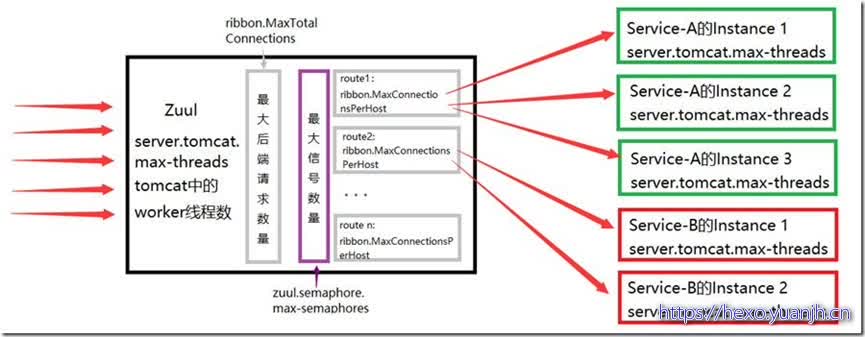

Zuul端转发请求的线程数与Service端处理请求的线程数的关系:
限制一:单点部署的Zuul同时处理的最大线程数为server.tomcat.max-threads;
限制二:向所有后端Service同时转发的请求数的最大值为server.tomcat.max-threads、ribbon.MaxTotalConnections和zuul.semaphore.max-semaphores的最小值,这也是所有后端Service能够同时处理请求的最大并发线程数;
限制三:单个后端Service能同时处理的最大请求数为其server.tomcat.max-threads和ribbon.MaxConnectionsPerHost中的最小值。
注意:很多博客提到使用zuul.host.maxTotalConnections与zuul.host.maxPerRouteConnections这两个参数。经过查阅和实践,这两个参数在使用Service ID配置Zuul的路由规则时无效,只适用于指定微服务的url配置路由的情景。
性能优化之道
性能优化之道】每秒上万并发下的Spring Cloud参数优化实战:https://blog.csdn.net/forezp/article/details/83999975
只要涉及到了重试,那么必须上接口的幂等性保障机制。
否则的话,试想一下,你要是对一个接口重试了好几次,结果人家重复插入了多条数据,该怎么办呢?
其实幂等性保证本身并不复杂,根据业务来,常见的方案:
可以在数据库里建一个唯一索引,插入数据的时候如果唯一索引冲突了就不会插入重复数据
或者是通过redis里放一个唯一id值,然后每次要插入数据,都通过redis判断一下,那个值如果已经存在了,那么就不要插入重复数据了。
类似这样的方案还有一些。总之,要保证一个接口被多次调用的时候,不能插入重复的数据。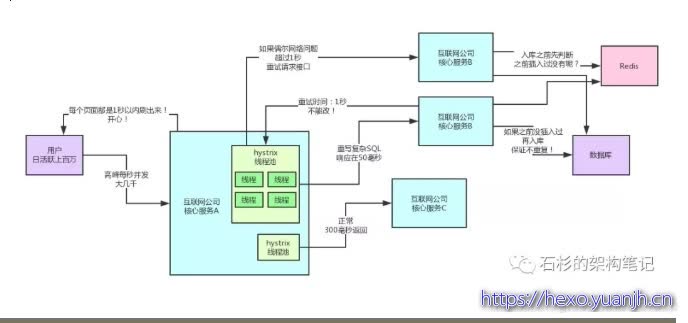
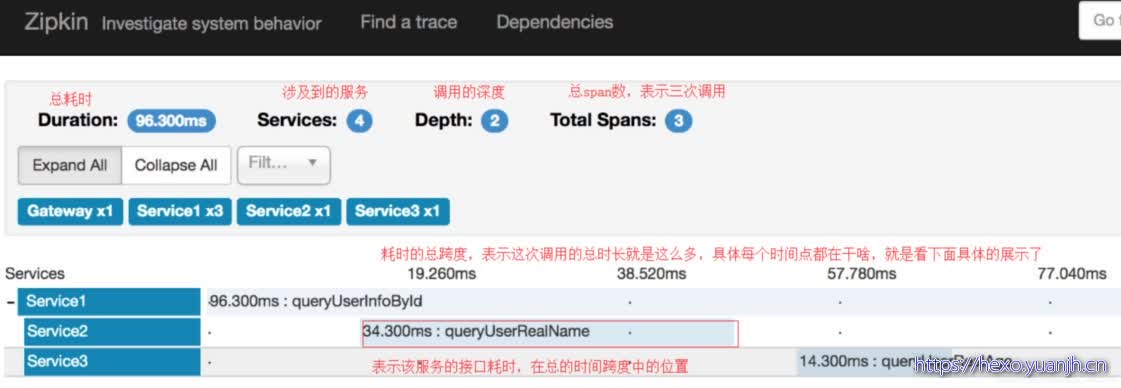
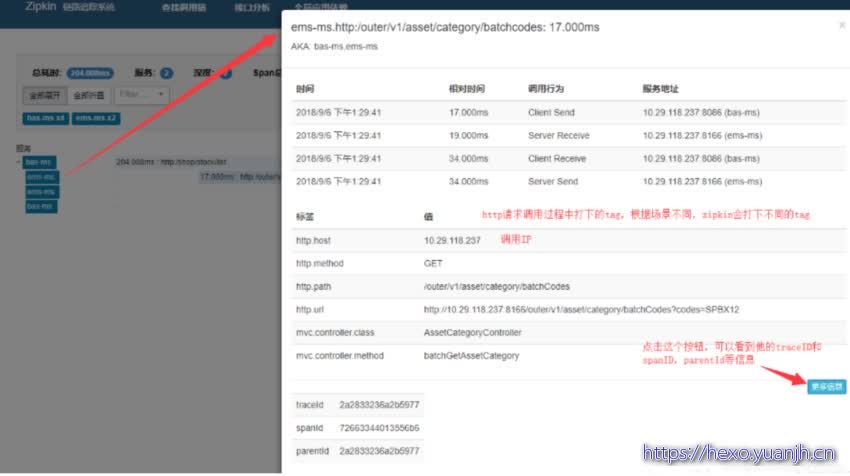
Sleuth 和 Zipkin ui界面介绍
Zipkin使用:https://blog.csdn.net/weixin_43433164/article/details/106925442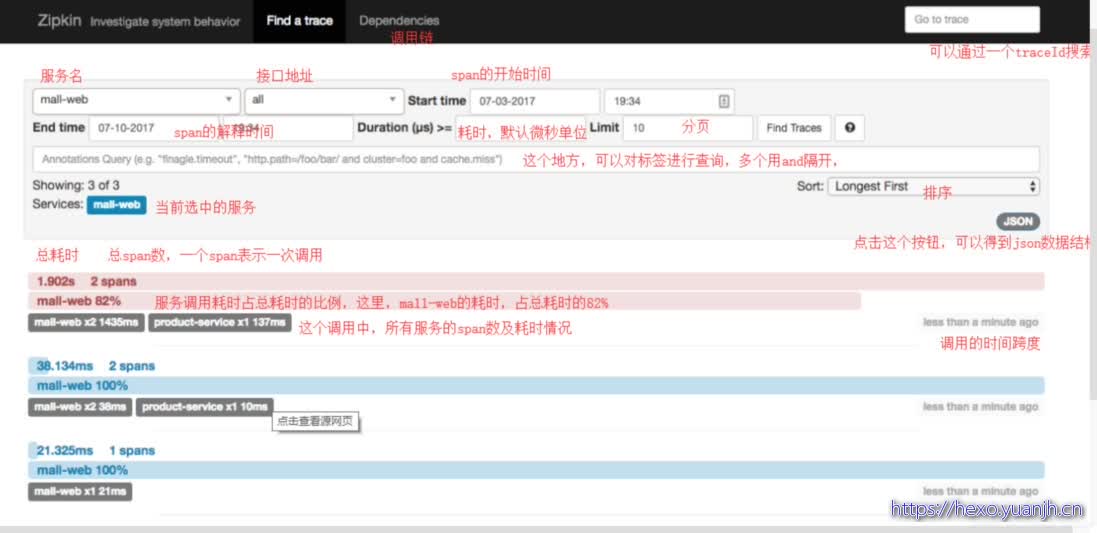
Turbine聚合的数据不够完整
在某些版本的SpringCloud(例如Brixton SR5)中,Turbine会发生该问题。该问题的直观体现是:使用Turbine聚合了多个微服务,但在Hystrix Dashboard上只能看到部分微服务的监控数据。
例如Turbine配置如下:
1 | turbine: |
Turbine理应聚合microservice-consumer-movie和microservice-consumer-movie-feign-hystrix-fallback-stream这两个微服务的监控数据,然而打开Hystrix Dashboard时会发现Dashboard上只显示部分微服务的监控数据。
解决方案
当Turbine聚合的为服务部署在同一台主机上时,就会出现该问题。
解决方案如下:
方法一:为各个微服务配置不同的hostname,并将preferIpAddress设置为false或者不设置。
方式二:设置turbine,combine-host-port = true。
方式三:升级Spring Cloud到Camden或更新版本。当然,也可单独升级Spring Cloud Netflix到1.2.0或更新版本(一般不建议单独升级Spring Cloud Netflix,因为可能会跟Spring Cloud其他组件冲突)。
这是因为老版本中的turbine.combine-host-port默认值是false。Spring Cloud已经意识到该问题,所以在新的版本中将该属性默认值修改为true。该解决方案和方法二本质上是一致的。
参考
系列教程:学习动力节点Spring Cloud:http://www.bjpowernode.com/springcloud/1155.html
系列教程:《Spring Cloud构建微服务架构》系列入门教程(Dalston):https://blog.didispace.com/spring-cloud-learning/
系列教程:Spring Cloud 系列文章:www.ityouknow.com/spring-cloud.html
系列教程: 学习spring-cloud 文章对应源码yinjihuan/spring-cloud:https://github.com/yinjihuan/spring-cloud
微服务开发之Spring Cloud:https://www.jianshu.com/p/b4aac6681c83#comments
Springcloud实战遇到的问题及解决方式:https://blog.csdn.net/zhangjq520/article/details/89448901
关于Ribbon重试机制的坑:https://www.jianshu.com/p/1148dfcd86bf
微服务开发之Spring Cloud:https://www.jianshu.com/p/b4aac6681c83#comments
Eureka集群数据同步的设计思路梳理:https://blog.csdn.net/reggergdsg/article/details/108226782
SpringCloud 注册中心 Eureka 集群是怎么保持数据一致的?:https://www.pianshen.com/article/3055766665/
微服务Spring Cloud常见问题与总结:https://blog.csdn.net/weixin_43439494/article/details/84110916
Eureka(注册发现)学习笔记:https://blog.csdn.net/shijinghan1126/article/details/103654466
踩坑 Spring Cloud Hystrix 线程池队列配置:https://www.cnblogs.com/seifon/p/9921774.html
Spring Cloud Ribbon配置详解:https://www.jb51.net/article/205028.htm
java spring系列
java_spring01读书要点
java_spring02ioc有什么优点
java_spring04Autowired与Resource差异解析
java_spring05循环依赖
java_spring06AOP
java_spring07mybatis学习要点
java_微服务01SpringCloud基础
java_微服务02SpringBoot学习笔记
java_微服务03SpringBoot常见问题
java_微服务04SpringCloud学习笔记
java_微服务06SpringCloud常见问题之Eureka
java_微服务07SpringCloud常见问题之Feign
java_微服务08SpringCloud常见问题之Hystrix
java_微服务09SpringCloud常见问题之Ribbon
java_微服务10SpringCloud常见问题之Zuul
java_微服务11SpringCloud其他问题