MyBatis 是一个小巧、方便、高效、简单、直接、半自动化的持久层框架,Hibernate 是一个强大、方便、高效、复杂、间接、全自动化的持久层框架。
工作原理
核心组件 SqlSessionFactoryBuilder、SqlSessionFactory、SqlSession和SQL Mapper生成 SqlSessionFactory ,采用的是分步构建的 Builder 模式。生成 SqlSession ,使用的是工厂模式。发送 SQL 执行 返回结果,也可以获取 Mapper 的接口 。在现有的技术中,一般我们会让其在业务逻辑代码中“消失”,而使用的是MyBatis提供的 SQL Mapper接口编程技术,它能提高代码的可读性和可维护性。发送 SQL 去执行 ,并返回结果。
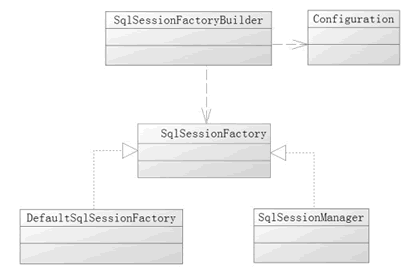
SqlSessionFactory及其常见创建方式 SqlSessionFactory 是一个接口,在 MyBatis 中它存在两个实现类:SqlSessionManager 和 DefaultSqlSessionFactory 。http://c.biancheng.net/uploads/allimg/190704/5-1ZF416213S21.png SqlSessionManager 实现了Session接口 。意味着,SqlSessionManager集成了 sqlSessionFactory和session 的功能。通过SqlSessionManager,开发者可以不在理会SqlSessionFacotry的存在,直接面向Session编程。
用 XML 构建 SqlSessionFactory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <?xml version="1.0" encoding="utf-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <typeAliases><!--别名--> <typeAliases alias="user" type="com.mybatis.po.User"/> </typeAliases> <!-- 数据库环境 --> <environments default="development"> <environment id="development"> <!-- 使用JDBC的事务管理 --> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <!-- MySQL数据库驱动 --> <property name="driver" value="com.mysql.jdbc.Driver" /> <!-- 连接数据库的URL --> <property name="url" value="jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf8" /> <property name="username" value="root" /> <property name="password" value="1128" /> </dataSource> </environment> </environments> <!-- 将mapper文件加入到配置文件中 --> <mappers> <mapper resource="com/mybatis/mapper/UserMapper.xml" /> </mappers> </configuration>
说明元素定义了一个别名 user,它代表着 com.mybatis.po.User 这个类。这样定义后,在 MyBatis 上下文中就可以使用别名去代替全限定名了。元素的定义,这里描述的是数据库。它里面的元素是配置事务管理器,这里采用的是 MyBatis 的 JDBC 管理器方式。元素配置数据库,其中属性 type=”POOLED” 代表采用 MyBatis 内部提供的连接池 方式,最后定义一些关于 JDBC 的属性信息。元素代表引入的那些映射器,在谈到映射器时会详细讨论它。
有了基础配置文件,就可以用一段很简短的代码来生成 SqlSessionFactory 了,如下所示。
1 2 3 4 5 6 7 8 9 SqlSessionFactory factory = null; String resource = "mybatis-config.xml"; InputStream is; try { InputStream is = Resources.getResourceAsStream(resource); factory = new SqlSessionFactoryBuilder().build(is); } catch (IOException e) { e.printStackTrace(); }
代码创建 SqlSessionFactory(略)
SqlSession简介 在 MyBatis 中,SqlSession 是其核心接口。在 MyBatis 中有两个实现类,DefaultSqlSession 和 SqlSessionManager 。DefaultSqlSession 是单线程使用的,而 SqlSessionManager 在多线程环境下使用 。SqlSession 的作用类似于一个 JDBC 中的 Connection 对象,代表着一个连接资源的启用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 //定义 SqlSession SqlSession sqlSession = null; try { // 打开 SqlSession 会话 sqlSession = SqlSessionFactory.openSession(); // some code... sqlSession.commit(); // 提交事务 } catch (IOException e) { sqlSession.rollback(); // 回滚事务 }finally{ // 在 finally 语句中确保资源被顺利关闭 if(sqlSession != null){ sqlSession.close(); } }
实现映射器 2种方式:XML文件形式(常用)和注解形式(基本不使用)
1 2 3 4 5 <mapper namespace="com.mybatis.mapper.RoleMapper"> <select id="getRole" parameterType="long" resultType="role"> SELECT id,role_name as roleName,note FROM role WHERE id =#{id} </select> </mapper>
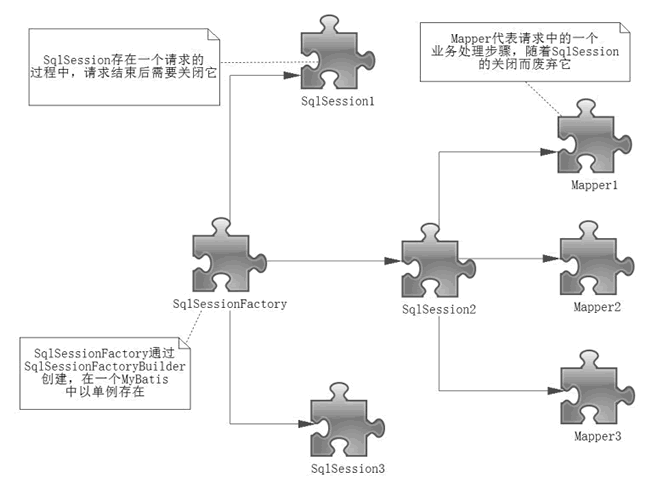
执行SQL的两种方式:SqlSession和Mapper接口(略) 核心组件的作用域以及生命周期 SqlSessionFactoryBuilder SqlSessionFactory SqlSession Mapper http://c.biancheng.net/uploads/allimg/190705/5-1ZF5104453328.png
配置文件 需要注意的是,MyBatis 配置项的顺序不能颠倒 。如果颠倒了它们的顺序,那么在 MyBatis 启动阶段就会发生异常,导致程序无法运行。
properties MyBatis 提供了 3 种方式让我们使用 properties,它们是:
settings属性配置 较多,常用如下
typeAliases(别名)(不常用) TypeHandler类型转换器 在 typeHandler 中,分为 jdbcType 和 javaType,其中 jdbcType 用于定义数据库类型,而 javaType 用于定义 Java 类型,那么 typeHandler 的作用就是承担 jdbcType 和 javaType 之间的相互转换。
系统定义的TypeHandler(略) 自定义TypeHandler 从系统定义的 typeHandler 可以知道,要实现 typeHandler 就需要去实现接口 typeHandler,或者继承 BaseTypeHandler(实际上,BaseTypeHandler 实现了 typeHandler 接口)。https://www.cnblogs.com/snake23/p/9606576.html
自定义TypeHandler处理枚举 MyBatis自定义TypeHandler处理枚举:http://c.biancheng.net/view/4343.html
BlobTypeHandler读取Blob类型字段(略) 配置文件environments和子元素transactionManager、dataSource(略) Spring整合 在Spring中配置MyBatis工厂
1 2 3 4 5 6 7 <!-- 配置SqlSessionFactoryBean --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <!-- 引用数据源组件 --> <property name="dataSource" ref="dataSource" /> <!-- 引用MyBatis配置文件中的配置 --> <property name="configLocation" value="classpath:mybatis-config.xml" /> </bean>
使用 Spring 管理 MyBatis 的数据操作接口
1 2 3 4 5 6 <!-- Mapper代理开发,使用Spring自动扫描MyBatis的接口并装配 (Sprinh将指定包中的所有被@Mapper注解标注的接口自动装配为MyBatis的映射接口) --> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <!-- mybatis-spring组件的扫描器,com.dao只需要接口(接口方法与SQL映射文件中的相同) --> <property name="basePackage" value="com.dao" /> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" /> </bean>
MyBatis与Spring的整合实例详解 :http://c.biancheng.net/view/4355.html
使用Map接口和Java Bean传递多个参数 1 2 3 4 5 6 7 8 9 10 11 12 13 public List<MyUser> selectAllUser(Map<String,Object> param); <!-- 查询陈姓男性用户信息 --> <select id="selectAllUser" resultType="com.mybatis.po.MyUser"> select * from user where uname like concat('%',#{u_name},'%') and usex = #{u_sex} </select> <select id="selectAllUser" resultType="com.po.MyUser" parameterType="com.pojo.SeletUserParam"> select * from user where uname like concat('%',#{u_name},'%') and usex=#{u_sex} </select>
常用操作标签 insert 1)主键(自动递增)回填元素添加 keyProperty 和 useGeneratedKeys 属性,具体代码如下:
1 2 3 4 <!--添加一个用户,成功后将主键值返回填给uid(po的属性)--> <insert id="addUser" parameterType="com.po.MyUser" keyProperty="uid" useGeneratedKeys="true"> insert into user (uname,usex) values(#{uname},#{usex}) </insert>
2)自定义主键元素来自定义生成主键。具体配置示例代码如下:
1 2 3 4 5 6 7 8 <!-- 添加一个用户,#{uname}为 com.mybatis.po.MyUser 的属性值 --> <insert id="insertUser" parameterType="com.po.MyUser"> <!-- 先使用selectKey元素定义主键,然后再定义SQL语句 --> <selectKey keyProperty="uid" resultType="Integer" order="BEFORE"> select if(max(uid) is null,1,max(uid)+1) as newUid from user) </selectKey> insert into user (uid,uname,usex) values(#{uid},#{uname},#{usex}) </insert>
在执行上述示例代码时,元素首先被执行,该元素通过自定义的语句设置数据表的主键,然后执行插入语句。
元素的 keyProperty 属性指定了新生主键值返回给 PO 类(com.po.MyUser)的哪个属性。元素然后执行插入语句。元素。
update、delete 和元素比较简单,它们的属性和元素、元素的属性差不多,执行后也返回一个整数,表示影响了数据库的记录行数。
sql元素 元素的作用在于可以定义 SQL 语句的一部分(代码片段),以方便后面的 SQL 语句引用它,例如反复使用的列名。元素编写一次便能在其他元素中引用它。配置示例代码如下:
1 2 3 4 <sql id="comColumns">id,uname,usex</sql> <select id="selectUser" resultType="com.po.MyUser"> select <include refid="comColumns"> from user </select>
在上述代码中使用元素的 refid 属性引用了自定义的代码片段。
resultMap元素的结构及使用 使用 Map 存储结果集 任何 select 语句都可以使用 Map 存储结果,示例代码如下:
1 2 3 4 <!-- 查询所有用户信息存到Map中 --> <select id="selectAllUserMap" resultType="map"> select * from user </select>
pojo使存储结果 配置元素元素,其属性 type 引用 POJO 类。具体配置如下:
1 2 3 4 5 6 7 8 <!--使用自定义结果集类型--> <resultMap type="com.pojo.MapUser" id="myResult"> <!-- property 是 com.pojo.MapUser 类中的属性--> <!-- column是查询结果的列名,可以来自不同的表--> <id property="m_uid" column="uid"/> <result property="m_uname" column="uname"/> <result property="m_usex" column="usex"/> </resultMap>
配置元素元素,其属性 resultMap 引用了元素的 id。具体配置如下:
1 2 3 4 <!-- 使用自定义结果集类型查询所有用户 --> <select id="selectResultMap" resultMap="myResult"> select * from user </select>
关联查询(级联查询) 一对一
1 2 3 4 5 6 7 8 9 <!-- 一对一根据id查询个人信息:级联查询的第一种方法(嵌套查询,执行两个SQL语句)--> <resultMap type="com.po.Person" id="cardAndPerson1"> <id property="id" column="id"/> <result property="name" column="name"/> <result property="age" column="age"/> <!-- 一对一级联查询--> <association property="card" column="idcard_id" javaType="com.po.Idcard" select="com.dao.IdCardDao.selectCodeByld"/> </resultMap>
一对多
1 2 3 4 5 6 7 8 9 <!-- 一对多 根据uid查询用户及其关联的订单信息:级联查询的第一种方法(嵌套查询) --> <resultMap type="com.po.MyUser" id="userAndOrders1"> <id property="uid" column="uid" /> <result property="uname" column="uname" /> <result property="usex" column="usex" /> <!-- 一对多级联查询,ofType表示集合中的元素类型,将uid传递给selectOrdersByld --> <collection property="ordersList" ofType="com.po.Orders" column="uid" select="com.dao.OrdersDao.selectOrdersByld" /> </resultMap>
动态sql
动态sql 动态sql 1 2 3 4 5 6 7 8 9 10 <!--使用 if 元素根据条件动态查询用户信息--> <select id="selectUserByIf" resultType="com.po.MyUser" parameterType="com.po.MyUser"> select * from user where 1=1 <if test="uname!=null and uname!=''"> and uname like concat('%',#{uname},'%') </if > <if test="usex !=null and usex !=''"> and usex=#{usex} </if > </select>
choose、when、otherwise标签 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <!--使用choose、when、otherwise元素根据条件动态查询用户信息--> <select id="selectUserByChoose" resultType="com.po.MyUser" parameterType= "com.po.MyUser"> select * from user where 1=1 <choose> <when test="uname!=null and uname!=''"> and uname like concat('%',#{uname},'%') </when> <when test="usex!=null and usex!=''"> and usex=#{usex} </when> <otherwise> and uid > 10 </otherwise> </choose> </select>
trim <select id=”selectUserByTrim” resultType=”com.po.MyUser”parameterType=”com.po.MyUser”>
例子中:
where 元素的作用是会在写入元素的地方输出一个 where 语句,另外一个好处是不需要考虑元素里面的条件输出是什么样子的,MyBatis 将智能处理。如果所有的条件都不满足,那么 MyBatis 就会查出所有的记录,如果输出后是以 and 开头的,MyBatis 会把第一个 and 忽略。
当然如果是以 or 开头的,MyBatis 也会把它忽略;此外,在元素中不需要考虑空格的问题,MyBatis 将智能加上。
1 2 3 4 5 6 7 8 9 10 11 12 <!--使用where元素根据条件动态查询用户信息--> <select id="selectUserByWhere" resultType="com.po.MyUser" parameterType="com.po.MyUser"> select * from user <where> <if test="uname != null and uname ! = ''"> and uname like concat('%',#{uname},'%') </if> <if test="usex != null and usex != '' "> and usex=#{usex} </if > </where> </select>
set 用元素动态更新列
1 2 3 4 5 6 7 8 9 <!--使用set元素动态修改一个用户--> <update id="updateUserBySet" parameterType="com.po.MyUser"> update user <set> <if test="uname!=null">uname=#{uname}</if> <if test="usex!=null">usex=#{usex}</if> </set> where uid=#{uid} </update>
foreach 元素主要用在构建 in 条件中,它可以在 SQL 语句中迭代一个集合。元素的属性主要有 item、index、collection、open、separator、close。
1 2 3 4 5 item 表示集合中每一个元素进行迭代时的别名。 index 指定一个名字,用于表示在迭代过程中每次迭代到的位置。 open 表示该语句以什么开始。 separator 表示在每次进行迭代之间以什么符号作为分隔符。 close 表示以什么结束。
在使用元素时,最关键、最容易出错的是 collection 属性,该属性是必选的,但在不同情况下该属性的值是不一样的,主要有以下 3 种情况:
1 2 3 如果传入的是单参数且参数类型是一个 List,collection 属性值为 list。 如果传入的是单参数且参数类型是一个 array 数组,collection 的属性值为 array。 如果传入的参数是多个,需要把它们封装成一个 Map,当然单参数也可以封装成 Map。Map 的 key 是参数名,collection 属性值是传入的 List 或 array 对象在自己封装的 Map 中的 key。
样例
1 2 3 4 5 6 7 8 9 <!--使用foreach元素查询用户信息--> <select id="selectUserByForeach" resultType="com.po.MyUser" parameterType= "List"> select * from user where uid in <foreach item="item" index="index" collection="list" open="(" separator="," close=")"> # {item} </foreach> </select>
bind标签 平时写模糊查询,一直用${name},例如:
1 select * from table where name like '%${name}%'
后来知道了,这样写可能会引发sql注入,于是乎,要用到这样一个标签 bind,经过改正上面的sql可以变成
1 2 <bind name="bindeName" value="'%'+name+'%'"/> SELECT * FROM table where name like #{bindeName}
大致就上面这个意思,不要在意一些细节。就相当于在bind标签中的value值中,把需要的字符拼接好,然后用name中的值去代替拼接好的参数。
1 2 3 <if test=” userName != null and userName ! = ””> and username like concat ( '1',#{userName},'2' ) </if>
可以改成:
1 2 3 4 <if test="" userName != null and userName !=""> <bind name= "userNameLike" value = "'1'+ userName + '2'"/> and username like #{userNameLike} </if>
内置数据查询接口 BaseMapper 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 【添加数据:(增)】 int insert(T entity); // 插入一条记录 注: T 表示任意实体类型 entity 表示实体对象 【删除数据:(删)】 int deleteById(Serializable id); // 根据主键 ID 删除 int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据 map 定义字段的条件删除 int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量删除 int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper); // 根据实体类定义的 条件删除对象 注: id 表示 主键 ID columnMap 表示表字段的 map 对象 wrapper 表示实体对象封装操作类,可以为 null。 idList 表示 主键 ID 集合(列表、数组),不能为 null 或 empty 【修改数据:(改)】 int updateById(@Param(Constants.ENTITY) T entity); // 根据 ID 修改实体对象。 int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper); // 根据 updateWrapper 条件修改实体对象 注: update 中的 entity 为 set 条件,可以为 null。 updateWrapper 表示实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) 【查询数据:(查)】 T selectById(Serializable id); // 根据 主键 ID 查询数据 List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量查询 List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据表字段条件查询 Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询记录的总条数 T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 根据实体类封装对象 查询一条记录 List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 entity 集合) List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 map 集合) List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(但只保存第一个字段的值) <E extends IPage<T>> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 entity 集合),分页 <E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 map 集合),分页 注: queryWrapper 表示实体对象封装操作类(可以为 null) page 表示分页查询条件
IService 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 【添加数据:(增)】 default boolean save(T entity); // 调用 BaseMapper 的 insert 方法,用于添加一条数据。 boolean saveBatch(Collection<T> entityList, int batchSize); // 批量插入数据 注: entityList 表示实体对象集合 batchSize 表示一次批量插入的数据量,默认为 1000 【添加或修改数据:(增或改)】 boolean saveOrUpdate(T entity); // id 若存在,则修改, id 不存在则新增数据 default boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper); // 先根据条件尝试更新,然后再执行 saveOrUpdate 操作 boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize); // 批量插入并修改数据 【删除数据:(删)】 default boolean removeById(Serializable id); // 调用 BaseMapper 的 deleteById 方法,根据 id 删除数据。 default boolean removeByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 deleteByMap 方法,根据 map 定义字段的条件删除 default boolean removeByIds(Collection<? extends Serializable> idList); // 用 BaseMapper 的 deleteBatchIds 方法, 进行批量删除。 default boolean remove(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 delete 方法,根据实体类定义的 条件删除对象。 【修改数据:(改)】 default boolean updateById(T entity); // 调用 BaseMapper 的 updateById 方法,根据 ID 选择修改。 default boolean update(T entity, Wrapper<T> updateWrapper); // 调用 BaseMapper 的 update 方法,根据 updateWrapper 条件修改实体对象。 boolean updateBatchById(Collection<T> entityList, int batchSize); // 批量更新数据 【查找数据:(查)】 default T getById(Serializable id); // 调用 BaseMapper 的 selectById 方法,根据 主键 ID 返回数据。 default List<T> listByIds(Collection<? extends Serializable> idList); // 调用 BaseMapper 的 selectBatchIds 方法,批量查询数据。 default List<T> listByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 selectByMap 方法,根据表字段条件查询 default T getOne(Wrapper<T> queryWrapper); // 返回一条记录(实体类保存)。 Map<String, Object> getMap(Wrapper<T> queryWrapper); // 返回一条记录(map 保存)。 default int count(Wrapper<T> queryWrapper); // 根据条件返回 记录数。 default List<T> list(); // 返回所有数据。 default List<T> list(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectList 方法,查询所有记录(返回 entity 集合)。 default List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectMaps 方法,查询所有记录(返回 map 集合)。 default List<Object> listObjs(); // 返回全部记录,但只返回第一个字段的值。 default <E extends IPage<T>> E page(E page, Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectPage 方法,分页查询 default <E extends IPage<Map<String, Object>>> E pageMaps(E page, Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectMapsPage 方法,分页查询 注: get 用于返回一条记录。 list 用于返回多条记录。 count 用于返回记录总数。 page 用于分页查询。 【链式调用:】 default QueryChainWrapper<T> query(); // 普通链式查询 default LambdaQueryChainWrapper<T> lambdaQuery(); // 支持 Lambda 表达式的修改 default UpdateChainWrapper<T> update(); // 普通链式修改 default LambdaUpdateChainWrapper<T> lambdaUpdate(); // 支持 Lambda 表达式的修改 注: query 表示查询 update 表示修改 Lambda 表示内部支持 Lambda 写法。 形如: query().eq("column", value).one(); lambdaQuery().eq(Entity::getId, value).list(); update().eq("column", value).remove(); lambdaUpdate().eq(Entity::getId, value).update(entity);
整理汇总 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 汇总为 【添加数据:(增)】 int insert(T entity); // 插入一条记录 boolean saveBatch(Collection<T> entityList, int batchSize); // 批量插入数据 【删除数据:(删)】 int deleteById(Serializable id); // 根据主键 ID 删除 int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量删除 int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据 map 定义字段的条件删除 【修改数据:(改)】 int updateById(@Param(Constants.ENTITY) T entity); // 根据 ID 修改实体对象。 boolean updateBatchById(Collection<T> entityList, int batchSize); // 批量更新数据 int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper); // 根据 updateWrapper 条件修改实体对象 【添加或修改数据:(增或改)】 boolean saveOrUpdate(T entity); // id 若存在,则修改, id 不存在则新增数据 boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize); // 批量插入并修改数据 default boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper); // 先根据条件尝试更新,然后再执行 saveOrUpdate 操作 【查询数据:(查)】 T selectById(Serializable id); // 根据 主键 ID 查询数据 List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量查询 List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据表字段条件查询 Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询记录的总条数 增,删,改,查,增或改:单个Id,批次id,条件id,个数查询(仅查询)
批量操作返回值 Mybatis 增删改查等操作的返回值:https://blog.csdn.net/bdqx_007/article/details/94864616
1.更新 update
Mybatis执行sql(insert、update、delete)返回值问题:https://www.cnblogs.com/aspirant/p/12213428.html
批量操作指导思想,单个,小批量,大批量 springboot在mysql里批量操作数据的一个问题。:https://segmentfault.com/q/1010000041112124
批量插入的加速 MyBatis批量插入几千条数据,请慎用foreach:https://blog.csdn.net/weixin_44421461/article/details/121847576 的语句,无法采用缓存,那么在每次调用方法时,都会重新解析sql语句。50行数量是比较合适的,时间消耗也能接受。的方式来插入,可以提升性能的方式。而实际上,MyBatis文档中写批量插入的时候,是推荐使用另外一种方法。的插入的话,需要将每次插入的记录控制在 20 50 左右。
批量更新的坑:默认matched 的条数 默认情况下,mybatis 的 update 操作返回值是记录的 matched 的条数,并不是影响的记录条数。BATCH 改为 SIMPLE 试试
mybatis批量更新返回结果为-1,是由于mybatis的defaultExecutorType引起的,
updateByPrimaryKey(Selective) 在mybatis中常常用到这2中方法。根据实体类主键进行跟新,并返回1或者0.
参考 MyBatis :http://c.biancheng.net/view/4314.html https://blog.csdn.net/qq_39396243/article/details/104018189 https://www.cnblogs.com/bpjj/p/11880424.html https://blog.csdn.net/qq_39275746/article/details/86488443 https://www.cnblogs.com/fsjohnhuang/p/4078659.html https://www.cnblogs.com/l-y-h/p/12859477.html
java spring系列java_spring01读书要点 java_spring02ioc有什么优点 java_spring04Autowired与Resource差异解析 java_spring05循环依赖 java_spring06AOP java_spring07mybatis学习要点 java_微服务01SpringCloud基础 java_微服务02SpringBoot学习笔记 java_微服务03SpringBoot常见问题 java_微服务04SpringCloud学习笔记 java_微服务06SpringCloud常见问题之Eureka java_微服务07SpringCloud常见问题之Feign java_微服务08SpringCloud常见问题之Hystrix java_微服务09SpringCloud常见问题之Ribbon java_微服务10SpringCloud常见问题之Zuul java_微服务11SpringCloud其他问题


{kind=link}
{kind=link}
