ON DUPLICATE KEY UPDATE
语句作用,当insert已经存在的记录时,执行Update(Mysql特有语法,这是个坑)。
用法:
1 | 不冲突时相当于insert,其余列默认值 |
实例测试
| id(pri) | name(uni) | password | 效果 | |
|---|---|---|---|---|
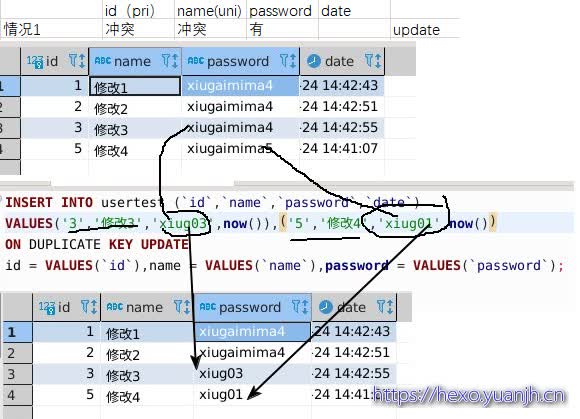
| 情况1 | 冲突 | 冲突 | 有 | update |
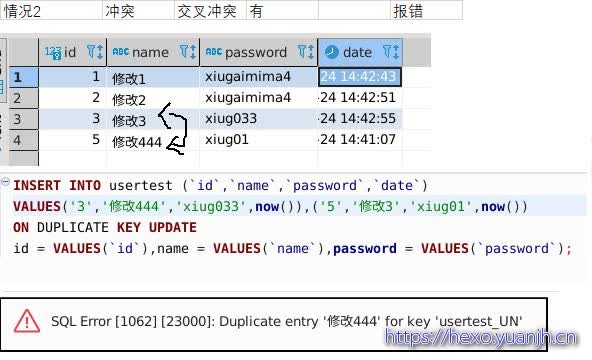
| 情况2 | 冲突 | 交叉冲突 | 有 | 报错 |
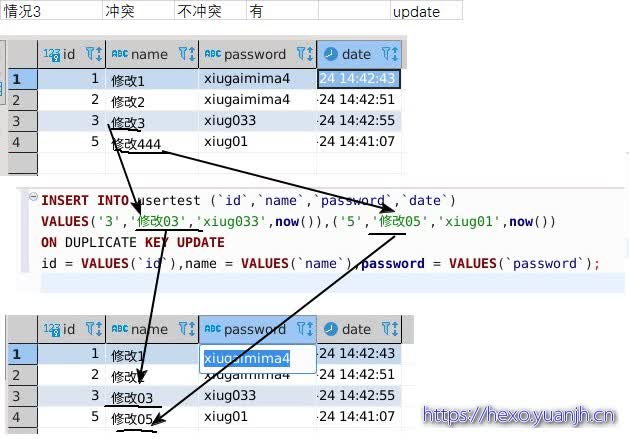
| 情况3 | 冲突 | 不冲突 | 有 | update |
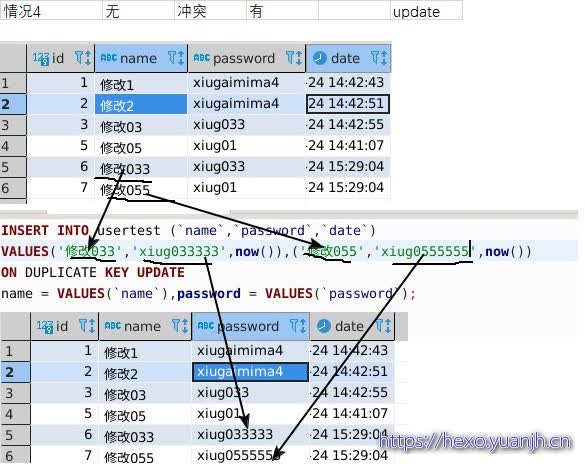
| 情况4 | 无 | 冲突 | 有 | update |
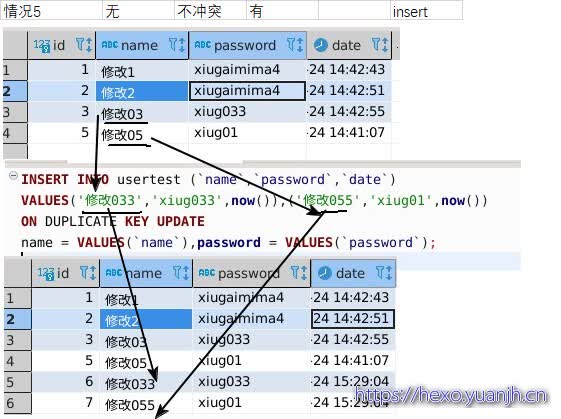
| 情况5 | 无 | 不冲突 | 有 | insert |
| 结论:按照不冲突时走insert,冲突时走update理解就ok了。 |
特别留意orm框架的封装语法
比如:goframe对save方法的封装。
其中:region_id, algo_id为联合唯一索引,Id是自增主键。
批量保存:region_id, algo_id,值对时,delete掉新入参中没有的数据后,剩余数据期望直接save。框架生成的sql如下
1 | INSERT INTO `region_algo` (`ID`, `created_at`, `updated_at`, `region_id`, `algo_id`) |
上面sql会导致,所有记录的id变化。即使这个记录是已经存在的记录。
主要是这里:UPDATE ID = VALUES(ID),会将id=0,id=0会自动赋值自增主键,生成新的id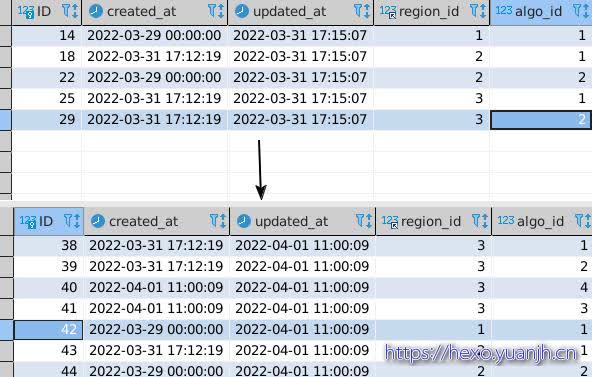
replace into
跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中,
- 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。
- 否则,直接插入新数据。
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
用法:1
2
3
4当不冲突时相当于insert,其余列默认值
当key冲突时,自增列更新,replace冲突列,其余列默认值
Com_replace会加1
Innodb_rows_updated会加1异同点
Replace into 与Insert into on duplicate key update。冲突触发为松散的uniuqe key即可,而不需要prikey。
replace into和on duplcate key update都是只有在primary key或者unique key冲突的时候才会执行。
如果数据存在,replace into则会将原有数据删除,再进行插入操作(新旧id变化),这样就会有一种情况,如果某些字段有默认值,但是replace into语句的字段不完整,则会设置成默认值。
而on duplicate key update则是执行update后面的语句。(新旧id不变)。
(1)没有key的时候,replace与insert .. on deplicate udpate相同。
(2)有key的时候,都保留主键值,并且auto_increment自动+1
不同之处:有key的时候,replace是delete老记录,而录入新的记录,所以原有的所有记录会被清除,这个时候,如果replace语句的字段不全的话,有些原有的比如例子中c字段的值会被自动填充为默认值。
而insert .. deplicate update则只执行update标记之后的sql,从表象上来看相当于一个简单的update语句。
但是实际上,根据我推测,如果是简单的update语句,auto_increment不会+1,应该也是先delete,再insert的操作,只是在insert的过程中保留除update后面字段以外的所有字段的值。
整体上看,两者的区别只有一个,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。
从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
参考
MySQL的Replace into 与Insert into on duplicate key update真正的不同之处:https://www.jb51.net/article/47090.htm
replace into和insert into on duplicate key 区别:https://blog.csdn.net/u010584271/article/details/81806065