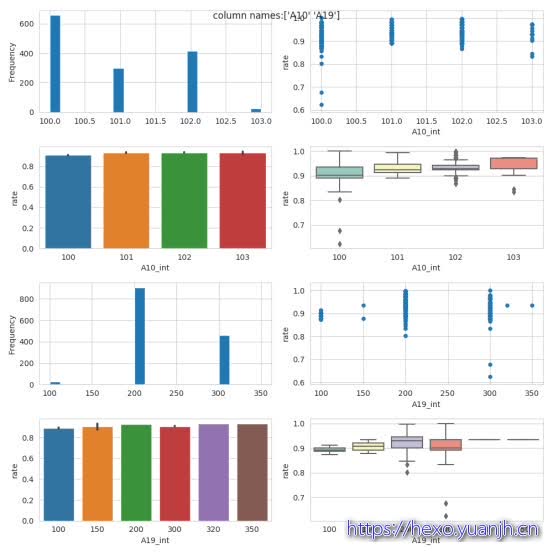
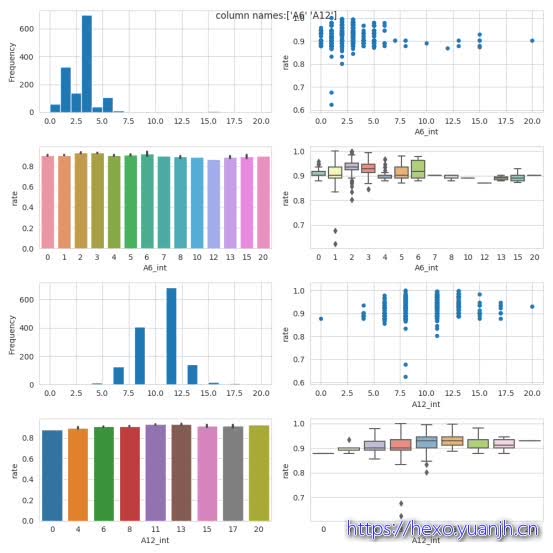
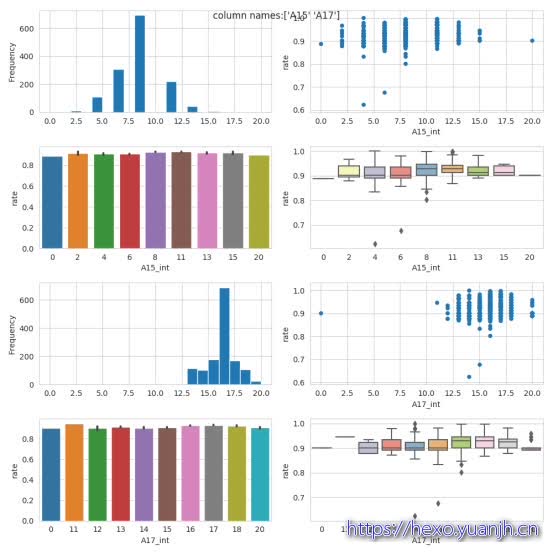
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
| 基础策略01(ref01_bug2版本)
1,丢弃损失率>90%的特征:['A2', 'A7', 'A8', 'B10', 'B11']
2,丢弃取值单一:['A1', 'A3', 'A4', 'B2', 'A13', 'A18', 'A23', 'B3', 'B13']
以上对照ref02的:1,2步骤,
差异,多丢弃了B10特征
3,缺失值填充众数:['A21', 'A23', 'A24', 'A26', 'A3', 'B1', 'B2', 'B3', 'B12', 'B13', 'B5', 'B8']
4,target<0.87认为outline点
以上对照ref02的:3,4步骤,
差异,缺失值填充用众数而非-1
5,特殊处理A25脏数据
6,oneEncoder:['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A27', 'B1', 'B8', 'B12']
7,处理各object特征的脏数据
8,
time_features = ['B7', 'B5', 'A9', 'A5', 'A26', 'A24', 'A16', 'A14', 'A11']
period_features = ['B9', 'B4', 'A28', 'A20']
时间特征:类别转int(10分钟一个单位)
时间差计算(10分钟一个单位)
time_features:1->1
period_features:1->3,开始,结束,持续时间
以上对应ref,5,6,7,
差异:ref01的period_features只转为1个特征,时间差,这里转成3个特征.
ref01的B10也做了处理,但此处B10被丢弃了,
效果:
feature_columns
['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A27', 'B1', 'B8', 'B12', 'B7_factor_hh', 'B5_factor_hh', 'A9_factor_hh', 'A5_factor_hh', 'A26_factor_hh', 'A24_factor_hh', 'A16_factor_hh', 'A14_factor_hh', 'A11_factor_hh', 'B9_factor_sh', 'B9_factor_eh', 'B9_factor_pd', 'B4_factor_sh', 'B4_factor_eh', 'B4_factor_pd', 'A28_factor_sh', 'A28_factor_eh', 'A28_factor_pd', 'A20_factor_sh', 'A20_factor_eh', 'A20_factor_pd']
FeatureTools.get_score_by_models(train_data,target_column,feature_lists=[feature_columns],models=[DecisionTreeRegressor(),RandomForestRegressor(),XGBRegressor(),SVR(),LinearRegression()])
name model mean std
0 31['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000809 0.000056
1 31['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000585 0.000030
2 31['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000543 0.000023
3 31['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000943 0.000045
4 31['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000641 0.000079
##########缩小差距
1,period_features,特征转化变为1-1
效果:
feature_columns
['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A27', 'B1', 'B8', 'B12', 'B7_factor_hh', 'B5_factor_hh', 'A9_factor_hh', 'A5_factor_hh', 'A26_factor_hh', 'A24_factor_hh', 'A16_factor_hh', 'A14_factor_hh', 'A11_factor_hh', 'B9_factor_pd', 'B4_factor_pd', 'A28_factor_pd', 'A20_factor_pd']
FeatureTools.get_score_by_models(train_data,target_column,feature_lists=[feature_columns],models=[DecisionTreeRegressor(),RandomForestRegressor(),XGBRegressor(),SVR(),LinearRegression()])
name model mean std
0 23['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000800 0.000042
1 23['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000572 0.000017
2 23['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000537 0.000031
3 23['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000943 0.000045
4 23['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000649 0.000088
2,保留B10,并且fillna(00:00-00:00)
feature_columns
['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A27', 'B1', 'B8', 'B12', 'B7_factor_hh', 'B5_factor_hh', 'A9_factor_hh', 'A5_factor_hh', 'A26_factor_hh', 'A24_factor_hh', 'A16_factor_hh', 'A14_factor_hh', 'A11_factor_hh', 'B9_factor_pd', 'B4_factor_pd', 'A28_factor_pd', 'A20_factor_pd', 'B10_factor_pd']
FeatureTools.get_score_by_models(train_data,target_column,feature_lists=[feature_columns],models=[DecisionTreeRegressor(),RandomForestRegressor(),XGBRegressor(),SVR(),LinearRegression()])
name model mean std
0 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000787 0.000053
1 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000563 0.000034
2 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000537 0.000029
3 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000943 0.000045
4 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000640 0.000083
可见效果稍稍变好,
除了这2点,自己程序和ref01逻辑应该完全一致了,
但是ref01第11步,以及取得0.0002的成绩,自己目前是0.0005,
细节:ref01时间是float h.m形式,自己是整数形式
1,空值处理,fillna(-1),之后会编码为特定label
2,编码方式上,自己是10分的int,ref01是onelable ncoding
参考这2个细节,在做改造(忽略,第1点,由于空值其实非常少,基本可忽略,故不考虑)
feature_columns
['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A27', 'B1', 'B8', 'B12', 'B7_factor_hh', 'B5_factor_hh', 'A9_factor_hh', 'A5_factor_hh', 'A26_factor_hh', 'A24_factor_hh', 'A16_factor_hh', 'A14_factor_hh', 'A11_factor_hh', 'B9_factor_pd', 'B4_factor_pd', 'A28_factor_pd', 'A20_factor_pd', 'B10_factor_pd']
FeatureTools.get_score_by_models(train_data,target_column,feature_lists=[feature_columns],models=[DecisionTreeRegressor(),RandomForestRegressor(),XGBRegressor(),SVR(),LinearRegression()])
name model mean std
0 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000785 0.000035
1 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000582 0.000032
2 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000537 0.000029
3 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000943 0.000045
4 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000611 0.000052
额,还是没啥变化,干脆使用ref01的特征处理函数对这2个特征做处理
feature_columns
['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A27', 'B1', 'B8', 'B12', 'A5', 'A9', 'A14', 'A16', 'A11', 'A24', 'A26', 'B5', 'B7', 'A20', 'A28', 'B4', 'B9', 'B10']
FeatureTools.get_score_by_models(train_data,target_column,feature_lists=[feature_columns],models=[DecisionTreeRegressor(),RandomForestRegressor(),XGBRegressor(),SVR(),LinearRegression()])
name model mean std
0 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000838 0.000029
1 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000585 0.000031
2 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000565 0.000045
3 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000943 0.000045
4 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000667 0.000056
可见依然无变化.
那就在向前面倒推?看哪一步出的差异?
继续,fillna方式和oneenbleencodeing方式
所有细节四楼都一致了,貌似还是不行
name model mean std
0 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000827 0.000066
1 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000587 0.000025
2 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000562 0.000043
3 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000942 0.000047
4 24['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000668 0.000055
原因找到了,之前的feature少了这几个特征,补充上去达到0.0002了
feature_columns.extend(['A10','A19','A25','B14','B6'])
FeatureTools.get_score_by_models(train_data,target_column,feature_lists=[feature_columns],models=[DecisionTreeRegressor(),RandomForestRegressor(),XGBRegressor(),SVR(),LinearRegression()])
Out[2]:
name model mean std
0 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000341 0.000047
1 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000228 0.000032
2 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000217 0.000024
3 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000942 0.000047
4 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000645 0.000042
这5特征都是int类型,所以没作处理
相关特征处理回滚到自己代码部分
Out[4]:
name model mean std
0 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000285 0.000033
1 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000200 0.000023
2 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000206 0.000021
3 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000942 0.000047
4 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000542 0.000092
取消float转为oneencoding
Out[2]:
name model mean std
0 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000280 0.000025
1 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000206 0.000023
2 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000205 0.000021
3 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000942 0.000047
4 29['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000544 0.000087
回复时间段特征的1转3,以及取消pd特征的encoding
Out[2]:
name model mean std
0 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000280 0.000040
1 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000205 0.000019
2 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000204 0.000017
3 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000942 0.000047
4 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000550 0.000108
去掉单个实际特征的onecodindg操作:Out[2]:
name model mean std
0 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... DecisionTreeRegressor -0.000282 0.000046
1 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... RandomForestRegressor -0.000207 0.000023
2 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... XGBRegressor -0.000204 0.000017
3 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... SVR -0.000942 0.000047
4 39['A6', 'A12', 'A15', 'A17', 'A21', 'A22', 'A... LinearRegression -0.000551 0.000109
xgb的rfe特征筛选。
list(zip(feature_columns,rfecv.support_))
Out[18]:
[('B7_factor_hh', True),
('B5_factor_hh', False),
('A9_factor_hh', True),
('A5_factor_hh', True),
('A26_factor_hh', False),
('A24_factor_hh', True),
('A16_factor_hh', True),
('A14_factor_hh', False),
('A11_factor_hh', False),
('B9_factor_sh', False),
('B9_factor_eh', True),
('B9_factor_pd', True),
('B4_factor_sh', False),
('B4_factor_eh', False),
('B4_factor_pd', True),
('A28_factor_sh', False),
('A28_factor_eh', True),
('A28_factor_pd', False),
('A20_factor_sh', False),
('A20_factor_eh', False),
('A20_factor_pd', False),
('B10_factor_sh', True),
('B10_factor_eh', False),
('B10_factor_pd', False),
('A10', True),
('A19', False),
('A25', True),
('B14', True),
('B6', True)]
|