ipynb 转化(对应notebook文件(图片路径需要重新生成):python_myproject/kaggle_housePrice/house_price01.ipynb)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 %run MyTools.py import re as refrom sklearn.grid_search import GridSearchCVfrom sklearn.datasets import make_classificationfrom sklearn.ensemble import RandomForestClassifierimport seaborn as snsfrom sklearn.decomposition import PCA from sklearn.ensemble import ExtraTreesClassifierimport re as refrom sklearn.grid_search import GridSearchCVfrom sklearn.datasets import make_classificationfrom sklearn.ensemble import RandomForestClassifierimport pandas as pdimport numpy as npimport seaborn as snsfrom scipy import statsfrom scipy.stats import skewfrom scipy.stats import normimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom sklearn.manifold import TSNEfrom sklearn.cluster import KMeansfrom sklearn.decomposition import PCAfrom sklearn.preprocessing import StandardScaler%matplotlib inline
加载训练和与测试数据 1 2 3 4 5 6 7 8 print ('Read Data From File' )FILE_DIR='/home/ds/notebooks/kaggle_house_price/officialData' data_train = pd.read_csv('{0}/train.csv' .format(FILE_DIR)) data_test=pd.read_csv('{0}/test.csv' .format(FILE_DIR)) data_train.head()
Read Data From File
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities ... PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice 0 1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500 1 2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500 2 3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 9 2008 WD Normal 223500 3 4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 140000 4 5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000
5 rows × 81 columns
合并训练预测数据 1 2 3 4 5 6 7 8 9 10 11 print ('View Data' )column_id='Id' column_label='SalePrice' train_id=data_train[column_id] test_id=data_test[column_id] data_full=data_train.append(data_test, ignore_index=True ) data_full[column_label]=data_full[column_label].fillna(1 ).astype(int) data_full.head()
View Data
1stFlrSF 2ndFlrSF 3SsnPorch Alley BedroomAbvGr BldgType BsmtCond BsmtExposure BsmtFinSF1 BsmtFinSF2 ... SaleType ScreenPorch Street TotRmsAbvGrd TotalBsmtSF Utilities WoodDeckSF YearBuilt YearRemodAdd YrSold 0 856 854 0 NaN 3 1Fam TA No 706.0 0.0 ... WD 0 Pave 8 856.0 AllPub 0 2003 2003 2008 1 1262 0 0 NaN 3 1Fam TA Gd 978.0 0.0 ... WD 0 Pave 6 1262.0 AllPub 298 1976 1976 2007 2 920 866 0 NaN 3 1Fam TA Mn 486.0 0.0 ... WD 0 Pave 6 920.0 AllPub 0 2001 2002 2008 3 961 756 0 NaN 3 1Fam Gd No 216.0 0.0 ... WD 0 Pave 7 756.0 AllPub 0 1915 1970 2006 4 1145 1053 0 NaN 4 1Fam TA Av 655.0 0.0 ... WD 0 Pave 9 1145.0 AllPub 192 2000 2000 2008
5 rows × 81 columns
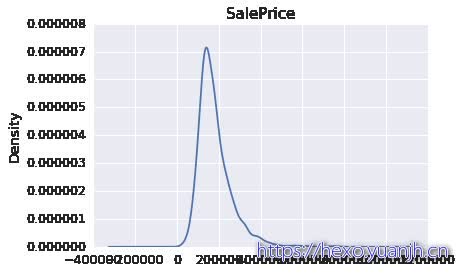
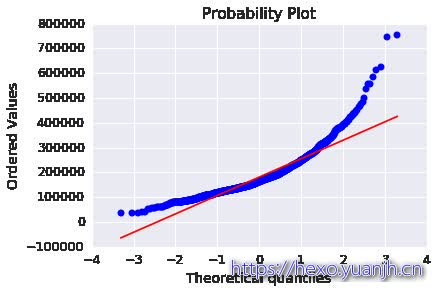
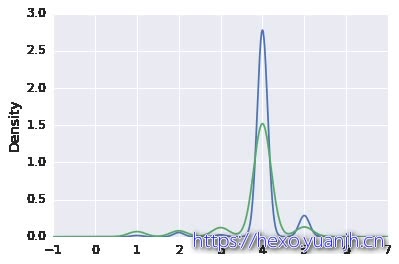
待预测特征观察 数据分布概况 峰值和偏差 数据分布图 1 2 3 4 5 6 7 print data_full[data_full[column_id].isin(id_train)][column_label].describe()print("Skewness: %f" % data_full[data_full[column_id].isin(id_train)][column_label].skew()) print("Kurtosis: %f" % data_full[data_full[column_id].isin(id_train)][column_label].kurt()) FeatureEngineerTools.show_contin_columns(data_train,[column_label]) res = stats.probplot(data_train[column_label], plot=plt)
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64
Skewness: 1.882876
Kurtosis: 6.536282
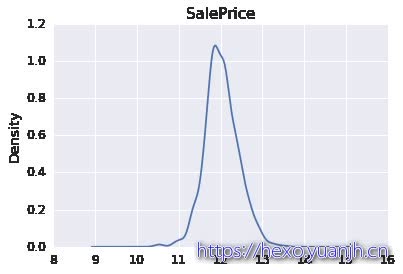
log变换 1 2 3 4 5 data_full[column_label]=data_full[column_label].apply(np.log) data_train=data_full[data_full[column_id].isin(train_id)] FeatureEngineerTools.show_contin_columns(data_train,[column_label]) res = stats.probplot(data_train[column_label], plot=plt)
特征稍多,无法依次观察,先观察特征数据类型 1 2 3 4 5 quantitative = [f for f in data_full.columns if data_full.dtypes[f] != 'object' ] qualitative = [f for f in data_full.columns if data_full.dtypes[f] == 'object' ] print("all: {} quantitative: {}({}), qualitative: {}({})" .format (len(quantitative)+len(qualitative),len(quantitative),float(len(quantitative))/(len(quantitative)+len(qualitative)) ,len(qualitative),float(len(qualitative))/(len(quantitative)+len(qualitative))))
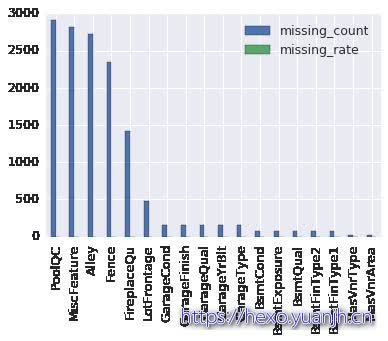
all: 81 quantitative: 38(0.469135802469), qualitative: 43(0.530864197531)特征缺失值分布情况 1 2 3 4 5 6 7 8 9 missing = data_full.isnull().sum().sort_values(ascending=False ) print 'missing feature count:' ,missing[missing>0 ].sizeprint 'missing feature count > 10:' ,missing[missing>10 ].sizemissingInfo=pd.DataFrame() missingInfo['missing_count' ]=missing[missing>0 ] missingInfo['missing_rate' ]=missingInfo['missing_count' ]/data_full.shape[0 ] missingInfo['missing_type' ]=data_full[missingInfo['missing_count' ].index].dtypes print missingInfo[missingInfo['missing_count' ]>10 ]missingInfo[missingInfo['missing_count' ]>10 ].plot.bar()
missing feature count: 34
missing feature count > 10: 18
missing_count missing_rate missing_type
PoolQC 2909 0.996574 object
MiscFeature 2814 0.964029 object
Alley 2721 0.932169 object
Fence 2348 0.804385 object
FireplaceQu 1420 0.486468 object
LotFrontage 486 0.166495 float64
GarageCond 159 0.054471 object
GarageFinish 159 0.054471 object
GarageQual 159 0.054471 object
GarageYrBlt 159 0.054471 float64
GarageType 157 0.053786 object
BsmtCond 82 0.028092 object
BsmtExposure 82 0.028092 object
BsmtQual 81 0.027749 object
BsmtFinType2 80 0.027407 object
BsmtFinType1 79 0.027064 object
MasVnrType 24 0.008222 object
MasVnrArea 23 0.007879 float64
<matplotlib.axes._subplots.AxesSubplot at 0x7fb481296410>
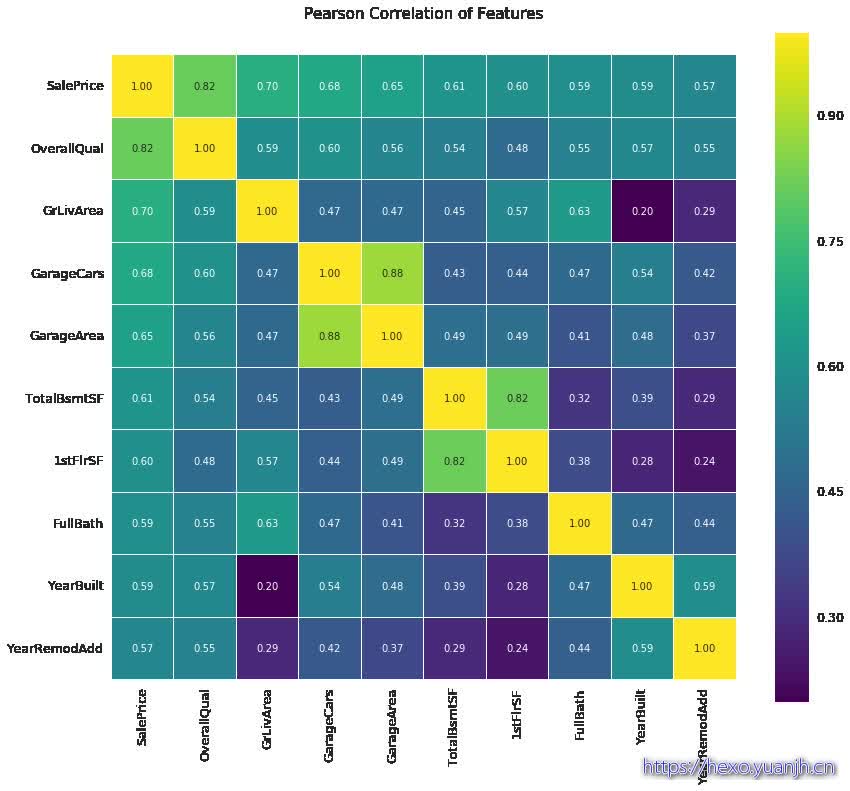
观察特征和预测目标的相关度 1 2 3 4 5 6 7 8 9 10 11 12 data_train=data_full[data_full[column_id].isin(train_id)] goodFeature=FeatureEngineerTools.heatmap(data_train,column_label,k=10 ) print 'goodFeature:' ,goodFeature
goodFeature: ['SalePrice' 'OverallQual' 'GrLivArea' 'GarageCars' 'GarageArea'
'TotalBsmtSF' '1stFlrSF' 'FullBath' 'YearBuilt' 'YearRemodAdd']
1 2 print missingInfo.index.intersection(goodFeature)missingInfo.loc[missingInfo.index.intersection(goodFeature)]
Index([u'GarageCars', u'TotalBsmtSF', u'GarageArea'], dtype='object')
missing_count missing_rate missing_type GarageCars 1 0.000343 float64 TotalBsmtSF 1 0.000343 float64 GarageArea 1 0.000343 float64
相关性最的10个属性中,3个属性有缺失,但只有一个,最简单处理方法,丢弃 需要检查缺失的数据不再测试集data_test中
不巧,不好直接丢弃,缺失数据恰好在测试集中存在 处理缺失数据
1 2 data_test=data_full[data_full[column_id].isin(test_id)] data_test[[u'GarageCars' , u'TotalBsmtSF' , u'GarageArea' ]].isnull().sum()
GarageCars 1
TotalBsmtSF 1
GarageArea 1
dtype: int641 2 data_full = data_full.drop((missingInfo[missingInfo['missing_count' ] > 50 ]).index,1 ) print data_full.isnull().sum().count(),data_full.isnull().sum().max()
65 241 2 for column in data_full.columns.intersection(quantitative): data_full[column]=data_full[column].fillna(data_full[column].dropna().mean())
1 print data_full.isnull().sum().count(),data_full.isnull().sum().max()
65 24定量属性的偏差 1 2 quantitative=data_full.columns.intersection(quantitative) data_full[quantitative].apply(lambda x: skew(x.dropna())).sort_values(ascending=False )
MiscVal 21.947195
PoolArea 16.898328
LotArea 12.822431
LowQualFinSF 12.088761
3SsnPorch 11.376065
KitchenAbvGr 4.302254
BsmtFinSF2 4.146034
EnclosedPorch 4.003891
ScreenPorch 3.946694
BsmtHalfBath 3.931343
MasVnrArea 2.611549
OpenPorchSF 2.535114
WoodDeckSF 1.842433
1stFlrSF 1.469604
BsmtFinSF1 1.425233
MSSubClass 1.375457
GrLivArea 1.269358
TotalBsmtSF 1.162484
BsmtUnfSF 0.919508
2ndFlrSF 0.861675
TotRmsAbvGrd 0.758367
Fireplaces 0.733495
HalfBath 0.694566
BsmtFullBath 0.623955
OverallCond 0.570312
BedroomAbvGr 0.326324
GarageArea 0.241218
OverallQual 0.197110
MoSold 0.195884
FullBath 0.167606
YrSold 0.132399
SalePrice 0.005930
Id 0.000000
GarageCars -0.218298
YearRemodAdd -0.451020
YearBuilt -0.599806
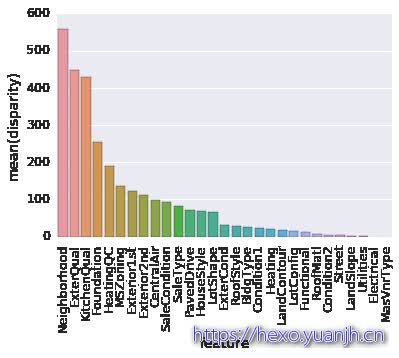
dtype: float64一元方差分析p值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def anova (frame) : anv = pd.DataFrame() anv['feature' ] = qualitative pvals = [] for c in qualitative: samples = [] for cls in frame[c].unique(): s = frame[frame[c] == cls]['SalePrice' ].values samples.append(s) pval = stats.f_oneway(*samples)[1 ] pvals.append(pval) anv['pval' ] = pvals return anv.sort_values('pval' ) data_train=data_full[data_full[column_id].isin(train_id)].copy() qualitative=data_train.columns.intersection(qualitative) print a = anova(data_train) a['disparity' ] = np.log(1. /a['pval' ].values) sns.barplot(data=a, x='feature' , y='disparity' ) x=plt.xticks(rotation=90 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def encode (frame, feature) : ordering = pd.DataFrame() ordering['val' ] = frame[feature].unique() ordering.index = ordering.val ordering['spmean' ] = frame[[feature, 'SalePrice' ]].groupby(feature).mean()['SalePrice' ] ordering = ordering.sort_values('spmean' ) ordering['ordering' ] = range(1 , ordering.shape[0 ]+1 ) ordering = ordering['ordering' ].to_dict() frame[feature+'_E' ]=frame[feature].map(ordering) qual_encoded = [] for q in qualitative: encode(data_train, q) qual_encoded.append(q+'_E' ) print(qual_encoded)
['BldgType_E', 'CentralAir_E', 'Condition1_E', 'Condition2_E', 'Electrical_E', 'ExterCond_E', 'ExterQual_E', 'Exterior1st_E', 'Exterior2nd_E', 'Foundation_E', 'Functional_E', 'Heating_E', 'HeatingQC_E', 'HouseStyle_E', 'KitchenQual_E', 'LandContour_E', 'LandSlope_E', 'LotConfig_E', 'LotShape_E', 'MSZoning_E', 'MasVnrType_E', 'Neighborhood_E', 'PavedDrive_E', 'RoofMatl_E', 'RoofStyle_E', 'SaleCondition_E', 'SaleType_E', 'Street_E', 'Utilities_E']1 2 3 print data_train.columnsprint data_train[u'Condition2_E' ].value_counts()print data_train[u'Condition2' ].value_counts()
Index([u'1stFlrSF', u'2ndFlrSF', u'3SsnPorch', u'BedroomAbvGr', u'BldgType',
u'BsmtFinSF1', u'BsmtFinSF2', u'BsmtFullBath', u'BsmtHalfBath',
u'BsmtUnfSF', u'CentralAir', u'Condition1', u'Condition2',
u'Electrical', u'EnclosedPorch', u'ExterCond', u'ExterQual',
u'Exterior1st', u'Exterior2nd', u'Fireplaces', u'Foundation',
u'FullBath', u'Functional', u'GarageArea', u'GarageCars', u'GrLivArea',
u'HalfBath', u'Heating', u'HeatingQC', u'HouseStyle', u'Id',
u'KitchenAbvGr', u'KitchenQual', u'LandContour', u'LandSlope',
u'LotArea', u'LotConfig', u'LotShape', u'LowQualFinSF', u'MSSubClass',
u'MSZoning', u'MasVnrArea', u'MasVnrType', u'MiscVal', u'MoSold',
u'Neighborhood', u'OpenPorchSF', u'OverallCond', u'OverallQual',
u'PavedDrive', u'PoolArea', u'RoofMatl', u'RoofStyle', u'SaleCondition',
u'SalePrice', u'SaleType', u'ScreenPorch', u'Street', u'TotRmsAbvGrd',
u'TotalBsmtSF', u'Utilities', u'WoodDeckSF', u'YearBuilt',
u'YearRemodAdd', u'YrSold', u'BldgType_E', u'CentralAir_E',
u'Condition1_E', u'Condition2_E', u'Electrical_E', u'ExterCond_E',
u'ExterQual_E', u'Exterior1st_E', u'Exterior2nd_E', u'Foundation_E',
u'Functional_E', u'Heating_E', u'HeatingQC_E', u'HouseStyle_E',
u'KitchenQual_E', u'LandContour_E', u'LandSlope_E', u'LotConfig_E',
u'LotShape_E', u'MSZoning_E', u'MasVnrType_E', u'Neighborhood_E',
u'PavedDrive_E', u'RoofMatl_E', u'RoofStyle_E', u'SaleCondition_E',
u'SaleType_E', u'Street_E', u'Utilities_E'],
dtype='object')
5 1445
3 6
7 2
2 2
1 2
8 1
6 1
4 1
Name: Condition2_E, dtype: int64
Norm 1445
Feedr 6
Artery 2
RRNn 2
PosN 2
RRAn 1
RRAe 1
PosA 1
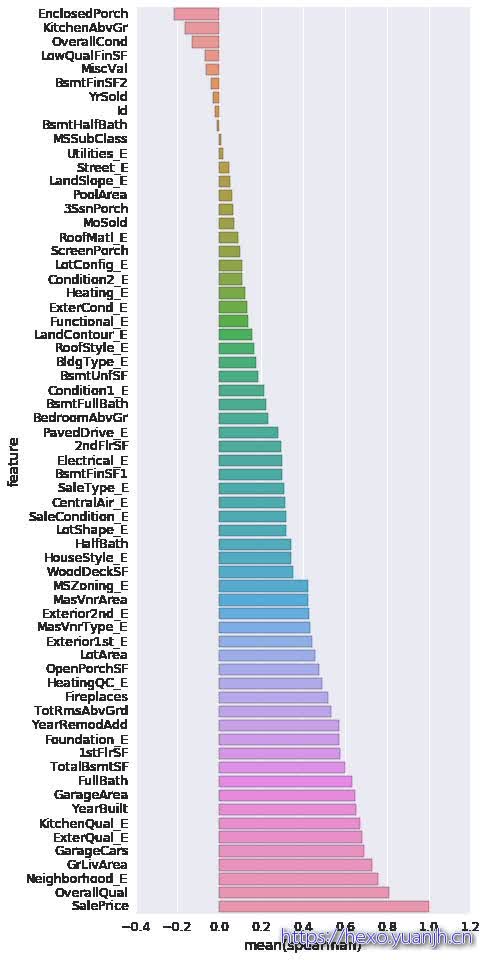
Name: Condition2, dtype: int641 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def spearman (frame, features) : spr = pd.DataFrame() spr['feature' ] = features spr['spearman' ] = [frame[f].corr(frame['SalePrice' ], 'spearman' ) for f in features] spr = spr.sort_values('spearman' ) plt.figure(figsize=(6 , 0.25 *len(features))) sns.barplot(data=spr, y='feature' , x='spearman' , orient='h' ) features = quantitative.tolist() features.extend(qual_encoded) print featuresspearman(data_train, features)
['1stFlrSF', '2ndFlrSF', '3SsnPorch', 'BedroomAbvGr', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtFullBath', 'BsmtHalfBath', 'BsmtUnfSF', 'EnclosedPorch', 'Fireplaces', 'FullBath', 'GarageArea', 'GarageCars', 'GrLivArea', 'HalfBath', 'Id', 'KitchenAbvGr', 'LotArea', 'LowQualFinSF', 'MSSubClass', 'MasVnrArea', 'MiscVal', 'MoSold', 'OpenPorchSF', 'OverallCond', 'OverallQual', 'PoolArea', 'SalePrice', 'ScreenPorch', 'TotRmsAbvGrd', 'TotalBsmtSF', 'WoodDeckSF', 'YearBuilt', 'YearRemodAdd', 'YrSold', 'BldgType_E', 'CentralAir_E', 'Condition1_E', 'Condition2_E', 'Electrical_E', 'ExterCond_E', 'ExterQual_E', 'Exterior1st_E', 'Exterior2nd_E', 'Foundation_E', 'Functional_E', 'Heating_E', 'HeatingQC_E', 'HouseStyle_E', 'KitchenQual_E', 'LandContour_E', 'LandSlope_E', 'LotConfig_E', 'LotShape_E', 'MSZoning_E', 'MasVnrType_E', 'Neighborhood_E', 'PavedDrive_E', 'RoofMatl_E', 'RoofStyle_E', 'SaleCondition_E', 'SaleType_E', 'Street_E', 'Utilities_E']
1 2 print quantitativeprint qual_encoded
Index([u'1stFlrSF', u'2ndFlrSF', u'3SsnPorch', u'BedroomAbvGr', u'BsmtFinSF1',
u'BsmtFinSF2', u'BsmtFullBath', u'BsmtHalfBath', u'BsmtUnfSF',
u'EnclosedPorch', u'Fireplaces', u'FullBath', u'GarageArea',
u'GarageCars', u'GrLivArea', u'HalfBath', u'Id', u'KitchenAbvGr',
u'LotArea', u'LowQualFinSF', u'MSSubClass', u'MasVnrArea', u'MiscVal',
u'MoSold', u'OpenPorchSF', u'OverallCond', u'OverallQual', u'PoolArea',
u'SalePrice', u'ScreenPorch', u'TotRmsAbvGrd', u'TotalBsmtSF',
u'WoodDeckSF', u'YearBuilt', u'YearRemodAdd', u'YrSold'],
dtype='object')
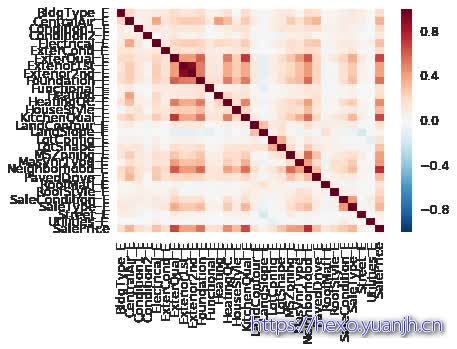
['BldgType_E', 'CentralAir_E', 'Condition1_E', 'Condition2_E', 'Electrical_E', 'ExterCond_E', 'ExterQual_E', 'Exterior1st_E', 'Exterior2nd_E', 'Foundation_E', 'Functional_E', 'Heating_E', 'HeatingQC_E', 'HouseStyle_E', 'KitchenQual_E', 'LandContour_E', 'LandSlope_E', 'LotConfig_E', 'LotShape_E', 'MSZoning_E', 'MasVnrType_E', 'Neighborhood_E', 'PavedDrive_E', 'RoofMatl_E', 'RoofStyle_E', 'SaleCondition_E', 'SaleType_E', 'Street_E', 'Utilities_E']1 2 3 4 5 6 7 8 9 10 11 12 13 plt.figure(1 ) corr = data_train[quantitative.tolist()].corr() sns.heatmap(corr) plt.figure(2 ) corr = data_train[qual_encoded+['SalePrice' ]].corr() sns.heatmap(corr) plt.figure(3 ) corr = pd.DataFrame(np.zeros([len(quantitative), len(qual_encoded)+1 ]), index=quantitative, columns=qual_encoded+['SalePrice' ]) for q1 in quantitative: for q2 in qual_encoded+['SalePrice' ]: corr.loc[q1, q2] = data_train[q1].corr(data_train[q2]) sns.heatmap(corr)
<matplotlib.axes._subplots.AxesSubplot at 0x7fb48143fdd0>
---------------------------------------------------------------------------
LinAlgError Traceback (most recent call last)
<ipython-input-173-ddff58c709b6> in <module>()
12 for column in qual_encoded:
13 # FeatureEngineerTools.show_corr_int_label(data_train,column,'SalePrice')
---> 14 FeatureEngineerTools.show_corr_contin_label(data_train,column,'SalePrice')
/home/ds/notebooks/kaggle_house_price/MyTools.py in show_corr_contin_label(data, column, label)
281 label_value_set=data[label].value_counts().keys()
282 for label_value in label_value_set:
--> 283 data[column][data[label] == label_value].plot(kind='kde')
284 plt.xlabel("column") # plots an axis lable
285 plt.ylabel(u"密度")
/opt/ds/local/lib/python2.7/site-packages/pandas/plotting/_core.pyc in __call__(self, kind, ax, figsize, use_index, title, grid, legend, style, logx, logy, loglog, xticks, yticks, xlim, ylim, rot, fontsize, colormap, table, yerr, xerr, label, secondary_y, **kwds)
2501 colormap=colormap, table=table, yerr=yerr,
2502 xerr=xerr, label=label, secondary_y=secondary_y,
-> 2503 **kwds)
2504 __call__.__doc__ = plot_series.__doc__
2505
/opt/ds/local/lib/python2.7/site-packages/pandas/plotting/_core.pyc in plot_series(data, kind, ax, figsize, use_index, title, grid, legend, style, logx, logy, loglog, xticks, yticks, xlim, ylim, rot, fontsize, colormap, table, yerr, xerr, label, secondary_y, **kwds)
1925 yerr=yerr, xerr=xerr,
1926 label=label, secondary_y=secondary_y,
-> 1927 **kwds)
1928
1929
/opt/ds/local/lib/python2.7/site-packages/pandas/plotting/_core.pyc in _plot(data, x, y, subplots, ax, kind, **kwds)
1727 plot_obj = klass(data, subplots=subplots, ax=ax, kind=kind, **kwds)
1728
-> 1729 plot_obj.generate()
1730 plot_obj.draw()
1731 return plot_obj.result
/opt/ds/local/lib/python2.7/site-packages/pandas/plotting/_core.pyc in generate(self)
250 self._compute_plot_data()
251 self._setup_subplots()
--> 252 self._make_plot()
253 self._add_table()
254 self._make_legend()
/opt/ds/local/lib/python2.7/site-packages/pandas/plotting/_core.pyc in _make_plot(self)
1357 kwds = self._make_plot_keywords(kwds, y)
1358 artists = self._plot(ax, y, column_num=i,
-> 1359 stacking_id=stacking_id, **kwds)
1360 self._add_legend_handle(artists[0], label, index=i)
1361
/opt/ds/local/lib/python2.7/site-packages/pandas/plotting/_core.pyc in _plot(cls, ax, y, style, bw_method, ind, column_num, stacking_id, **kwds)
1412
1413 if LooseVersion(spv) >= '0.11.0':
-> 1414 gkde = gaussian_kde(y, bw_method=bw_method)
1415 else:
1416 gkde = gaussian_kde(y)
/opt/ds/local/lib/python2.7/site-packages/scipy/stats/kde.pyc in __init__(self, dataset, bw_method)
170
171 self.d, self.n = self.dataset.shape
--> 172 self.set_bandwidth(bw_method=bw_method)
173
174 def evaluate(self, points):
/opt/ds/local/lib/python2.7/site-packages/scipy/stats/kde.pyc in set_bandwidth(self, bw_method)
497 raise ValueError(msg)
498
--> 499 self._compute_covariance()
500
501 def _compute_covariance(self):
/opt/ds/local/lib/python2.7/site-packages/scipy/stats/kde.pyc in _compute_covariance(self)
508 self._data_covariance = atleast_2d(np.cov(self.dataset, rowvar=1,
509 bias=False))
--> 510 self._data_inv_cov = linalg.inv(self._data_covariance)
511
512 self.covariance = self._data_covariance * self.factor**2
/opt/ds/local/lib/python2.7/site-packages/scipy/linalg/basic.pyc in inv(a, overwrite_a, check_finite)
974 inv_a, info = getri(lu, piv, lwork=lwork, overwrite_lu=1)
975 if info > 0:
--> 976 raise LinAlgError("singular matrix")
977 if info < 0:
978 raise ValueError('illegal value in %d-th argument of internal '
LinAlgError: singular matrix
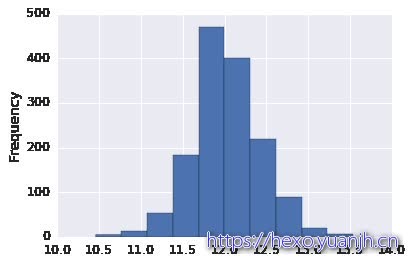
1 2 a = train_data['SalePrice' ] a.plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x7fb4813fb510>
房价二值化后的 差异因子 1 2 3 4 5 6 7 8 9 10 11 12 features = quantitative standard = data_train[data_train['SalePrice' ] < np.log(200000 )] pricey = data_train[data_train['SalePrice' ] >= np.log(200000 )] diff = pd.DataFrame() diff['feature' ] = features diff['difference' ] = [(pricey[f].fillna(0. ).mean() - standard[f].fillna(0. ).mean())/(standard[f].fillna(0. ).mean()) for f in features] sns.barplot(data=diff, x='feature' , y='difference' ) x=plt.xticks(rotation=90 )
0.838490066289