人脸检测追踪的原理和架构
应用在做什么?
利用已有算法的不同特性(识别速度,准确率,角度鲁棒性,光线鲁棒性等)
设计合适的算法利用方式(图片预处理(自适应亮度光照等),特定场景偏好(可以多报但不能漏报,或可以漏但不能误报类似的),单算法在特定场景的参数,多算法的组合协同使用方式)
以最小的系统资源占用达到最好的识别效果和最大的识别量(支持视频路数,帧率等)
满足产品的功能性需求
从这个角度讲,做应用的难度其实比算法高。
算法由于有学术界和巨头IT公司支撑,工业界大多直接借助学术界研究成果,所以同质性很高。算法PK最终沦为了”数据集PK“,谁能拿到最大量,最多样的数据,谁就能训练出较好的算法。当然,针对特定现实场景做适配(比如,光线一直很暗情况下是否需要对算法做调整,以及牺牲算法通用性,从而提高特定领域的速度和准确率表现) 可以说改进点非常有限。可能算法调三月,不如数据集扩3倍或GPU大10倍(提高训练充分度),工业界算法部门大多数做算法适配性调优。
就现状而言,个人认为做算法其实更有前景,当然难度也更高。一方面由于机器学习理论走的靠前,而现实中落地有限,二者是较大落差的,这就给应用足够的发挥空间,将理论迁入到现实,改善提高现实生活。一方面是由于机器学习算法表现依然不是非常理想(效果理想的速度不行,速度足够的效果又不够),所以需要较好的“融合能力”,将各个算法优势发挥出来,劣势避免掉,从而实现落地。
版本V0.1
视频效果样例:链接: https://pan.baidu.com/s/1G9kw1iSCJN0MlyZceFMI9Q 提取码: nt8n
人脸识别遗漏

追踪误差(模糊导致的)

算法调研,人脸检测最好算法(准确率不考虑速度),人脸(物体)追踪最好算法(准确率不考虑速度)
版本V0.2卡顿问题的解决
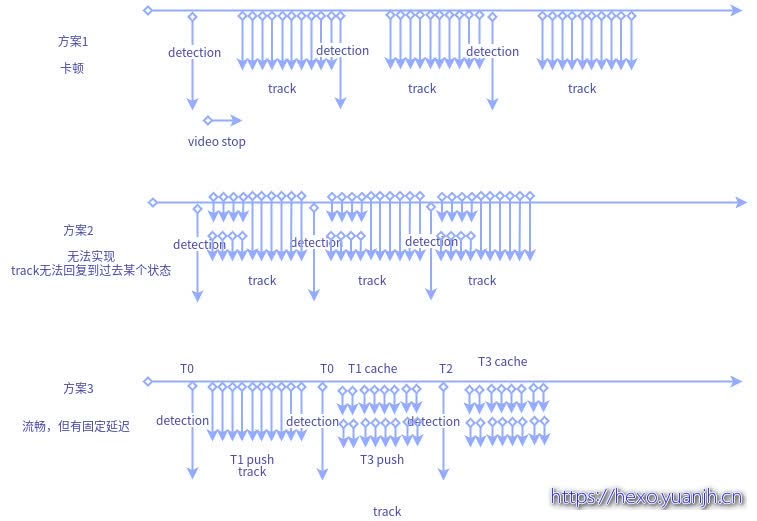
三个方案
方案1:目前方案,每20帧执行一次detection,由于未采用缓冲区技术暂存frame,所以detection后会跳过一段(被丢弃的)frame,导致track效果降低。如果采用缓冲区技术暂存frame,可以解决帧丢弃导致的track不准问题,但是依然会带来卡顿问题(本质是detection和解码速度差异较大)。在detection时,track必须等待detection结果,所以此时没有frame推送给用户.用户会感觉”卡主”。
方案2:在方案1基础上,detection第40帧时(举例),track先利用最新帧继续追踪着(40帧,41帧,42帧等),同时结果push给用户(用户继续看到40帧,41帧,42帧等,不过40帧是track输出的结果(方案1中40帧是detection的结果)),当40帧的detection结果拿到后,再后台track(但不再push,否则会出现用户刚才看到43帧了,40帧的detection回来后,track又推送40帧的图像,也就是倒退了),等到追上了之前的track的push后,再接管push权利。此时也会存在一定的卡顿时间,但是相对detection的等待会小一些。
但是别忘了,track是有状态的,且无法进行回滚的(也无法进行保存),当我们使用track到43帧的track再track40帧时,有大概率会导致track失败,从而降低整体效果。虽然可以通过重新创建的方式和旧track联系起来,但是频繁的销毁创建track也会降低整体效率.
方案3:方案2本身是很好的思路,奈何track无法状态回滚。不妨换一种方式。
T0时:缓冲区存在帧0-20帧,
T1时:detection最新帧(也就是第20帧)
T2时:收到T1时的detection结果返回后,立刻取得缓冲区的最新帧(假如这段时间解码器收集了10帧,缓冲区最新帧在30),继续执行detection(第30帧),同时track开始工作,拿到第20帧detection结果,初始化track,之后对20-30之间的帧执行track并推送给用户。理想情况下,执行到30帧后,detection也返回第30帧的结果,同时队列最新帧变成40了.这样就可以持续下去,但是用户看到的其实持续时旧的视频信息,相差10帧。
以上是理想情况,需要考虑解码时间,detection时间,和track时间关系,可能需要用锁进行时间差控制,避免比如track过快,导致很快将缓冲区消费掉,而detection结果尚未收到,从而带来用户看到视频一会快,一会慢的问题!
方案三等价于:
做了多队列合一(节约空间),帧率控制(避免track消费frame过快,导致detection引起的卡顿
效果分析
1 | put frame:0#第0帧入队列 |
实际效果:
链接: https://pan.baidu.com/s/1g2h7nyHkjZV0tjScpx3c3Q 提取码: 81ve
可见的确连贯很多,但是也存在卡顿现象,(track和decode时间不匹配),
放弃这个修改,原因:
第一:逻辑稍复杂,不利于阅读也不利于后续的开发,调试。
第二:实际应用中,PUSH一般是专用流服务器,Push时其实是依据配置的帧率,和流的运算时间关系不大(也就说只要保证推送顺序正确,至于速度,推送服务器会按照配置自行处理,所以也就不存在卡顿问题)
所以,暂时用简单版本,如果后面真的需要则最后再添加。
版本V0.3多线程支持
版本V0.4无法正确匹配到人的问题
人脸检测算法
1 | face_detector = cv2.CascadeClassifier(faceadd) |
特征值提取:
1 | person |
跟踪
1 | cv2.TrackerKCF_create() |
无法匹配原因
使用boxes=>切分frame=>小图保存为face_frame=>生成特征值 (加载人脸img生成decoding时,也存在着部分无法正确encoding的问题)encoding结果
和
在原图中直接执行face_recognition.face_encodings(frame, known_face_locations=boxes)
结果不同
导致无法正确匹配
解决方法01,检测也是用face_recognition
猜测同一个工具的检测和识别应该可以匹配起来