读书_w3c架构师
架构 秒杀系统优化思路
基本思路
(1)将请求尽量拦截在系统上游(不要让锁冲突落到数据库上去)
(2)充分利用缓存,秒杀买票,这是一个典型的读多写少的应用场景,大部分请求是车次查询
第一层,客户端怎么优化(浏览器层,APP层)
(a)产品层面,用户点击“查询”或者“购票”后,按钮置灰,禁止用户重复提交请求;
(b)JS层面,限制用户在x秒之内只能提交一次请求;
第二层,站点层面的请求拦截
怎么拦截?怎么防止程序员写for循环调用,有去重依据么?
这类业务都需要登录,用uid即可。在站点层面,对uid进行请求计数和去重,
5s只透过一个请求,其余的请求怎么办?缓存,页面缓存,同一个uid,限制访问频度,做页面缓存,x秒内到达站点层的请求,均返回同一页面。
第三层 服务层来拦截(反正就是不要让请求落到数据库上去)
意义呢?没错,请求队列!
对于写请求,做请求队列,每次只透有限的写请求去数据层(下订单,支付这样的写业务)
1w部手机,只透1w个下单请求去db
3k张火车票,只透3k个下单请求去db
当然,还有业务规则上的一些优化。回想12306所做的,分时分段售票,原来统一10点卖票,现在8点,8点半,9点,…每隔半个小时放出一批:将流量摊匀。
第四层 最后是数据库层
闲庭信步,单机也能扛得住,
架构 细聊分布式ID生成方法
【常见方法一:使用数据库的 auto_increment 来生成全局唯一递增ID】
优点:
(1)简单,使用数据库已有的功能
(2)能够保证唯一性
(3)能够保证递增性
缺点:
(1)可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
(2)扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
改进方法:
(1)增加主库,避免写入单点
(2)数据水平切分,保证各主库生成的ID不重复
改进后的架构保证了可用性,但缺点是:
(1)丧失了ID生成的“绝对递增性”
(2)数据库的写压力依然很大,每次生成ID都要访问数据库
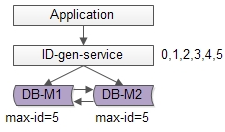
【常见方法二:单点批量ID生成服务】
https://atts.w3cschool.cn/attachments/image/20170428/1493370800458061.png
优点:
(1)保证了ID生成的绝对递增有序
(2)大大的降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
(1)服务仍然是单点
(2)如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞
(3)虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
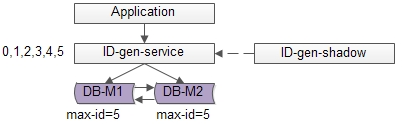
改进方法:
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”
https://atts.w3cschool.cn/attachments/image/20170428/1493370919182595.png
{kind=link}
{kind=link}
【常见方法三:uuid】
优点:
(1)本地生成ID,不需要进行远程调用,时延低
(2)扩展性好,基本可以认为没有性能上限
缺点:
(1)无法保证趋势递增
(2)uuid过长,往往用字符串表示,作为主键建立索引查询效率低
【常见方法四:取当前毫秒数】
优点:
(1)本地生成ID,不需要进行远程调用,时延低
(2)生成的ID趋势递增
(3)生成的ID是整数,建立索引后查询效率高
缺点:
(1)如果并发量超过1000,会生成重复的ID
【常见方法五:类snowflake算法】
snowflake是twitter开源的分布式ID生成算法,其核心思想是:一个long型的ID,使用其中41bit作为毫秒数,10bit作为机器编号,12bit作为毫秒内序列号。这个算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
借鉴snowflake的思想,结合各公司的业务逻辑和并发量,可以实现自己的分布式ID生成算法。
缺点:
(1)由于“没有一个全局时钟”,每台服务器分配的ID是绝对递增的,但从全局看,生成的ID只是趋势递增的(有些服务器的时间早,有些服务器的时间晚)
最后一个容易忽略的问题:
生成的ID,例如message-id/ order-id/ tiezi-id,在数据量大时往往需要分库分表,这些ID经常作为取模分库分表的依据,为了分库分表后数据均匀,ID生成往往有“取模随机性”的需求,所以我们通常把每秒内的序列号放在ID的最末位,保证生成的ID是随机的。
又如果,我们在跨毫秒时,序列号总是归0,会使得序列号为0的ID比较多,导致生成的ID取模后不均匀。解决方法是,序列号不是每次都归0,而是归一个0到9的随机数,这个地方。
互联网架构设计的容量评估
【步骤一:评估总访问量】
->询问业务、产品、运营
【步骤二:评估平均访问量QPS】
->除以时间,一天算4w秒
【步骤三:评估高峰QPS】
->根据业务曲线图来
【步骤四:评估系统、单机极限QPS】
->压测很重要
【步骤五:根据线上冗余度回答两个问题】
-> 估计冗余度与线上冗余度差值
架构 线程数设置
Worker线程在执行的过程中,有一部计算时间需要占用CPU,另一部分等待时间不需要占用CPU,通过量化分析,例如打日志进行统计,可以统计出整个Worker线程执行过程中这两部分时间的比例,例如:
1)时间轴1,3,5,7【上图中粉色时间轴】的计算执行时间是100ms
2)时间轴2,4,6【上图中橙色时间轴】的等待时间也是100ms
得到的结果是,这个线程计算和等待的时间是1:1,即有50%的时间在计算(占用CPU),50%的时间在等待(不占用CPU):
1)假设此时是单核,则设置为2个工作线程就可以把CPU充分利用起来,让CPU跑到100%
2)假设此时是N核,则设置为2N个工作现场就可以把CPU充分利用起来,让CPU跑到N*100%
结论:
N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x,能让CPU的利用率最大化。
经验:
一般来说,非CPU密集型的业务(加解密、压缩解压缩、搜索排序等业务是CPU密集型的业务),瓶颈都在后端数据库,本地CPU计算的时间很少,所以设置几十或者几百个工作线程也都是可能的。
单点系统架构的可用性与性能优化
(1)单点系统存在的问题:可用性问题,性能瓶颈问题
(2)shadow-master是一种常见的解决单点系统可用性问题的方案
(3)减少与单点的交互,是存在单点的系统优化的核心方向,常见方法有批量写,客户端缓存
(4)水平扩展也是提升单点系统性能的好方案
一分钟了解负载均衡的一切
负载均衡(Load Balance)是分布式系统架构设计中必须考虑的因素之一,它通常是指,将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。
(1)【客户端层】到【反向代理层】的负载均衡,是通过“DNS轮询”实现的
(2)【反向代理层】到【站点层】的负载均衡,是通过“nginx”实现的
1)请求轮询:和DNS轮询类似,请求依次路由到各个web-server
2)最少连接路由:哪个web-server的连接少,路由到哪个web-server
3)ip哈希:按照访问用户的ip哈希值来路由web-server,只要用户的ip分布是均匀的,请求理论上也是均匀的,ip哈希均衡方法可以做到,同一个用户的请求固定落到同一台web-server上,此策略适合有状态服务,例如session(58沈剑备注:可以这么做,但强烈不建议这么做,站点层无状态是分布式架构设计的基本原则之一,session最好放到数据层存储)
(3)【站点层】到【服务层】的负载均衡,是通过“服务连接池”实现的
(4)【数据层】的负载均衡,要考虑“数据的均衡”与“请求的均衡”两个点,常见的方式有“按照范围水平切分”与“hash水平切分”
数据的均衡是指:水平切分后的每个服务(db,cache),数据量是差不多的。
请求的均衡是指:水平切分后的每个服务(db,cache),请求量是差不多的。
一、按照range水平切分
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务
(2)数据均衡性较好
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务
不足是:
(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大
二、按照id哈希水平切分
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务
(2)数据均衡性较好
(3)请求均匀性较好
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移
lvs为何不能完全替代DNS轮询
稍微做一个简要的总结:
1)接入层架构要考虑的问题域为:高可用、扩展性、反向代理+扩展均衡
2)nginx、keepalived、lvs、f5可以很好的解决高可用、扩展性、反向代理+扩展均衡的问题
3)水平扩展scale out是解决扩展性问题的根本方案,DNS轮询是不能完全被nginx/lvs/f5所替代的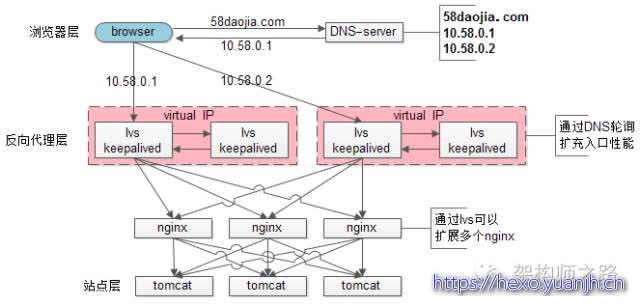
如何实施异构服务器的负载均衡及过载保护
回答:互联网软件架构设计中所指的过载保护,是指当系统负载超过一个service的处理能力时,如果service不进行自我保护,可能导致对外呈现处理能力为0,且不能自动恢复的现象。而service的过载保护,是指即使系统负载超过一个service的处理能力,service让能保证对外提供有损的稳定服务。
图示:有过载保护的负载与处理能力图(不会掉底)
提问:如何进行过载保护?
回答:最简易的方式,服务端设定一个负载阈值,超过这个阈值的请求压过来,全部抛弃。这个方式不是特别优雅。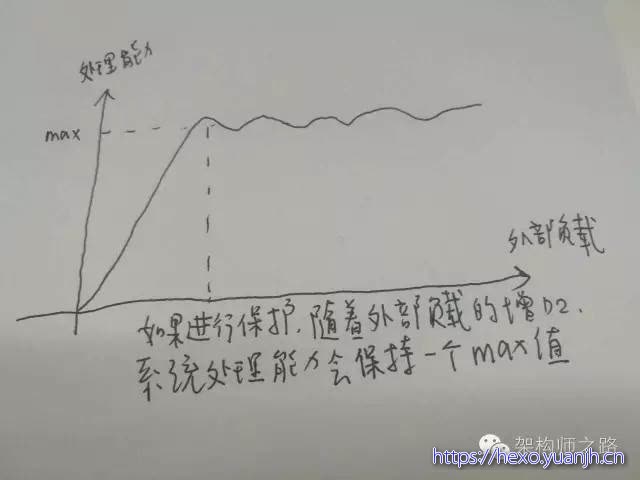
需要注意的是:要防止客户端的过载保护引起service的雪崩,如果“整体负载”已经超过了“service集群”的处理能力,怎么转移请求也是处理不过来的,还得通过抛弃请求来实施自我保护。
总结
1)service的负载均衡、故障转移、超时处理通常是RPC-client连接池层面来实施的
2)异构服务器负载均衡,最简单的方式是静态权重法,缺点是无法自适应动态调整
3)动态权重法,可以动态的根据service的处理能力来分配负载,需要有连接池层面的微小改动
4)过载保护,是在负载过高时,service为了保护自己,保证一定处理能力的一种自救方法
5)动态权重法,还可以用做service的过载保护
究竟啥才是互联网架构“高并发”
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
二、如何提升系统的并发能力
总结
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
究竟啥才是互联网架构“高可用”
总结
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
(2)【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
(3)【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
(4)【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
【服务层】到【缓存层】的高可用,是通过缓存数据的冗余来实现的。
缓存层的数据冗余又有几种方式:第一种是利用客户端的封装,service对cache进行双读或者双写。
缓存层也可以通过支持主从同步的缓存集群来解决缓存层的高可用问题。
以redis为例,redis天然支持主从同步,redis官方也有sentinel哨兵机制,来做redis的存活性检测。
自动故障转移:当redis主挂了的时候,sentinel能够探测到,会通知调用方访问新的redis,整个过程由sentinel和redis集群配合完成,对调用方是透明的。
(5)【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
(6)【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
100亿数据1万属性数据架构设计
架构设计中常见“反向依赖”与解耦方案
总结
如何发现系统架构中不合理的“反向依赖”设计?
回答:
(1)变动方是A,配合方却是BCDE
(2)需求方是A,改动方确是BCDE
想想“换IP的是你,配合重启的却是我”,此时往往架构上可以进行解耦优化。
常见反向依赖及优化方案?
(1)公共库导致耦合
优化一:如果公共库是业务特性代码,进行公共库垂直拆分
优化二:如果公共库是业务共性代码,进行服务化下沉抽象
(2)服务化不彻底导致耦合
特征:服务中包含大量“根据不同业务,执行不同个性分支”的代码
优化方案:个性代码放到业务层实现,将服务化更彻底更纯粹
(3)notify的不合理实现导致的耦合
特征:调用方不关注执行结果,以调用的方式去实现通知,新增订阅者,修改代码的是发布者
优化方案:通过MQ解耦
(4)配置中的ip导致上下游耦合
特征:多个上游需要修改配置重启
优化方案:使用内网域名替代内网ip,通过“修改DNS指向,统一切断旧连接”的方式来上游无感切换
(5)下游扩容导致上下游耦合
特性:多个上游需要修改配置重启
典型数据库架构设计与实践
总结
文章较长,希望至少记住这么几点:
?业务初期用单库
?读压力大,读高可用,用分组
?数据量大,写线性扩容,用分片
?属性短,访问频度高的属性,垂直拆分到一起
架构设计和高并发系列
读书_大型网站技术架构01_李智慧
读书_大型网站技术架构02_李智慧
读书_大型网站技术架构03_李智慧
读书_高并发设计40问之一基础
读书_高并发设计40问之二数据库
读书_高并发设计40问之三缓存
读书_高并发设计40问之四消息队列
读书_高并发设计40问之五分布式服务
读书_w3c架构师01通用设计与方法论
读书_w3c架构师02典型架构实践
读书_w3c架构师03数据库与缓存
分布式事务
高并发之缓存
高并发之降级
高并发之限流
数据库_读写分离
消息队列_01消息队列入门
消息队列_02rabbitMQ入门
消息队列_03rabbitMQ安装和使用