数据库与缓存
数据库架构设计
概念一“单库”
概念二“分片”
分片解决的是“数据量太大”的问题,也就是通常说的“水平切分”。
一旦引入分片,势必有“数据路由”的概念,哪个数据访问哪个库。
路由规则通常有3种方法:
(1)范围:range
1 | 优点:简单,容易扩展 |
(2)哈希:hash
1 | 优点:简单,数据均衡,负载均匀 |
(3)路由服务:router-config-server
1 | 优点:灵活性强,业务与路由算法解耦 |
大部分互联网公司采用的方案二:哈希分库,哈希路由
概念三“分组”
分组解决“可用性”问题,分组通常通过主从复制的方式实现。
互联网公司数据库实际软件架构是:又分片,又分组
2.1如何保证数据的可用性?
解决可用性问题的思路是=>冗余
数据的冗余,会带来一个副作用=>引发一致性问题(先不说一致性问题,先说可用性)
如何保证数据库读高可用?
冗余读库:冗余读库带来的副作用?读写有延时,可能不一致
如何保证数据库写高可用?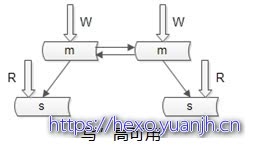
采用双主互备的方式,可以冗余写库
带来的副作用?双写同步,数据冲突(例如“自增id”同步冲突),
如何解决写同步冲突,有两种常见解决方案:
(1)两个写库使用不同的初始值,相同的步长来增加id:1写库的id为0,2,4,6…;2写库的id为1,3,5,7…
(2)不使用数据的id,业务层自己生成唯一的id,保证数据不冲突
2.2如何扩展读性能?
增加从库,这种方法大家用的比较多,但是,存在两个缺点:
(1)从库越多,同步越慢
(2)同步越慢,数据不一致窗口越大(不一致后面说,还是先说读性能的提高)
增加缓存
2.3如何保证一致性?
第一类不一致:主从数据库的一致性
(1)中间件
如果某一个key有写操作,在不一致时间窗口内,中间件会将这个key的读操作也路由到主库上。
这个方案的缺点是,数据库中间件的门槛较高(百度,腾讯,阿里,360等一些公司有,当然58也有)
第二类不一致,db与缓存间的不一致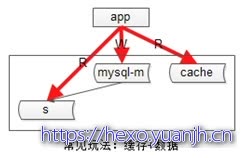
常见玩法:缓存+数据
常见的缓存架构如上
此时写操作的顺序是:
(1)淘汰cache
(2)写数据库
读操作的顺序是:
(1)读cache,如果cache hit则返回
(2)如果cache miss,则读从库
(3)读从库后,将数据放回cache
在一些异常时序情况下,有可能从【从库读到旧数据(同步还没有完成),旧数据入cache后】,数据会长期不一致。
解决办法是“缓存双淘汰”,写操作时序升级为:
(1)淘汰cache
(2)写数据库
(3)在经验“主从同步延时窗口时间”后,再次发起一个异步淘汰cache的请求
这样,即使有脏数据如cache,一个小的时间窗口之后,脏数据还是会被淘汰。带来的代价是,多引入一次读miss(成本可以忽略)。
架构设计和高并发系列
读书_大型网站技术架构01_李智慧
读书_大型网站技术架构02_李智慧
读书_大型网站技术架构03_李智慧
读书_高并发设计40问之一基础
读书_高并发设计40问之二数据库
读书_高并发设计40问之三缓存
读书_高并发设计40问之四消息队列
读书_高并发设计40问之五分布式服务
读书_w3c架构师01通用设计与方法论
读书_w3c架构师02典型架构实践
读书_w3c架构师03数据库与缓存
分布式事务
高并发之缓存
高并发之降级
高并发之限流
数据库_读写分离
消息队列_01消息队列入门
消息队列_02rabbitMQ入门
消息队列_03rabbitMQ安装和使用