问题
问题描述
官方介绍URL:
https://tianchi.aliyun.com/competition/information.htm?raceId=1
简单来说:根据用户30天(T-29到T日)和产品交互信息(浏览收藏加购购买)判断T+1日购买情况。
乍一看,有点蒙,预测问题至少给出需要预测的数据吧?我们负责填label。仔细想想其实是有给出的,对于T+1日购买的用户,如果用户id从未出现,显然我们也无从预测,所以我们需要处理的数据实际是“训练数据集中出现的“商品”和“用户”的组合”,用“商品”和“产品”的组合作为预测目标,但这个范围太大了,乘法,而且极其稀疏(看了不买的占绝大多数)。
再考虑下,其实不需要考虑用户从未交互过的产品,也就是认为T+1购买的产品,很大概率在前30日发生过交互(浏览,收藏等)的。这样可减少需预测的目标集合。但还是有点大,结合个人购物场景进一步思考,大部分时候,都是当天看完当天买(白天加购晚上下单),但是这部分需要T+1日的交互信息,无从得知,所以也无法预测。可预测仅是“用户前几日交互”完,T+1日买的。这时基本就清晰了,只需要把用户前2-3天的交互商品拿出来和用户组成pair就行了。再之前的概率就更小了,预测难度也会提高,所以可不予考虑,具体几天,需要实际分析
属于什么问题
买 or 不买,二分类问题
特征和目标label
给出的是用户和商品的交互情况,最简单的特征就是对其进行统计。一定时间(前N(1/24,3/24,12/24,1,2,4)天)的交互的类型频率统计及类型间数据比例(xx时间内,浏览/收藏/加购的总次数,除法得转化率)。目标label,T+1日的购买情况(T日晚24点为切分点,避免未来数据),只需取T日为15,16,17日就可以拿到不同的测试数据集合,也就是滑动窗口方式。
学习的特征和预测目标:T-N到T日的时间段的交互分类统计以及比例
举例:如预测15日购买情况,则14日24点切分数据,其中一张统计表大概是这样的。
表名:ui_1423_1424_stat(用户user和商品item关系,14日23点到14日24点,统计)
user item view coll cart buy label
u001 i001 12 5 2 0 1
u001 i002 13 4 3 1 0
会有多张表以时间切分的统计信息表,Label是根据15日是否购买打来的标签。
涉及技术
Python,Mysql(特征提取最初用mysql本地库,后发现速度太慢故迁到阿里云),机器学习特征提取,可视化,阿里云-数加平台(机器学习PAI)
数据准备
网上下载数据集,转存到Mysql数据库中,数据本身已经是按照含义切分后的数据,基本不需处理(之后迁移到阿里云上)。
特征提取和扩展
在扩展特征之前,先看看数据大概什么样的。分析前,还有些体力活,把csv文本数据存储到数据表中去。拿来主义了。
数据观察
点击购买比和日历效应
每日的点击,收藏,加购,购买的柱状图。观察有无异常日,同时注意有无周期特性(比如周末稍多)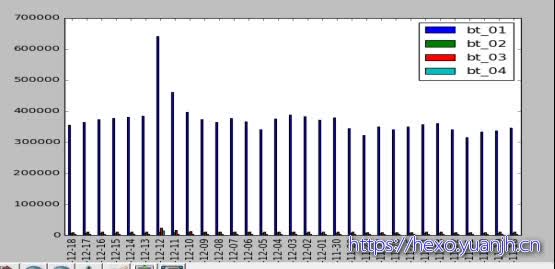
图01
最左侧最高蓝色柱的是浏览量,12号比较突出,简单处理的话可以考虑先去掉。同时注意到,数据是有周期的,波谷在12-05,11-28,11-21恰好都是周五,但12-05后不再明显,可能受双十二干扰。同时正负样本不均衡(全集蓝色柱子,有交互的,正例为购买的(最右侧bt_04,相差悬殊)。
把浏览的去掉,数据太多,干扰。去掉后如下
从左到右分别对应,收藏,加购,购买。还是12日比较异常,其他日数据基本平稳。同时,周五的波谷依然存在。从这里可以看出,对于每日的大约40W(万)交互只会产生4k(千)的购买量,1%的比例。收藏和加购物车也不过1w左右,2.5%的比例。而交互操作中大部分都是点击操作(type=1),使用加车和收藏可能会比点击更好。如果考虑对交互进行去重处理,40w将会变为16.5W左右浮动。此时购买比例为2.5%,收藏和加车比例为6.25%。 )
)
单用户数据异常(可能有机器人用户)
单用户的浏览,收藏,加购,购买,分别order排序下,观察有无异常过大的数据
浏览最高前10,可见73196588有问题,高浏览量但收藏,加购,购买都为0,简单处理,他的记录全部delete掉。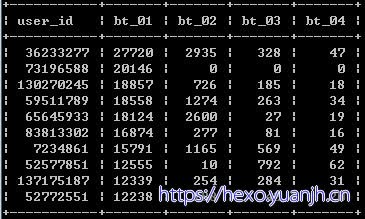
收藏前10和加购物车前10同样处理,较正常,不处理。
单用户的浏览/购买,收藏/购买,比值是否有异常数据
高”浏览/购买”,得到高比值数据中大部分都是未购买的,考虑到我们实际预测时更关注“购买”的情况,这些高浏览低购买的人可以删了,删除比值信息大于2000的。(37人,余1200万条记录,删除引起变化不大)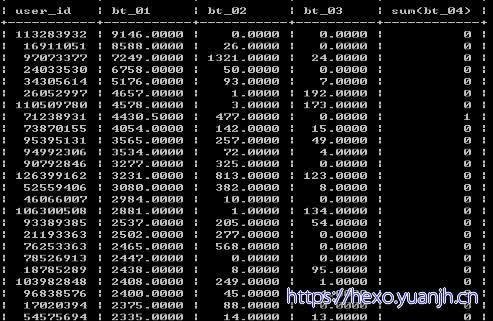
交互类型和购买是否有关联性
对16日购买的用户,14,15日交互情况统计
T日 T总购买 最晚T-1交互pair 最晚T-2 最晚T-3 近2日占比
1216 3771 2921 506 0 90.8%(2921+506)/3771
1215 3764 2873 621 138 92.82%(2873+621)/3764
1210 3216 2861 535 51 #todo和大于1?
1121 3021 2703 711 56 #todo和大于1?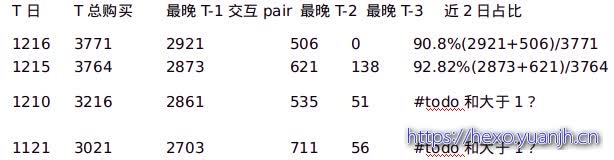
随着交互时间间隔增大,购买概率越来越小,较合常理。简单处理,只用预测日前2日(48h)的交互信息做预测。
特征扩展
特征可以分为以下几大类
1,用户特征:用户一定时间区间4种交互计数及比例,较重要的是相对购买的比例(用户交互转化率)
切分点最近1h用户的交互情况
Create table tud_u_1523_1524 Select user_id,sum(bt_01) as u_bt_01, sum(bt_02) as u_bt_02, sum(bt_03) as u_bt_03, sum(bt_04) as u_bt_04 sum(bt_01)/ (sum(bt_04)+1) as u_bt_0104, from train_user_dt where time>to_date(“201412152300”,”yyyymmddhhmmss”) and time<to_date(“201412152400”,”yyyymmddhhmmss”) group by t.user_id;
依次为1,2,3,5,8,13,21小时差
2,类别特征:类别一定时间区间的4种交互计数及比例,较重要也是相对购买的比例(类别交互转化率)
Create table tud_c_1523_1524 Select item_catagory,sum(bt_01) as c_bt_01, sum(bt_02) as c_bt_02, sum(bt_03) as c_bt_03, sum(bt_04) as c_bt_04 sum(bt_01)/ (sum(bt_04)+1) as c_bt_0104, from train_user_dt where time>to_date(“201412152300”,”yyyymmddhhmmss”) and time<to_date(“201412152400”,”yyyymmddhhmmss”) group by t.item_catagory;
3,商品特征:同上两类,时间区间计数及相对购买的比例
4,单交叉特征,用户-类别特征:一定时间用户对特定类别的交互计数,以及比例,重要的是购买比例
5,单交叉特征,用户-商品特征:同上,
6,二次交叉,用户类别-用户总类别:用户和特定类别交互占用户总类别交互的rank(用户视角那个商品重要)
7,二次交叉,用户商品-用户总商品特征:同上,用户视角那个类别重要
8,二次交叉,用户商品-用户次商品所属类别,用户交互此商品占用户此商品类别的排序(用户视角此商品占商品所在品类的排序)
9,时间截点信息,用户相对切分时间的最近的浏览时间(h),收藏,加购,购买时间。以及浏览,收藏,加购时间减购买时间(只要正负号即可)。
10,其他信息,交易时间距切分点的时间差x天y小时(原始时间对算法无意义,时间差有意义)
在提取特征时,由于我们需要离切分点最近的数据按照小区间的小时统计,较远的按照大区间统计,所以需要先划分好切分点再做特征提取。
最终预测目标:17日24点,切分,预测18日的购买情况。时间切分规则为
测试训练集合:16日24点,依次向前递推,多少自行决定(滑动窗口的话可以一直滑到起始日为开始日)。由于正负样本不均衡(从浏览和购买的那个柱状图“图01”可看出)所以尽可能多的提起样本数据,抽样后也保证足够数据量。
数据切分
采用滑动窗口采集数据
依次取时间切点为1119日24点,1110日24点,,,一直到1216日24点,其中去掉1211,1212,1213,1214日数据,避免双十二的干扰。
以时间切点为起点,对数据进行分箱。对类斐波那契数列[1,2,3,5,8,13,21],求和下[1,3,6,11,19,32,53]把53修改为48就是[1,3,6,11,19,32,48]。从时间切点回推,间隔1小时内的算第一个箱子,1-3小时的第二个箱子,,,类推,32-48的第7个箱子。将用户交互数据按照时间分箱进行汇总,计算各单一特征和交叉特征的取值。
数据整合
上一步得到各个时间分箱的汇总数据后,再将同一用户不同的时间箱的数据信息整合为一条记录作为训练数据,切分日次日的购买情况作为label,购买则1,未购买0。这样对每个切分日都可以得到一系列的user_id,item_id的特征和label集合。将不同切分日得到的数据进行汇总,就可以得到可训练的数据集合。
不均衡数据采样(及归一化)
对特征的观察看正负样本比例严重不均衡(考虑交互去重后也达到1:40),如果取的样本不是前2日而是前5,10日话不均衡可能会更加严重(越早的日期购买概率越低,等价分母变大,分子基本保持不变)。
数据采样可先对负样本下采样取1/10,这样正负样本可以变为1:4(后期调优阶段,可采用交叉验证进行测试)
直接使用阿里云上的工具进行采样处理了。
算法选择和集成
Todo训练和预测准确率召回率图像差异较大?为何
交叉验证
SVM和LR效果较差,不再列出了
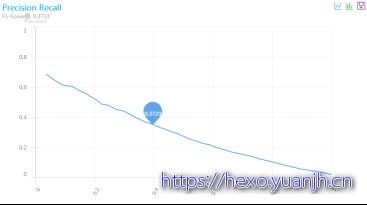
GBDT较好
其中:F0.3723,precision,0.35,recall0.4,auc0.90
相关评测截图如下 )
)
预测18日购买结果:
F0.0488,precision,0.035,recall0.37,auc0.81
相关截图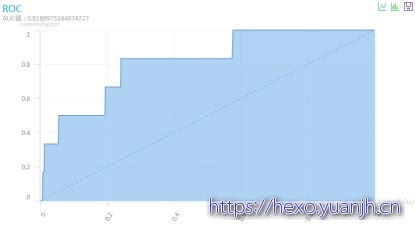 )
)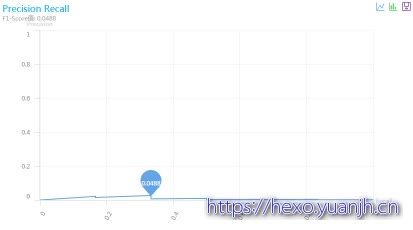
结果上看,存在过拟合的,训练数据上表现很好,但是预测时效果很差。
可进一步通过多次抽样,构造不同的gbdt模型,然后多模型投票进行处理。或降低gbdt迭代次数削弱过拟合。
归一化处理todo
模型集成-交叉验证取最佳
整体排名评估(TOP2.7%,100/3602)
整体评估不大好评估,阿里的平台早已关闭,平台赛的用户,商品数量会多很多,并且评估标准是限制了商品子集的(会提高召回率)。
根据其他用户当时离线赛截图(第4列F值,5列准确率(目前都是%的了)),4.8的F值排名应该在100名左右。
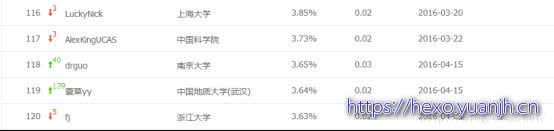
图片来源地址:http://blog.csdn.net/dr_guo/article/details/51130813
参考SQL
train_user_test :
create table train_user_test select * from train_user limit 500;
创建Train_user_bt
为了方便后续统计,先将train_user中的behavior_type转为列,bt_01,bt_02,bt_03,bt_04分别表示浏览,收藏,加购,购买。
Creat table train_user_bt
CREATE table train_user_test_bt
SELECT t.*,
if(behavior_type = ‘1’, 1, 0) AS bt_01,
if(behavior_type = ‘2’, 1, 0) AS bt_02,
if(behavior_type = ‘3’, 1, 0) AS bt_03,
if(behavior_type = ‘4’, 1, 0) AS bt_04,
left(time,10) as date
FROM train_user_test t
日统计浏览,收藏,加购,购买量
SELECT date,sum(bt_01),sum(bt_02),sum(bt_03),sum(bt_04)
FROM train_user_test_bt
GROUP BY date desc;
连接数据库统计绘图
1 |
|
单用户单特征观察
SELECT date,sum(bt_01) as bt_01,sum(bt_02) as bt_02,sum(bt_03) as bt_03,sum(bt_04) as bt_04 FROM train_user_test_bt GROUP BY user_id order by sum(bt_01) desc limit 10;
SELECT user_id,sum(bt_01)/(sum(bt_04)+1) as bt_01,sum(bt_02)/(sum(bt_04)+1) as bt_02,sum(bt_03)/(sum(bt_04)+1) as bt_03 FROM train_user_bt GROUP BY user_id desc order by sum(bt_01) desc limit 10;
异常数据删除
高浏览,无收藏,加购,购买:
Delete from train_user_bt where user_ id=’73196588’
删除高浏览/购物高于2000的用户的购买记录
create index train_user_bt_i_ui on train_user_bt(item_id,user_id);
DELETE FROM train_user_bt
WHERE user_id IN (SELECT t2.user_id FROM (SELECT t1.user_id,SUM(t1.bt_01) / (SUM(t1.bt_04) + 1) AS t1sum FROM train_user_bt t1 GROUP BY t1.user_id
) t2
WHERE t2.t1sum > 2000)
交互类型和购买是否有关联性
对16日购买的用户,14,15日交互情况统计
16日购买人数 最晚14人数 最晚15人数
3771 506 2921
可以看出随着交互时间间隔增大,购买概率越来越小(可测试15,14号等,不影响结论)。简单处理,只用预测日前2日(48h)的交互信息做预测。
参考sql
select count(*) from tianchi_mr_train_user_bt where bt_04=’1’ and datestr=’2014-12-16’;
SELECT count(*)
FROM
(SELECT *
FROM tianchi_mr_train_user_bt t1
WHERE t1.bt_04=’1’
AND t1.datestr=’2014-12-16’) tt1
LEFT outer JOIN
(SELECT *
FROM tianchi_mr_train_user_bt t2
WHERE t2.datestr=’2014-12-15’) tt2
ON tt1.user_id=tt2.user_id
AND tt1.item_id=tt2.item_id
SELECT sum(if(t2.behavior_type is null and t3.behavior_type is not null,
1,
0) )
FROM
(SELECT t1.user_id AS user_id,
t1.item_id AS item_id
FROM tianchi_mr_train_user_bt t1
WHERE t1.bt_04=’1’
AND t1.datestr=’2014-12-16’) tt1 left outer
JOIN tianchi_mr_train_user_bt t2
ON t2.datestr=’2014-12-15’
AND tt1.user_id=t2.user_id
AND tt1.item_id=t2.item_id left outer
join tianchi_mr_train_user_bt t3
备选基本ok
SELECT ttt1.user_id AS user_id,
ttt1.item_id AS item_id
FROM
(SELECT *
FROM
(SELECT t1.user_id AS user_id,
t1.item_id AS item_id
FROM tianchi_mr_train_user_bt t1
WHERE t1.bt_04=’1’
AND t1.datestr=’2014-12-16’)tt1 left outer
JOIN
(SELECT t2.user_id AS t2user_id,
t2.item_id AS t2item_id ,
t2.behavior_type AS t2behavior_type
FROM tianchi_mr_train_user_bt t2
WHERE t2.datestr=’2014-12-15’)tt2
ON tt1.user_id=tt2.t2user_id
AND tt1.item_id=tt2.t2item_id left outer
JOIN
(SELECT t3.user_id AS t3user_id,
t3.item_id AS t3item_id,
t3.behavior_type AS t3behavior_type
FROM tianchi_mr_train_user_bt t3
WHERE t3.datestr=’2014-12-14’)tt3
ON tt1.user_id=tt3.t3user_id
AND tt1.item_id=tt3.t3item_id ) ttt1
WHERE ttt1.t2behavior_type is null
AND ttt1.t3behavior_type is NOT null
ON t3.datestr=’2014-12-14’
AND tt1.user_id=t3.user_id
AND tt1.item_id=t3.item_id
mysqlTO阿里云数据迁移
本地数据迁移到阿里云
第一步
建立表train_user_bt,train_user_bt_min,tianchi_mr_train_item及数据导入
1,建立表train_user_bt,tianchi_mr_train_item
参考:create table tianchi_mr_train_item (item_id String, item_geohash String, item_catagory String):ok
吐槽下阿里的帮助有点乱,ddl的语法就很多小片段教程。
2,导入数据train_user_bt
2.1 本地数据导出到csv文件,
select * from train_user_bt
into outfile ‘d:/test.csv’
fields terminated by ‘,’
lines terminated by ‘\r\n’;
2.2 大概800M,上传太慢,压缩下。压缩后大约120M,尝试上传阿里云,悲剧,最大10M?
计划:a上传文件,b在线解压,c将文件导入数据表中
2.3 查阅相关文档,发现
阿里云的maxcomputer平台下,所有数据只接受table形式数据
如果csv能直接导入到云上的maxcomputer也ok。
安装配置客户端:https://help.aliyun.com/document_detail/27804.html?spm=5176.doc27815.6.565.Q1grXI
阿里云的maxcomputer有客户端,自己下载客户端,修改配置文件跑起来,
show tables,select * from xxx,目测和本地服务器一样。
在尝试下修改表名(rename to),创建类似表(like xx),drop表都ok。
2.4 试试把mysql导出的csv上传到这里,然后在控制台看看能否成功看到数据。
Tunnel命令操作:https://help.aliyun.com/document_detail/27833.html?spm=5176.doc51654.2.5.5VjYUG
参考上文执行:tunnel upload d:\test.csv tianchi_mr_train_user_bt;
个人理解,既然阿里封装为包形式后台在传输数据时应该是有压缩的(失望了,不是压缩后传的,800M传了4h,如果是压缩后的大约120M用不了那么久)
3,建立表train_user_bt_min,用来做sql正确性验证
create table tianchi_mr_train_user_bt_min like tianchi_mr_train_user_bt;
insert into table tianchi_mr_train_user_bt_min select * from tianchi_mr_train_user_bt limit 100000;
4,基础数据迁移到阿里云后,之前写好的特征提取的sql语句基本都不通了,需要重新适配阿里云的语法。这个改动较大,maxcomputer的数据表可能是基于hadoop的,无法对数据进行update操作。部分函数也要做调整。
其他参考信息:
DDL 语句:https://help.aliyun.com/document_detail/27862.html?spm=5176.doc27860.2.10.ERl6CE
日期函数(同栏目下的“内建函数”):https://help.aliyun.com/document_detail/48974.html?spm=5176.doc27860.6.651.ERl6CE
SQL 概要:https://help.aliyun.com/document_detail/27860.html?spm=5176.doc27804.2.4.3YSniS