读书笔记,《MySQL必知必会》。
第1章 了解SQL(略)
第2章 MySQL简介(略)
第3章 使用MySQL
连接mysql:mysql -h localhost -u root -p xxxx
查看信息show:
1 | show status; 用于显示广泛的服务器状态信息 |
第4章 检索数据
检索多个列:SELECTprod_id, prod_name,prod_price FROM products;
检索所有列:SELECT * FROM products;
检索去重,限制查询行数使用limit:SELECT DISTINCT vend_id FROM products LIMIT 2,3
第5章 排序检索数据
升序ASC(ASC可不用,默认是升序的)
多个列排序,先按名字再按id排序 SELECT prod_name,prod_price,prod_id FROM products ORDER BY prod_name,prod_id;
降序DESC
多个列降序DESC关键字只应用到直接位于其前面的列名 SELECT prod_name,prod_id FROM products ORDER BY prod_id DESC,prod_name;
第6章 过滤数据
样例:SELECT 字段 FROM 表名 WHERE 条件;
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小等于 |
| > | 大于 |
| > = | 大等于 |
| BETWEEN | 在指定的俩个值之间 |
第7章 数据过滤
组合WHERE子句:
AND操作符:SELECT prod_price,prod_name FROM products WHERE vend_id = 1003 AND prod_price <=10;
OR操作符:SELECT prod_price,prod_name FROM products WHERE vend_id = 1003 OR prod_price <=10;
计算次序:SELECT prod_price,prod_name,vend_id FROM products WHERE vend_id = 1003 OR vend_id = 1002 AND prod_price <=10;
SQL在处理OR操作符前,优先处理AND操作符,即操作符的优先级;
圆括号具有较AND或OR操作符的计算次序,DBMS首先过滤圆括号内的OR条件;
任何时候使用具有AND和OR操作符的WHERE子句,都应该使用圆括号明确地分组操作符;
IN操作符:SELECT prod_price,prod_name,vend_id FROM products WHERE vend_id IN (1002,1003) ORDER BY prod_name;
IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配;
IN用来制定要匹配值的清单,功能与OR相当;
使用长的合法选项清单时,IN操作符的语法更清楚更直观;
IN操作符一般比OR操作符清单执行更快;
IN的最大优点就是可以包含其他的SELECT语句,使得能够更动态的建立WHERE子句;
NOT操作符:SELECT prod_price,prod_name,vend_id FROM products WHERE vend_id NOT IN (1002,1003) ORDER BY prod_name;
NOT操作符,否定其之后的所跟的任何条件;
MySQL支持使用NOT对IN、BETWEEN、EXISTS子句取反,与多数其他DBMS允许使用NOT对各种条件取反有很大的差别;
第8章 用通配符进行过滤
LIKE操作符
百分号(%)通配符
在搜索串中,%表示任何字符出现任意次数[0,+∞]。(%不能匹配NULL)
SELECT prod_id,prod_name FROM products WHERE prod_name LIKE ‘jet%’;
下划线(_)通配符
下划线只匹配单个字符而不是多个字符。
SELECT prod_id,prod_name FROM products WHERE prod_name LIKE ‘_ ton anvil’;
通配符的处理一般比前述搜索所花时间更长。
不要过度使用通配符,尽量少使用;
在确实需要使用通配符时,除非绝对有必要,否则不要将他们用在搜索模式的开始处;
第9章 用正则表达式进行搜索
MySQL仅支持多数正则表达式的一个很小的子集。
基本字符匹配:SELECT prod_id,prod_name FROM products WHERE prod_name REGEXP ‘1000’;
匹配不区分大小写:
MySQL中的正则表达式匹配不区分大小写。为区分大小写,可使用BINARY关键字,如WHERE column_name REGEXP BINARY ‘string’
样例
1 | | //正则表达式的`OR`操作符,表示匹配其中之一。 |
第10章 创建计算字段
拼接(concatenate):将值联结到一起构成单个值。
SELECT Concat(vend_name,’(‘,vend_country,’)’ FROM vendors ORDER BY vend_name;
Concat()拼接串,即把多个串连接起来形成一个较长的串,各个串之间用逗号分隔;
Trim函数
1 | RTrim() //去掉串右边的所有空格 |
别名
别名(alias)是一个字段或值的替换名。别名用AS关键字赋予。
SELECT Concat(column_name1,column_name2) AS alias_name FROM table_name ORDER BY column_name;
执行算术计算
SELECT item_price, quantity * item_price AS 总价 FROM orderitems WHERE order_num = 20005;
MySQL算术操作符:+、-、*、/
第11章 使用数据处理函数
文本处理函数
1 | Left() //返回串左边的字符 |
日期和时间处理函数(略)
数值处理函数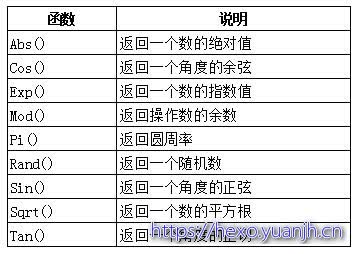
第12章 汇总数据
确定表中行数;获得表中行组的和;找出表列的最大值、最小值和平均值;
1 | AVG() //返回某列的平均值,忽略列值为NULL的行 |
COUNT()函数:
使用COUNT()对表中行的数目进行计数,*不管表列中包含的是空值NULL还是非空值;
使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值**
第13章 分组数据
样例:SELECT vend_id,COUNT() AS num_prods FROM Products GROUP BY vend_id;
除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出;
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前;
使用WITH ROLLUP关键字可以得到每个分组记忆*每个分组汇总级别的值**;(可以看做分组再次求sum)
过滤分组
WHERE过滤行,而HAVING过滤分组。
HAVING支持所有的WHERE操作符。
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。WHERE排除的行不包括在分组中,这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
第14章 使用子查询
子查询:SELECT cust_name, cust_contact FROM customers WHERE cust_id IN (SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id=’TNT2’));
对于嵌套的子查询的数目没有限制,不过在实际使用时由于性能的限制,不能嵌套太多的子查询。注意:列数据类型必须匹配。
第15章 联结表
样例:SELECT vend_name,prod_name,prod_price FROM vendors,products WHERE vendors.vend_id=products.vend_id ORDER BY vend_name,prod_name;
笛卡尔积(cartesian product),由没有联结条件的表关系返回的结果为笛卡尔积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
因此应该保证所有联结都有WHERE子句,且保证其正确性;
第16章 创建高级联结
别名
自联结,一般需要取别名
1 | SELECT p1.prod_id, p1.prod_name FROM products AS p1, products AS p2 WHERE p1.vend_id=p2.vend_id AND p2.prod_id='DTNTR'; |
自然联结
无论何时对表进行联结,应该至少有一个列出现在不止一个表中(被联结的列)。自然联结排除多次出现,使每个列只返回一次。
外部联结
1 | SELECT customers.cust_id,orders.order_num from customers INNER JOIN orders on customers.cust_id= |
在使用 OUTER JOIN 语法时,必须使用 RIGHT 或 LEFT 关键字
指定包括其所有行的表( RIGHT 指出的是 OUTER JOIN 右边的表,而 LEFT指出的是 OUTER JOIN 左边的表,谁是参照物)。上面的例子使用 LEFT OUTER JOIN 从 FROM子句的左边表( customers 表)中选择所有行。为了从右边的表中选择所有行,应该使用 RIGHT OUTER JOIN。
第17章 组合查询
UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过分析各个列不需要以相同的次序列出)。
列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
UNION从查询结果集中自动去除了重复的行使用UNION ALL可保留重复行
对组合查询结果排序
SELECT语句的输出用ORDER BY子句排序。在用UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。
1 | SELECT vend_id,prod_id,prod_price |
第18章 全文本搜索
最常见的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。
启用全文本搜索支持
一般在创建表时启用全文本搜索。CREATE TABLE语句接受FULLTEXT子句,它给出被索引列的一个逗号分隔的列表。
1 | CREATE TABLE productnotes |
进行全文本搜索
索引之后,使用俩个函数Match()和Against()执行全文搜索,其中Match()指定被搜索的列,Against()指定要使用的搜索表达式
1 | SELECT note_text |
传递给March()的值必须与FULLTEXT()定义中的相同。如果指定多个列,则必须列出它们(而且次序正确);
除非使用BINARY方式,否则全文本搜索不区分大小写;
全文搜索的一个重要部分就是对结果排序,具有较高等级的行先返回;
如果指定多个搜索项,则包含多数匹配词的那些行将具有比包含较少词的那些行高的等级值;
使用查询扩展(查询扩展用来设法放宽所返回的全文搜索结果的范围,略)
布尔文本搜索(略)
全文本布尔操作符(略)
第19章 插入数据
插入单行
1 | INSERT INTO customers(cust_name,cust_address,cust_state,cust_zip,cust_country,cust_email) |
如果表的定义允许,则可以在INSERT操作中省略某些列。
省略的列必须满足以下某个条件:
1 | 该列定义为允许NULL值(无值或空值); |
插入多行
1 | INSERT INTO customers(cust_name,cust_address,cust_state,cust_zip,cust_country,cust_email) |
插入检索出的数据
1 | INSERT INTO customers(cust_id,cust_contact,cust_address,cust_state,cust_zip,cust_country,cust_email) |
第20章 更新和删除数据
update: 一定要注意确定要更新的条件。
更新表中特定行:UPDATE customers SET cust_name=’The Fudds’, cust_email=’elmer@fudd.com’ WHERE cust_id=10005;
如果删除某个列的值,可以set xxx=null;
IGNORE关键字:如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个UPDATE操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。为即使是发生错误,也继续进行更新,可使用IGNORE关键字,如下:UPDATE IGNORE customers
delete:一定要注意确定要删除的条件
删除表中特定的行:DELETE FROM customers WHERE cust_id = 10006;
删除表中所有的行:delete from tablename;
truncate tablename; 这种完成相同的工作,但是效率更高,它是删除原来的表在重新创建一个,而不是一行一行的删除
特殊注意:
在对UPDATE或DELETE语句使用WHERE子句前,应该先用SELECT进行测试,保证它过滤的是正确的记录,以防编写的WHERE子句不正确。
使用强制实施引用完整性的数据库(关于这个内容,请参阅第15章),这样MySQL将不允许删除具有与其他表相关联的数据的行
第21章 创建和操纵表
表创建样例:
1 | CREATE TABLE customers |
特殊注意:
表的主键可以在创建表时用PRMARY KEY关键字指定;
如果仅仅想在一个表不存在时创建,应该在表名后给出IF NOT EXISTS;
允许NULL值的列也允许在插入行时不给出该列的值。不允许NULL值的列不接受该列没有值的行,即在插入或更新行时,该列必须有值;
主键为其值唯一标识表中每个行的列。主键只允许使用不允许NULL值的列;
每个表只允许一个AUTO_INCREMENT列,而且它必须被索引;
默认值用CREATE TABLE语句的列定义中的DEFAULT关键字指定;
与大多数DBMS不一样,MySQL不允许使用函数作为默认值,它只支持常量;
引擎类型
InnoDB是一个可靠的事务处理引擎,不支持全文索引;
MEMORY在功能等同于MyISAM,但由于数据存储在内存中,速度很快(适合于临时表);
MyISAM是一个性能极高的引擎,支持全文索引,但不支持事物;
外键不能跨引擎,即使用一个引擎的表不能引用具有使用不同引擎的表的外键。
更新表
新增字段:ALTER TABLE vendors ADD vend_phone CHAR(20);
定义外键:ALTER table 表名 add constraint FK_ID foreign key(外键字段名) references 外表表名(主键字段名)
删除表:DROP TABLE table_name;
重命名表:RENAME TABLE table_name TO new_table_name;
第22章 使用视图
常见应用:
1 | 重用SQL语句; |
用视图重新格式化检索
1 | CREATE VIEW vendorlocation AS |
使用视图过滤不想要的数据
1 | CREATE VIEW customereamillist AS |
更新视图
视图是可更新的,更新一个视图将更新其基表。如果你对视图增加或者删除行,实际上是对其基表增加或删除行。
但如果视图定义中有以下操作,则不能进行视图的更新:
1 | 分组(使用GROUP BY和HAVING); |
第23章 使用存储过程
存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。可将其视为批文件,虽然他们的作用不仅限于批处理。
使用存储过程的好处:简单、安全、高性能
1 | 通过把处理封装在容易使用的单元中,简化复杂的操作; |
缺陷
1 | 存储过程的编写比基本SQL语句复杂,编写存储过程需要更高的技能,更丰富的经验; |
由于目前大多数框架基于orm模型,不建议使用存过。所以不在详述。
第24章 使用游标
游标(cursor)是一个存储在MySQL服务器上的数据库查询,它不是一个SELECT语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
MySQL游标只能用于存储存储过程(和函数)。由于存过已经不建议使用了,所以游标也不详述了。
第25章 使用触发器
想要某条语句(或某些语句)在事件发生时自动执行
常见的:DELETE;INSERT;UPDATE;
由于触发器使用时存在一些限制,比如:
触发器按每个表每个事件每次地定义,每个表每个事件只允许一个触发器;
即每个表最多支持6个触发器
实际开发中一般使用orm+事务实现,所以也不详述。
第26章 管理事务处理
事务处理(transaction processing)可以用来维护数据库的完整性,它保证成批的MySQL操作要么完全执行,要么完全不执行。
相关术语:
事务(transaction):指一组SQL语句;
回退(rollback):指撤销指定SQL语句的过程;
提交(commit):指将未存储的SQL语句结果写入数据库表;
保留点(savepoint):指事务处理设置的临时占位符(placeholder),可以对其发布回退;
目前使用较多的功能,orm+事务作为开发中高频使用的组合。
事务开始:START TRANSACTION;
事务回滚:ROLLBACK:
1 | SELECT * FROM ordertotals; |
注意:
事务处理可以用来管理INSERT/UPDATE/DELETE语句;
不能回退SELECT语句,无意义,不能回退CREATE/DROP操作;
事务处理中可以使用CREATE/DROP,但这俩条语句不能执行回退;
事务提交:COMMIT
隐含提交(implicit commit),即提交操作是自动进行的。
但是在事务处理块中,提交不会隐含地执行。为进行明确的提交,使用COMMIT语句:
1 | START TRANSACTION; |
注意:
COMMIT语句仅在不出错时写出更改,否则事务会被撤销;
当COMMIT或ROLLBACK语句执行后,事务会自动关闭;
使用保留点
简单的ROLLBACK和COMMIT语句可以写入或撤销整个事务处理。但是对于复杂的事务处理,需要部分提交或回退。
更改默认的提交行为
默认的MySQL行为是自动提交所有更改的。
为了指示MySQL不自动提交更改,需使用语句:SET autocommit=0;
第27章 全球化和本地化
显示所有可用的字符集以及每个字符集的描述和默认校对:SHOW CHARACTER SET;
查看所支持校对的完整列表以及它们适用的字符集:SHOW COLLATION;
第28章 安全管理(略)
第29章 数据库维护
备份数据
使用命令行实用程序mysqldump转储所有数据库内容到某个外部文件。在进行常规备份前,这个实用程序应该正常运行,以便能正确地备份转储文件。
可用命令行实用程序mysqlhotcopy从一个数据库复制所有数据(并非所有数据库引擎都支持这个实用程序);
可以使用MySQL的BACKUP TABLE或SELECT INTO OUTFILE转储所有数据到某个外部文件。这俩条语句都接收将要创建的系统文件名,此系统文件必须不存在,否则会报错。数据可以用RESTORE TABLE来复原。
为了保证所有数据被写到磁盘(包括索引数据),可能需要在进行备份前使用FLUSH TABLES(内存刷入磁盘)语句(防止备份时候有新数据写入,且备份的是最新的:FLUSH TABLES WITH READ LOCK)。
进行数据库维护
诊断启动问题
主要日志文件
错误日志:它包含启动和关闭问题以及任意关键错误的细节。此日志通常名为 hostname.err, 位于data目录中,此日志名可用 –log-error命令更改。
查询日志:它记录所有MySQL活动,在诊断问题时非常有用。此日志文件可能会很快地变得非常大,因此不应该长期使用它。此日志通常名为hostname.org,位于data目录中,此名字可以用 –log命令更改。
二进制日志:它记录更新过数据的所有语句。此日志通常名为hostname-bin,位于data目录内。此名字可以用–log-bin命令更改。
缓慢查询日志:顾名思义,此日志记录执行缓慢的任何查询。这个日志在确定数据库何处需要优化很有用。此日志通常名为hostname-slow.log,位于data目录中,此名字可以用 –log-slow-queries命令更改.
在使用日志时,可用flush logs语句来刷新和重新开始所有日志文件。
第30章 改善性能
关键点
1 | MySQL是用一系列的默认配置预先配置的,这些设置开始通常是很好的。但过一段时间后可能需要调整内存分配、缓冲区大小等。(查看当前设置,可使用SHOW VARIABLES;和SHOW STATUS;); |