练手作Titanic
数据概览
图1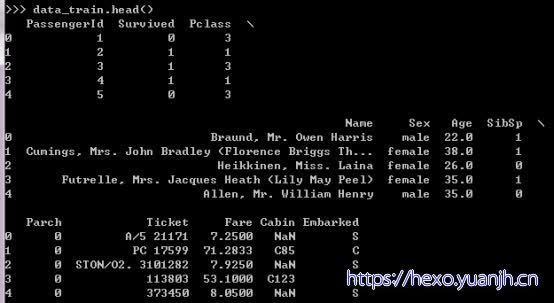
图2
图3
各字段含义:
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
数据清理
数据取值范围合理,单一数据源无需担心单位问题。
未发现明显矛盾或异常数据。若处理过程中发现在实时处理。
数据预处理
数据概览观察
(规则(离散程度和数据类型)-onehotor转仅转数值,缺失情况-缺失值填充,取值范围-归一化)
id类型数据:prasengerid,name,ticket,cabin(高缺失),
01数据:(servived是label不考虑)
低离散数据/取值:pClass_数值_(1-3),sibsp,parch,embarked,sex,
高离散Int(float)数据:Age(0.42-80)
高离散float数据:fare(0-512.0)
Serviver_mean:生还率38%
各属性处理方式:
id类型数据:无法直接使用,提取特征后使用。
Prasengerid:
Name:提取男女信息。
Ticket:
Cabin:数据缺失严重,考虑是否缺失作为特征。
01数据:
Sex:onehot化
(servived是label不考虑))
低离散数据/数值:onehot化
pClass(1-3),sibsp,parch,embarked,
高离散Int(float)数据:LR算法不用处理
Age(0.42-80):归一化
高离散float数据:LR算法不用处理
fare(0-512.0):归一化
由于计划采用LR算法,sex需要onehot化避免数值大小引入干扰(同理,其他数据采用类似模式,低离散属性都onthot化,多引入个别维度无关紧要)。
单维度数据观察
01数据:数值化后柱状图
sex
低离散数据/取值:数值化后柱状图
pClass(1-3),sibsp,parch,embarked,Sex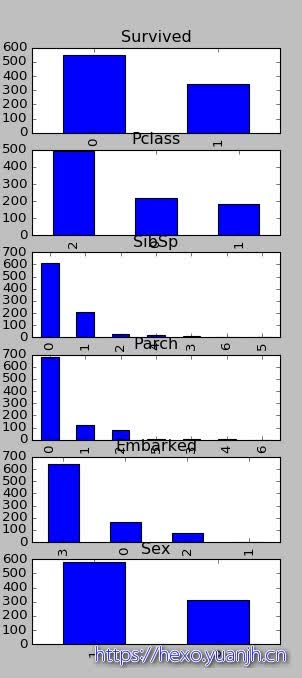
高离散Int(float)数据:分布图
Age(0.42-80)
高离散float数据:分布图
fare(0-512.0)
结论:无明显异常。
属性和label相关性分析

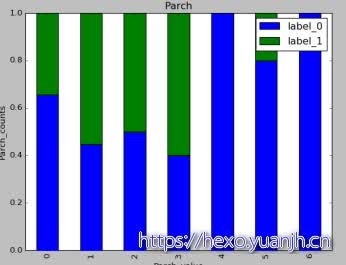
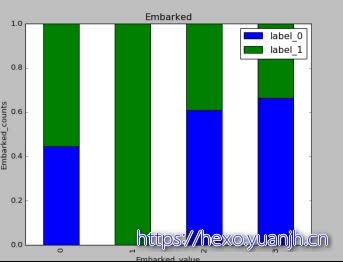


由于上面属性已经做了emun枚举转数值,所以无法看到特征具体取值,但是无妨,我们只关注数据是否存在相关性。上面数据属性分布来看与label都存在着一定相关性。
Label与Age,Fare连续数值的分布相关性。无法直接看出是否有关联,可以参考离散数据模型进行分析
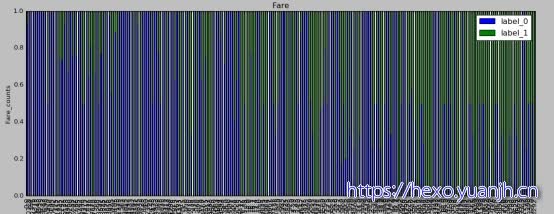
可见Age属性在取值较低时确实具有相对的优势,(绿色分布较多)。Age较高区间蓝色分布较密集。但是这个实际使用未必效果佳,原因是Age的分布对于低年龄和高年龄都是稀疏的。25岁左右较高。但25岁左右时分布较为平均。而Fare属性目测没啥用了,一方面分布较为集中,另一方面颜色图中也未有明显信息。
前面遗漏了一步,在特征分析前应当对单特征做归一化,典型的Age和Fare。
代码实现
第一版:代码逻辑和结果评估(7244/8759)
根据前面分析
最初版本的代码逻辑
1,单特征观察
2,特征和label关联关系观察
3,数据归一化,Age,Fare
4,属性的onehot处理。’Embarked’,’Sex’,’Pclass’(字段名为前缀进行扩展)
5,直接使用SibSp,Parch
(test集合也按照上述数据处理逻辑进行处理)
代码详见:github

第二版:Age预测填充,Cabin二元特征
部分字段第一版未考虑:
PassengerId => 乘客ID:无法使用
Name => 乘客姓名:无法使用
Ticket => 船票信息:无法使用
Cabin => 客舱:缺失过于严重,可以将是否缺失作为01特征加入。
这些字段可以考虑进去,
还有字段可以更好的使用,比如Age缺失大约200个,可以考虑用回归的方法进行缺失值填充。
观察模型的各个系数
记录
(from:http://blog.csdn.net/han_xiaoyang/article/details/49797143)
我们先看看那些权重绝对值非常大的feature,在我们的模型上:
Sex属性,如果是female会极大提高最后获救的概率,而male会很大程度拉低这个概率。
Pclass属性,1等舱乘客最后获救的概率会上升,而乘客等级为3会极大地拉低这个概率。
有Cabin值会很大程度拉升最后获救概率(这里似乎能看到了一点端倪,事实上从最上面的有无Cabin记录的Survived分布图上看出,即使有Cabin记录的乘客也有一部分遇难了,估计这个属性上我们挖掘还不够)
Age是一个负相关,意味着在我们的模型里,年龄越小,越有获救的优先权(还得回原数据看看这个是否合理)
有一个登船港口S会很大程度拉低获救的概率,另外俩港口压根就没啥作用(这个实际上非常奇怪,因为我们从之前的统计图上并没有看到S港口的获救率非常低,所以也许可以考虑把登船港口这个feature去掉试试)。
船票Fare有小幅度的正相关(并不意味着这个feature作用不大,有可能是我们细化的程度还不够,举个例子,说不定我们得对它离散化,再分至各个乘客等级上?)
进一步考虑特征挖掘:
(from:http://blog.csdn.net/han_xiaoyang/article/details/49797143)
我们随便列一些可能可以做的优化操作:
Age属性不使用现在的拟合方式,而是根据名称中的『Mr』『Mrs』『Miss』等的平均值进行填充。
Age不做成一个连续值属性,而是使用一个步长进行离散化,变成离散的类目feature。
Cabin再细化一些,对于有记录的Cabin属性,我们将其分为前面的字母部分(我猜是位置和船层之类的信息) 和 后面的数字部分(应该是房间号,有意思的事情是,如果你仔细看看原始数据,你会发现,这个值大的情况下,似乎获救的可能性高一些)。
Pclass和Sex俩太重要了,我们试着用它们去组出一个组合属性来试试,这也是另外一种程度的细化。
单加一个Child字段,Age<=12的,设为1,其余为0(你去看看数据,确实小盆友优先程度很高啊)
如果名字里面有『Mrs』,而Parch>1的,我们猜测她可能是一个母亲,应该获救的概率也会提高,因此可以多加一个Mother字段,此种情况下设为1,其余情况下设为0
登船港口可以考虑先去掉试试(Q和C本来就没权重,S有点诡异)
把堂兄弟/兄妹 和 Parch 还有自己 个数加在一起组一个Family_size字段(考虑到大家族可能对最后的结果有影响)
Name是一个我们一直没有触碰的属性,我们可以做一些简单的处理,比如说男性中带某些字眼的(‘Capt’, ‘Don’, ‘Major’, ‘Sir’)可以统一到一个Title,女性也一样。
大家接着往下挖掘,可能还可以想到更多可以细挖的部分。我这里先列这些了,然后我们可以使用手头上的”train_df”和”cv_df”开始试验这些feature engineering的tricks是否有效了。
过拟合欠拟合
理想的训练-测试在规模越来越大时图像如下所示,可以看出随着数据的增大,测试集总误差越来越大(主要样本增多的缘故),测试集总误差越来越小(学习到模型知识越充分)。并且二者有合并的趋势(在训练和测试上的误差越来越小,有合并趋势)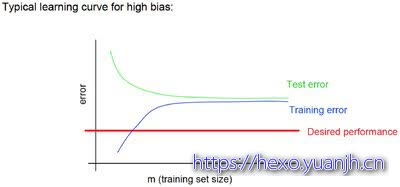
过拟合时曲线如下
随着数据规模的增长,训练规模越大在测试集上的误差总是高于预测集合,并且合并效果并不明显(可以看出有明显的分隔带)
借用他人博客中代码绘图: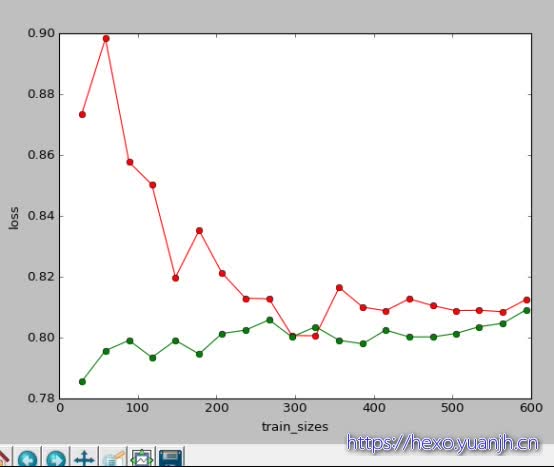
可见对于此模型,随着数据规模增长,训练数据和测试数据的误差越来越趋向于交叉,所以可以认为并没有过拟合的现象。
模型融合
修改代码:
clf = linear_model.LogisticRegression(C=1.0, penalty=’l1’, tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
使用bagging_clf进行训练,预测,结果为
结果反而下降了,额。
参考文献
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾:http://blog.csdn.net/han_xiaoyang/article/details/49797143
Basic Feature Engineering with the Titanic Data:
https://triangleinequality.wordpress.com/2013/09/08/basic-feature-engineering-with-the-titanic-data/
todo:别人思路代码学习
https://www.kaggle.com/c/titanic/kernels
todo代码实现:
用Pandas作图:http://www.360doc.com/content/16/0223/21/7249274_536782559.shtml
Todo查询:parallel_coordinates,andrews_curves,radviz
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾:http://blog.csdn.net/han_xiaoyang/article/details/49797143
Titanic best working Classifier:
https://www.kaggle.com/sinakhorami/titanic-best-working-classifier
结果:
Introduction to Ensembling/Stacking in Python
https://www.kaggle.com/arthurtok/introduction-to-ensembling-stacking-in-python