数组(Array)
和C中的数组相比,又是有一些不同的
- Go中的数组是值类型,换句话说,如果你将一个数组赋值给另外一个数组,那么,实际上就是将整个数组拷贝一份
- 如果Go中的数组作为函数的参数,那么实际传递的参数是一份数组的拷贝,而不是数组的指针。这个和C要区分开。因此,在Go中如果将数组作为函数的参数传递的话,那效率就肯定没有传递指针高了。
- array的长度也是Type的一部分,这样就说明[10]int和[20]int是不一样的。
数组的声明
声明举例:数组创建时, 被初始化为元素类型的零值.1
2
3
4
5
6
7
8
9var arr [10]int // 长度为 10 的数组, 默认所有元素是 0
arr := [...]int{1, 2, 3} // 长度由初始化元素个数指定, 这里长度是 3
arr := [...]int{11: 3} // 长度为 11 的数组, arr[11] 初始化为 3, 其他为 0
arr := [5]int{1,2} // 长度为 5 的数组, 前两位初始化为 1, 2
arr := [...]int{1: 23, 2, 3: 22} // 长度为 4 的数组, 初始化为 [0 23 2 22]
[length]Type
[N]Type{value1, value2, ... , valueN}
[...]Type{value1, value2, ... , valueN}长度为 0 的数组
长度为 0 的数组. 这种不占有任何内存空间的数据类型实际上是无意义的, 所以 Go 语言对此类数据特殊处理了一下, 此外还包括 struct{}, [10]struct{} 等.前 5 个变量的内存地址一样, 第 6 个变量 f 有一个真实可用的内存. 也就是说 Go 并没有为 [0]int 和 struct{} 这类数据真正分配地址空间, 而是统一使用同一个地址空间.1
2
3
4
5
6
7
8
9
10
11
12var (
a [0]int
b struct{}
c [0]struct {
Value int64
}
d [10]struct{}
e = new([10]struct{}) // new 返回的就是指针
f byte
)
fmt.Printf("%p, %p, %p, %p, %p, %p", &a, &b, &c, &d, e, &f)
// 0x1127a88, 0x1127a88, 0x1127a88, 0x1127a88, 0x1127a88, 0xc42000e280
这类数据结构在 map 中经常应用, 比如 map[string]struct{}. 声明这样一个 map 类型来标记某个 key 是否存在. 在 key 值很多的情况下, 要比 map[string]bool 之类的结构节约很多内存, 同时也减小 GC 压力.
数组作为函数参数
func(arr [3]int) 内部对 arr 进行修改是否会影响外面的实际值. 答案是不会.
因为一个数组作为参数时, 会拷贝一份副本作为参数, 函数内部操作的数组与外界数组, 在内存中根本就不是同一个地方. 是值传递不是引用传递, 这点可能和某些语言不同.
看下面代码:
1 | array := [3]int{1, 2, 3} |
函数内外, 数组的内存地址都不一样, 自然不会有影响.
如果你想让函数直接修改, 可以使用指针, 即 func(arr *[3]int).
数组是值类型
在 Go 中数组是值类型而不是引用类型。这意味着当数组变量被赋值时,将会获得原数组的拷贝。新数组中元素的改变不会影响原数组中元素的值。
切片(Slice)
slice 在 Go 内部的定义.
1 | type slice struct { |
创建
切片的创建有4种方式:
1 | 1)make ( []Type ,length, capacity ) |
slice 越界
1 | arr := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} |
对 slice 的操作记住两点:
01,数据直接访问(slice[index])时, index 值不能超过 len(slice) 范围
02,创建切片(slice[start:end])时, start 和 end 指定的区间不能超过 cap(slice) 范围
append 函数
很多人以为 slice 是可以自动扩充的, 估计都是 append 函数误导的. 其实 slice 并不会自己自动扩充, 而是 append 数据时, 该函数如果发现超出了 cap 限制自动帮我们扩的.
当执行 append(slice, v1, v2) 时, append 函数会先检查执行结果的长度是否会超出 cap(slice).
如果超出, 就先 make 一个更长的 slice, 然后把整个 slice 都 copy 到新 slice 中, 再进行 append.
如果没超, 直接以 len(slice) 为起始点进行追加, len(slice) 会随着 append 操作不断扩大, 直到达到 cap(slice) 进行扩充.
建议使用者尽可能的避免让 append 自动为你扩充内存. 一个是因为扩充时会出现一次内存拷贝, 二是因为 append 并不知道需要扩充多少, 为了避免频繁扩充, 它会扩充到 2 * cap(slice) 长度. 而有时我们并不需要那么多内存.
nil 和空切片
1 | // 创建 nil 整型切片 |
nil 切片可以用于很多标准库和内置函数。在需要描述一个不存在的切片时,nil 切片会很好用。比如,函数要求返回一个切片但是发生异常的时候。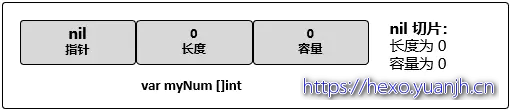
空切片的底层数组中包含 0 个元素,也没有分配任何存储空间。想表示空集合时空切片很有用,比如,数据库查询返回 0 个查询结果时。下图描述了空切片的状态
不管是使用 nil 切片还是空切片,对其调用内置函数 append()、len() 和 cap() 的效果都是一样的。
共享底层数组的切片
需要注意的是:现在两个切片 myNum 和 newNum 共享同一个底层数组。如果一个切片修改了该底层数组的共享部分,另一个切片也能感知到
切片只能访问到其长度内的元素
切片只能访问到其长度内的元素,试图访问超出其长度的元素将会导致语言运行时异常。在使用这部分元素前,必须将其合并到切片的长度里。
切片扩容
相对于数组而言,使用切片的一个好处是:可以按需增加切片的容量。
函数 append() 总是会增加新切片的长度,而容量有可能会改变,也可能不会改变,这取决于被操作的切片的可用容量。
函数 append() 会智能地处理底层数组的容量增长。在切片的容量小于 1000 个元素时,总是会成倍地增加容量。一旦元素个数超过 1000,容量的增长因子会设为 1.25,也就是会每次增加 25%的容量(随着语言的演化,这种增长算法可能会有所改变)。
内置函数 append() 在操作切片时会首先使用可用容量。一旦没有可用容量,就会分配一个新的底层数组。这导致很容易忘记切片间正在共享同一个底层数组。一旦发生这种情况,对切片进行修改,很可能会导致随机且奇怪的问题,这种问题一般都很难调查。如果在创建切片时设置切片的容量和长度一样,就可以强制让新切片的第一个 append 操作创建新的底层数组,与原有的底层数组分离。
1 | myFruit := fruit[2:3:3] |
内存优化
切片保留对底层数组的引用。只要切片存在于内存中,数组就不能被垃圾回收。这在内存管理方便可能是值得关注的。假设我们有一个非常大的数组,而我们只需要处理它的一小部分,为此我们创建这个数组的一个切片,并处理这个切片。这里要注意的事情是,数组仍然存在于内存中,因为切片正在引用它。
解决该问题的一个方法是使用 copy 函数 func copy(dst, src []T) int 来创建该切片的一个拷贝。这样我们就可以使用这个新的切片,原来的数组可以被垃圾回收。
切片只能向后移动,s2 = s2[-1:] 会导致编译错误。切片不能被重新分片以获取数组的前一个元素。
注意 绝对不要用指针指向 slice。切片本身已经是一个引用类型,所以它本身就是一个指针!!
数组声明和切片声明
二者的区别是:如果在 [] 运算符里指定了一个值,那么创建的就是数组而不是切片。只有在 [] 中不指定值的时候,创建的才是切片。看下面的例子:
1 | // 创建有 3 个元素的整型数组 |
数组和切片的区别
● 切片是指针类型,数组是值类型
● 数组的长度是固定的,而切片不是(切片是动态的数组)
● 切片比数组多一个属性:容量(cap)
● 切片的底层是数组
所以,a、b定义的是数组类型,数组对比是相同的
但是,a[:]、b[:]是切片,切片之间不能进行等值判断,只能和nil判断
new() 和 make() 的区别
看起来二者没有什么区别,都在堆上分配内存,但是它们的行为不同,适用于不同的类型。
new(T) 为每个新的类型T分配一片内存,初始化为 0 并且返回类型为*T的内存地址:这种方法 返回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体(参见第 10 章);它相当于 &T{}。
make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel(参见第 8 章,第 13 章)。
换言之,new 函数分配内存,make 函数初始化;下图给出了区别: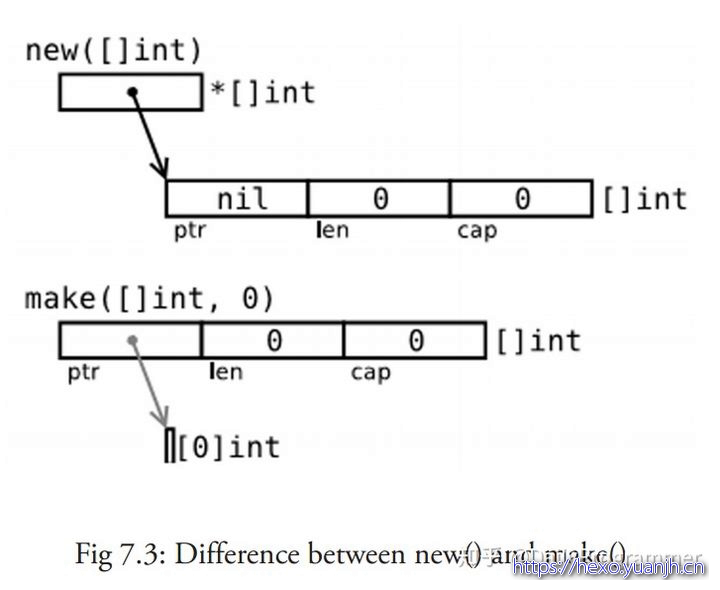
new 和 make 主要区别如下:
make 只能用来分配及初始化类型为 slice、map、chan 的数据。new 可以分配任意类型的数据;
new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
new 分配的空间被清零。make 分配空间后,会进行初始化;
参考
golang(Go语言)中的数组(Array)与切片(Slice):https://blog.csdn.net/weixin_42117918/article/details/100130648
Golang 入门 : 切片(slice):https://www.jianshu.com/p/354fce23b4f0
GO语言总结(3)——数组和切片:https://www.cnblogs.com/zrtqsk/p/4148495.html
Golang教程:数组和切片:https://www.cnblogs.com/liuzhongchao/p/9159896.html
go语言中数组和切片的区别:https://blog.csdn.net/belalds/article/details/80076739
go语言中数组和切片的区别是什么?:https://www.php.cn/be/go/465817.html
make和new关键字的区别及实现原:https://www.cnblogs.com/lurenq/p/12013250.html
go入门系列
入门02_IDE安装
入门03_工具链
入门04_入门demo和基本类型
入门05_go升级版本
入门06_教程biancheng
入门08_教程编程时光
入门09_Go语言高级编程
入门10_包导入
入门11_方法接口和嵌入类型
入门12_数组和切片