最大收获在于代码可读性切分,以及变量命名的合理。需求驱动的模块划分 :一般是有公用方法才提出独立func,没有的话就大段代码堆积,除非非常长的代码,影响阅读效果,才会考虑切分。可读性驱动的模块划分 :request更多偏向于“注释型切分”,按照功能角色进行切分,哪怕只有几行代码,如果是独立小block,也会抽取出独立函数,通过函数名标识代码块功能,所以代码即使不看注释也很容易读懂(当然,request模块本身代码注释也很完善)。
基础 功能 request可以看做基于urllib3的二次封装 ,使得其更易用,所以本身逻辑性代码并不多,很多代码是异常处理或者兼容性处理和注释等。urllib、urllib2、urllib3的关系
1 2 3 urllib和urllib2是独立的模块,并没有直接的关系,两者相互结合实现复杂的功能 urllib和urllib2在python2中才可以使用 requests库中使用了urllib3(多次请求重复使用一个socket)
支持功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Feature Support --------------- Requests is ready for today's web. - International Domains and URLs #国际化域名和URLS - Keep-Alive & Connection Pooling #keep—Alive&连接池 - Sessions with Cookie Persistence #持久性cookie的会话 - Browser-style SSL Verification #浏览器式SSL认证 - Basic/Digest Authentication #基本/摘要认证 - Elegant Key/Value Cookies #简明的key/value cookies - Automatic Decompression #自动解压缩 - Automatic Content Decoding #自动内容解码 - Unicode Response Bodies #Unicode响应体 - Multipart File Uploads #文件分块上传 - HTTP(S) Proxy Support #HTTP(S)代理支持 - Connection Timeouts #连接超时 - Streaming Downloads #数据流下载 - `.netrc` Support #'.netrc'支持 - Chunked Requests #Chunked请求
代码量
可见comment和代码比例为1936:5852=1:3左右,开源代码大多数注释比较完备。
模块 网络请求参数类,包括 Request 和 PrepareRequest
深度阅读,调用链
随便找一个requests.get()阅读,依次跟进各函数,就可以得到核心函数表,借此表,可得知各模块在request请求里的调用次序和功能角色。
广度阅读,模块简析
1 2 3 4 5 6 7 8 9 10 11 12 def dispatch_hook(key, hooks, hook_data, **kwargs): """Dispatches a hook dictionary on a given piece of data.""" hooks = hooks or {} hooks = hooks.get(key) if hooks: if hasattr(hooks, '__call__'): hooks = [hooks] for hook in hooks: _hook_data = hook(hook_data, **kwargs) if _hook_data is not None: hook_data = _hook_data return hook_data
钩子函数,依次调用list()里各个函数,如果有返回值,把返回值单做下一阶段的入参
packages:
需要重点学习的有:
模块解释(简单到复杂) httpbin httpbin: A simple HTTP Request & Response Service.
hooks(钩子) 简单来说就是一个接一个的函数调用,有点像django的中间件,层层调用。
1 2 3 4 5 6 7 8 9 10 11 12 def dispatch_hook(key, hooks, hook_data, **kwargs): """Dispatches a hook dictionary on a given piece of data.""" hooks = hooks or {} hooks = hooks.get(key) if hooks: if hasattr(hooks, '__call__'): hooks = [hooks] for hook in hooks: _hook_data = hook(hook_data, **kwargs) if _hook_data is not None: hook_data = _hook_data return hook_data
说回之前的流程, 实例化属性self.hooks是 {‘response’ : [ ] } 这样的数据结构,类属性hooks是一个字典(可能为空,可能不为空)。然后通过对类属性hooks的主键和值进行迭代,并将键值对 作为参数传入继承而来的self.register_hook方法。
structures CaseInsensitiveDict 其中MutableMapping为抽象基类,类似Mapping。它们在collections模块中,供我们实现自定义的map类。Mapping包含dict中的所有不变方法,MutableMapping扩展包含了所有可变方法,但它们两个都不包含那五大核心特殊方法:getitem、setitem、delitem、len、iter。也就是说我们的目标就是实现这五大核心方法使该数据结构能够使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class CaseInsensitiveDict(MutableMapping): def __init__(self, data=None, **kwargs): self._store = OrderedDict()#有序key的map if data is None: data = {} self.update(data, **kwargs) def __setitem__(self, key, value): # Use the lowercased key for lookups, but store the actual # key alongside the value. self._store[key.lower()] = (key, value)#转小写 def __getitem__(self, key): return self._store[key.lower()][1]#? 为何[1] def __iter__(self): return (casedkey for casedkey, mappedvalue in self._store.values())#生成器 def lower_items(self): """Like iteritems(), but with all lowercase keys.""" return ( (lowerkey, keyval[1]) #? 为何只取了[1],既是第一个也应该是[0],为何在eq中需要使用 for (lowerkey, keyval) in self._store.items() ) def __eq__(self, other): if isinstance(other, Mapping): other = CaseInsensitiveDict(other) #兼容普通map else: return NotImplemented # Compare insensitively return dict(self.lower_items()) == dict(other.lower_items()) #间接调用普通dict的__eq__ # Copy is required def copy(self): return CaseInsensitiveDict(self._store.values())
LookupDict 本身只是个有名字(name)的map
1 2 3 4 5 6 class LookupDict(dict): """Dictionary lookup object.""" def __init__(self, name=None): self.name = name super(LookupDict, self).__init__()
特殊的在于其用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 _codes = { # Informational. 100: ('continue',), 101: ('switching_protocols',), 102: ('processing',), 103: ('checkpoint',), 122: ('uri_too_long', 'request_uri_too_long'), 200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'), } =>键值对互换 codes.continue=100 codes.uri_too_long=122 codes.request_uri_too_long=122
键值对互换 且多个键对应一个取值
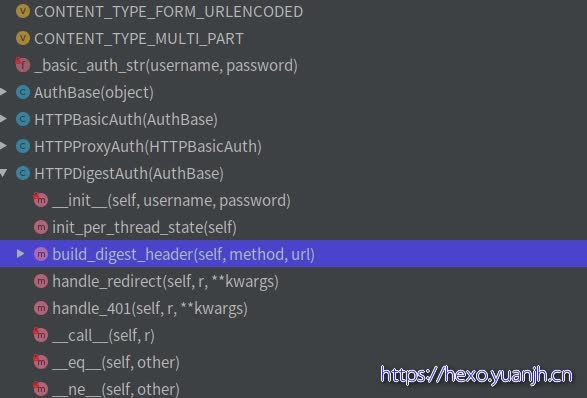
auth 代码结构:
1 2 3 4 5 6 7 基本认证 Base64(user:pwd)后,放在Http头的Authorization中发送给服务端来作认证. 用Base64纯只是防君子不防小人的做法。所以只适合用在一些不那么要求安全性的场合。 摘要认证 digest authentication(HTTP1.1提出的基本认证的替代方法) 这个认证可以看做是基本认证的增强版本,不包含密码的明文传递。
详情自行百度。明白了基本认证和摘要认证,这段代码基本也就看明白了,就是实现了一些约定的规范 。
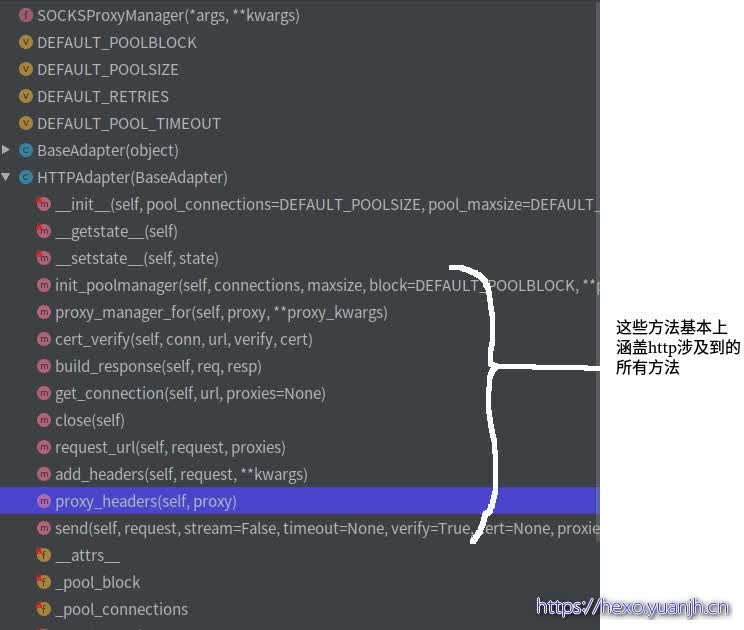
adapters 而adapters就是对urllib3进行的二次封装 。真正执行上层(api,session)操作的模块 ,扮演“执行者”或者“基层公务员”的角色。08_适配器
核心代码为send(),简化后代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def send(self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None): conn = self.get_connection(request.url, proxies) self.cert_verify(conn, request.url, verify, cert) url = self.request_url(request, proxies) self.add_headers(request, stream=stream, timeout=timeout, verify=verify, cert=cert, proxies=proxies) resp = conn.urlopen( method=request.method, url=url, body=request.body, headers=request.headers, redirect=False, assert_same_host=False, preload_content=False, decode_content=False, retries=self.max_retries, timeout=timeout ) return self.build_response(request, resp)
略过连接建立,超时机制,异常处理的部分,只看实际发送请求的部分:
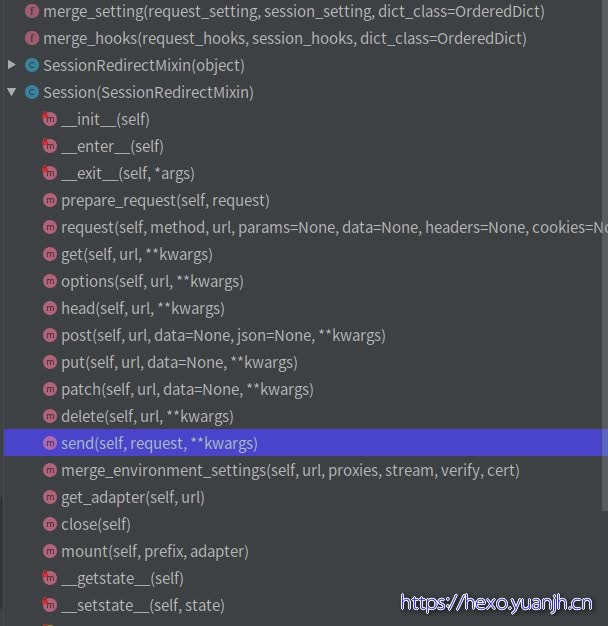
sessions 上层入口api.py的调用都会到sessions这里,所以这里才是requests里比较核心 的东西。
1 2 3 保留参数信息 和 cookie 利用 urllib3 的连接池 可以为 request 对象提供默认数据
入口方法request:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def request(self, method, url, # Create the Request. req = Request( method=method.upper(), url=url, headers=headers, files=files, data=data or {}, json=json, params=params or {}, auth=auth, cookies=cookies, hooks=hooks, ) prep = self.prepare_request(req) settings = self.merge_environment_settings( prep.url, proxies, stream, verify, cert ) # Send the request. send_kwargs = { 'timeout': timeout, 'allow_redirects': allow_redirects, } send_kwargs.update(settings) resp = self.send(prep, **send_kwargs) return resp
可以拆分为以下四个步骤:
prepare_request :相比原始request做了一定的二次加工,主要体现在几个merge_xx方法上
1 2 3 4 5 6 7 8 9 10 11 12 13 p = PreparedRequest() p.prepare( method=request.method.upper(), url=request.url, files=request.files, data=request.data, json=request.json, headers=merge_setting(request.headers, self.headers, dict_class=CaseInsensitiveDict),#改进 params=merge_setting(request.params, self.params),#改进 auth=merge_setting(auth, self.auth),#改进 cookies=merged_cookies,#改进 hooks=merge_hooks(request.hooks, self.hooks),#改进 )
在构建网络请求参数时,调用了 merge_cookies() 方法将 Session 中的 cookies 与 本次请求的 cookies 合并了,因此使用同一个 Session 对象发起网络请求时才能实现跨请求保持 cookie。至于其他的参数,可以看到调用了 merge_setting() 方法进行了合并。 而在网络请求返回时,会将请求的必要信息,比如 cookie 保存在 Session 中。send :发送逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 def send(self, request, **kwargs): kwargs.setdefault('stream', self.stream) kwargs.setdefault('verify', self.verify) kwargs.setdefault('cert', self.cert) kwargs.setdefault('proxies', self.proxies) hooks = request.hooks adapter = self.get_adapter(url=request.url) r = adapter.send(request, **kwargs) r = dispatch_hook('response', hooks, r, **kwargs) extract_cookies_to_jar(self.cookies, request, r.raw) return r
只是对hooks和cookie做了部分处理,主要逻辑send由adapter执行(adapter前文解释过,不在赘述).
架构 短方法(函数) 1 2 3 4 5 6 7 8 9 10 def get_adapter(self, url): """ Returns the appropriate connection adapter for the given URL. :rtype: requests.adapters.BaseAdapter """ for (prefix, adapter) in self.adapters.items(): if url.lower().startswith(prefix.lower()): return adapter
其中:self.adapters
1 2 3 self.adapters = OrderedDict() self.mount('https://', HTTPAdapter()) self.mount('http://', HTTPAdapter())
可以发现,很多短方法,如果不考虑_Init_部分,基本50行以上的都非常少,大多数30行以下。命名和参数提炼 比较讲究,既可以标识出“代码块功能 ”,又能区分出和其他代码块差异 (拆为step01(),step02(),step03()也是代码拆分,但是代码块差异则无法体现)。
阅读v0.10.0 核心调用链:api=>session(py).request()=>models(py).Request.send()
编码 长文本折行 1 2 3 4 5 6 7 warnings.warn( "Non-string usernames will no longer be supported in Requests " "3.0.0. Please convert the object you've passed in ({!r}) to " "a string or bytes object in the near future to avoid " "problems.".format(username), category=DeprecationWarning, )
all()函数 1 2 3 4 5 def __eq__(self, other): return all([ self.username == getattr(other, 'username', None), self.password == getattr(other, 'password', None) ])
以下是 all() 方法的语法:
参数:iterable – 元组或列表。
连续比较 1 if value[:1] == value[-1:] == '"':
变量函数 函数当做变量使用,避免if-else切入代码过多
1 2 3 get_proxy = lambda k: os.environ.get(k) or os.environ.get(k.upper()) if no_proxy is None: no_proxy = get_proxy('no_proxy')
上下文 先修改环境变量,使用后再恢复回来。
1 2 3 4 5 6 7 8 @contextlib.contextmanager def set_environ(env_name, value): """Set the environment variable 'env_name' to 'value' Save previous value, yield, and then restore the previous value stored in the environment variable 'env_name'. If 'value' is None, do nothing"""
其他问题 python的动态类型的确很影响对代码的阅读和理解.
参考 Requests库请求过程简析:https://blog.csdn.net/weixin_41677555/article/details/85246464 https://hustyichi.github.io/2019/08/10/requests-codes/ https://www.jianshu.com/p/83ffcbe99bb2 https://zhuanlan.zhihu.com/p/82694710 https://www.cnblogs.com/yc913344706/p/7995225.html https://www.cnblogs.com/sfencs-hcy/p/10350475.html https://www.jianshu.com/p/55f17668f156 https://www.jianshu.com/p/145959b76ff3 https://github.com/BigFlower666/learn_python/blob/master/read_requests_v2.22.0/read_requests_v2.22.0.md