Cpu
概述
CPU性能指标
(1)CPU使用率:
1) 用户态CPU使用率(包括用户态 user 和低优先级用户态 nice)、
2) 系统CPU使用率、
3) 等待 I/O 的CPU使用率、
4) 软中断和硬中断的CPU使用率、
5) 虚拟机占用的CPU使用率。
(2)平均负载 Load Average:过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载
(3)进程上下文切换:
1) 无法获取资源而导致的自愿上下文切换;
2) 被系统强制调度导致的非自愿上下文切换。
(4)CPU缓存命中率:因为CPU处理速度比内存访问速度快得多,则需要等待内存的响应。为了协调两者性能差距,出现了CPU的多级缓存。缓存命中率,衡量的是CPU缓存的复用情况,命中率越高、复用越多,性能越好。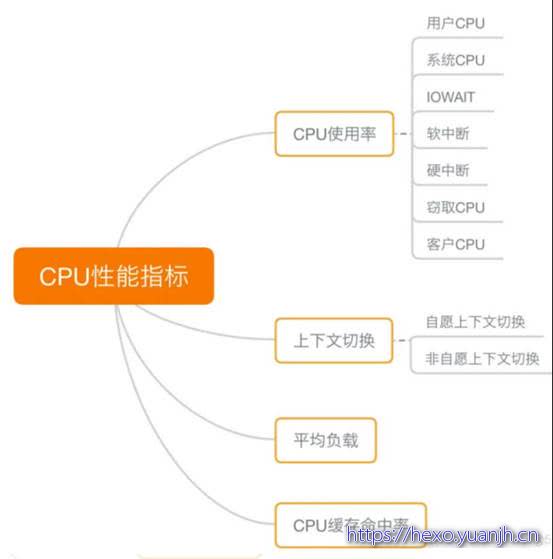
把提供CPU性能指标的工具做成了一个表格,方便你梳理关系和理解记忆,当然,你也可以当成一个”指标工具”指南来使用。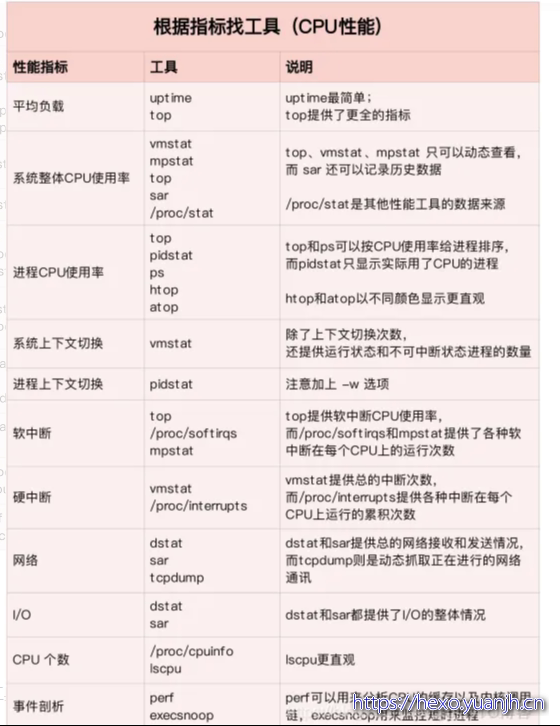
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。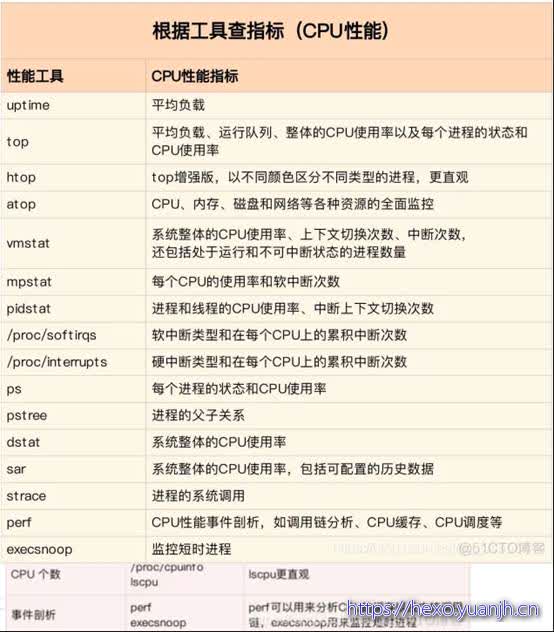
注意,我在这个图中只列出了最核心的几个性能工具,并没有列出所有。这么做,一方面是不想用大量的工具列表吓到你。在学习之初就接触所有或核心或小众的工具,不见得是好事。另一方面,是希望你能先把重心放在核心工具上,毕竟熟练掌握它们,就可以解决大多数问题。
我相信到这一步,你对CPU的性能指标已经非常熟悉,也清楚每种性能指标分别能用什么工具来获取。
那是不是说,每次碰到CPU的性能问题,你都要把上面这些工具全跑一遍,然后再把所有的CPU 性能指标全分析一遍呢?
你估计觉得这种简单查找的方式,就像是在傻找。不过,别笑话,因为最早的时候我就是这么做的。把所有的指标都查出来再统一分析,当然是可以的,也很可能找到系统的潜在瓶颈。但是这种方法的效率真的太低了! 耗时耗力不说,在庞大的指标体系面前,你一不小心可能就忽路了某个细节,导致白干一场。我就吃过好多次这样的苦。
所以,在实际生产环境中,我们通常都希望尽可能快地定位系统的瓶颈,然后尽可能快地优化性能,也就是要又快又准地解决性能问题。
那有没有什么方法,可以又快又准找出系统瓶颈呢?答案是肯定的。
虽然CPU的性能指标比较多,但要知道,既然都是描述系统的CPU性能,它们就不会是完全孤立的,很多指标间都有一定的关联。想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理。这也是为什么我在介绍每个性能指标时,都要穿插讲解相关的系统原理,希望你能记住这一点。
举个例子,用户CPU使用率高,我们应该去排查进程的用户态而不是内核态。因为用户CPU 使用率反映的就是用户态的CPU 使用情况,而内核态的CPU使用情况只会反映到系统CPU使用率上。
你看,有这样的基本认识,我们就可以缩小排查的范围,省时省力。
所以,为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如top、vmstat 和pidstat。为什么是这三个工具呢?仔细看看下面这张图,你就清楚了。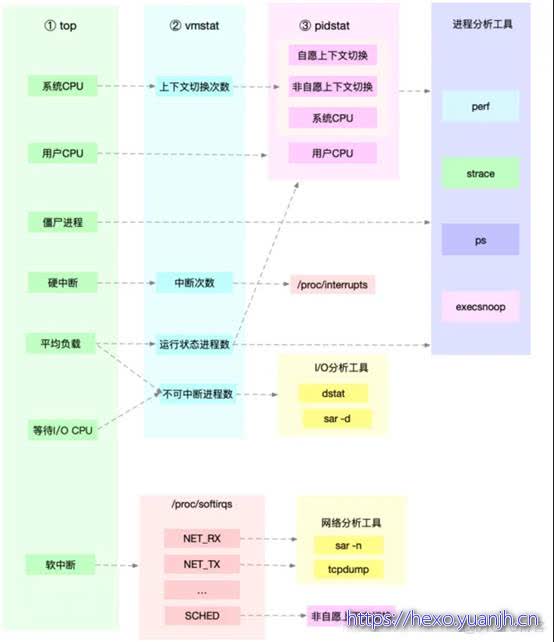 这张图里,我列出了 top、vmstat和pidstat 分别提供的重要的CPU指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
这张图里,我列出了 top、vmstat和pidstat 分别提供的重要的CPU指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
通过这张图你可以发现,这三个命令,几乎包含了所有重要的CPU性能指标比如∶
● 从 top的输出可以得到各种CPU使用率以及僵尸进程和平均负载等信息。
● 从vmstat的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
● 从 pidstat的输出可以得到进程的用户CPU使用率、系统CPU使用率、以及自愿上下文切换和非自愿上下文切换情况。
CPU使用率
相关命令:top,vmstat,mpstat,iostat -c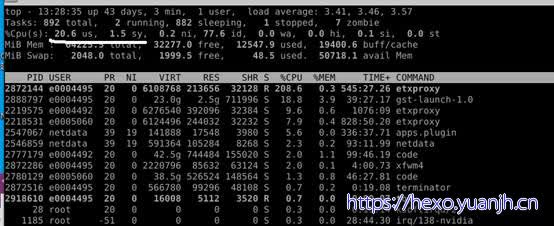
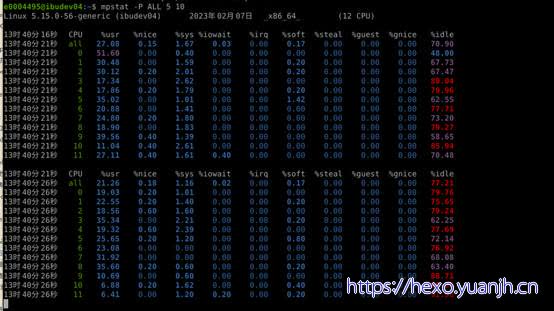
平均负载 Load Average
相关命令:uptime,top
系统的平均活跃进程数。Uptime
统计系统当前的运行状况,输出的信息依次为:系统现在的时间、系统从上次开机到现在运行了多长时间、系统目前有多少登陆用户、系统在一分钟内、五分钟内、十五分钟内的平均负载。
这里需要注意的是load average这个输出值,这三个值的大小一般不能大于系统CPU的个数,例如,本输出中系统有8个CPU,如果load average的三个值长期大于8时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于8时,倒不用担心,一般不会影响系统性能。相反,如果load average的输出值小于CPU的个数,则表示CPU还有空闲的时间片,比如本例中的输出,CPU是非常空闲的。
进程上下文切换
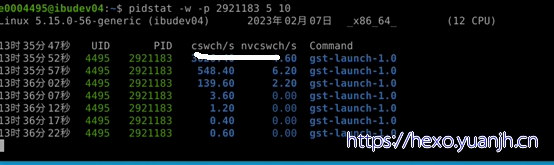
相关命令:vmstat,pidstat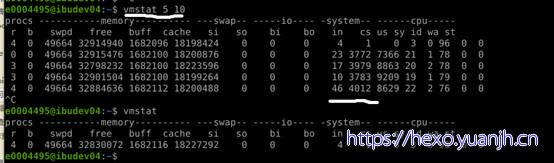
CPU缓存命中率(暂无)
相关命令:没找到
案例
CPU使用率过高的总体分析步骤
Step1:通过 top、pidstat 找到哪个进程CPU使用率过高;
Step2:通过 perf 找到该进程中具体哪个函数使用过高。$ perf top -g -p
Step3:通过 grep 查看该函数中的具体内容。$ grep -nr “<function_name>” <file_path>
性能问题:
(1)用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
(2)系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
(3)I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
(4)软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的CPU,所以应该着重排查内核中的中断服务程序。
样例01,pidstat 输出的进程用户CPU使用率升高,会导致 top输出的用户 CPU使用率升高。所以,当发现 top输出的用户CPU使用率有问题时,可以跟 pidstat的输出做对比,观察是否是某个进程导致的问题。
而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为,比如使用 strace 分析系统调用情况,以及使用 perf分析调用链中各级函数的执行情况。
样例02,top输出的平均负载升高,可以跟 vmstat输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。
● 如果是不可中断进程数增多了,那么就需要做I/O的分析,也就是用dstat或sar等工具,进一步分析I/0的情况。
● 如果是运行状态进程数增多了,那就需要回到 top和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
样例03,当发现 top输出的软中断 CPU使用率升高时,可以查看/proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar和 tcpdump 来分析。
样例04,系统的CPU使用率升高的案例。我们先用 top观察到了系统CPU升高,但通过 top 和 pidstat,却找不出高CPU使用率的进程。于是,我们重新审视 top的输出,又从CPU使用率不高但处于Running状态的进程入手,找出了可疑之处,最终通过 perf record和 perf report,发现原来是短时进程在捣鬼。
样例05,系统的 CPU 使用率很高,却找不到高 CPU 的应用
系统的 CPU 使用率,不仅包括进程用户态和内核态的运行,还包括中断处理、等待 I/O 以及内核线程等。所以,当你发现系统的 CPU 使用率很高的时候,不一定能找到相对应的高 CPU 使用率的进程。
如下系统总CPU使用率80.8%,而单个进程的CPU使用率都较小。需要通过 top 、pidstat 等交叉确认系统和各进程的CPU使用率。
并且仔细观察进程列表中的状态S,查看R、S等状态的进程是否正常。
1 | $ top |
发生以上情况的原因:
(1)进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了,而启动过程的资源初始化,很可能会占用相当多的 CPU。
(2)这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现。
发送上述问题的解决方法是找到父进程,从父进程入手,排查问题:
方法一:
(1)通过 top、pidstat 等找到可疑进程;
(2)通过 pstree 用树状形式显示该进程与其他进程的关系;
(3)通过 grep 找到具体调用代码
方法二:
(1)通过 perf record -g // 记录性能事件,等待大约 几秒后按 Ctrl+C 退出
(2)通过 perf report
方法三:
execsnoop 就是一个专为短时进程设计的工具,一般用于分析 Linux 内核的运行时行为。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
https://github.com/brendangregg/perf-tools/blob/master/execsnoop
样例06,系统中出现大量不可中断进程和僵尸进程
不可中断状态,是为了保证进程数据与硬件状态一致,并且正常情况下,不可中断状态在很短时间内就会结束。所以,短时的不可中断状态进程,我们一般可以忽略。但如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。这时系统可能出现了 I/O 等性能问题。
僵尸进程,这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册 SIGCHLD 信号的处理函数,异步回收资源。如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。但是一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建。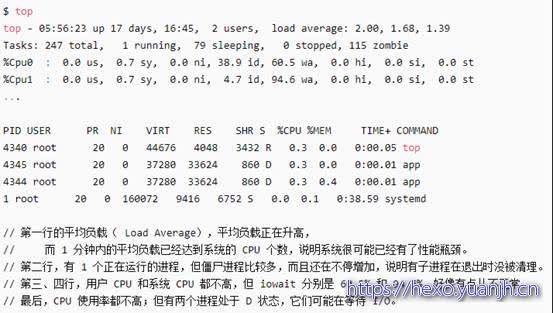
第一点, iowait 太高了,导致系统的平均负载升高,甚至达到了系统 CPU 的个数。
第二点,僵尸进程在不断增多,说明有程序没能正确清理子进程的资源。
僵尸进程分析
既然僵尸进程是因为父进程没有回收子进程的资源而出现的,那么,也就是找出父进程的问题。
(1)通过 pstree -aps 找出当前进程的父进程。// -a 表示输出命令行选项 p 表示 PID s 表示指定进程的父进程
(2)查看父进程的代码,看看子进程结束的处理是否正确,比如有没有调用 wait() 或 waitpid() ,或是,有没有注册 SIGCHLD 信号的处理函数。
故障分析 | 大量短时进程导致 cpu 负载过高案例一则:https://cloud.tencent.com/developer/article/2010964
性能分析(3)- 短时进程导致用户 CPU 使用率过高案例:www.manongjc.com/detail/57-ocypedxbsyhbphv.html
短时进程,我还介绍了一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
内存
概述
下面这张图,就是一个迅速定位内存瓶颈的流程。我们可以通过 free 和 vmstat 输出的性能指标,确认内存瓶颈;然后,再根据内存问题的类型,进一步分析内存的使用、分配、泄漏以及缓 存等,最后找出问题的来源。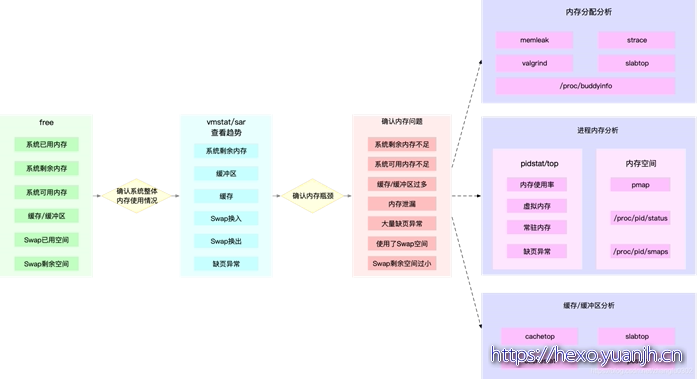
很多内存的性能指标,也来源于 /proc 文件系统(比如 /proc/meminfo、/proc/slabinfo 等),它们也都应该通过监控系统监控起来。这样,当收到内存告警时,就可以从监控系统中,直接得到上图中的各项性能指标,从而加快性能问题的定位过程。
比如说,当收到内存不足的告警时,首先可以从监控系统中。找出占用内存最多的几个进程。 然后,再根据这些进程的内存占用历史,观察是否存在内存泄漏问题。确定出最可疑的进程后, 再登录到进程所在的 Linux 服务器中,分析该进程的内存空间或者内存分配,最后弄清楚进程为什么会占用大量内存。
各部分空间分布
相关命令:free
Mem 行是内存的使用情况。
buffers/cache 行是物理内存的缓存统计情况。
Swap 行是交换空间的使用情况。
前面分别介绍过了物理内存和Swap分区。这里再介绍一下buffers和cache。
free 与 available 的区别
free 是真正尚未被使用的物理内存数量。
available 是应用程序认为可用内存数量,available = free + buffer + cache (注:只是大概的计算方法)
Linux 为了提升读写性能,会消耗一部分内存资源缓存磁盘数据,对于内核来说,buffer 和 cache 其实都属于已经被使用的内存。但当应用程序申请内存时,如果 free 内存不够,内核就会回收 buffer 和 cache 的内存来满足应用程序的请求。
当free内存接近零时,有些人会非常担心。但是接近零的free内存很酷,这实际上意味着您的内核正在将内存用于诸如缓存之类的良好用途。
buffer与cache
A buffer is something that has yet to be “written” to disk.
A cache is something that has been “read” from the disk and stored for later use.
简单点说:
buffers 就是存放要输出到disk(块设备)的数据,缓冲满了一次写,提高IO性能(内存 -> 磁盘)
cached 就是存放从disk上读出的数据,常用的缓存起来,减少IO(磁盘 -> 内存)
buffer 和 cache,两者都是RAM中的数据。简单来说,buffer是即将要被写入磁盘的,cache是被从磁盘中读出来的。
这里也有不同意见
结论:读文件时数据会缓存到 Cache 中,而读磁盘时数据会缓存到 Buffer 中。
Buffer 既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
Cache 既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
简单来说,Buffer 是对磁盘数据的缓存,而 Cache 是文件内容数据的缓存,它们既会用在读请求中,也会用在写请求中。
来自:Linux性能优化从入门到实战:09 内存篇:Buffer和Cache:https://blog.csdn.net/qccz123456/article/details/95369115
特定进程占用swap
相关命令:Cat /proc/
缓存的读写命中(系统)
相关命令:cachestat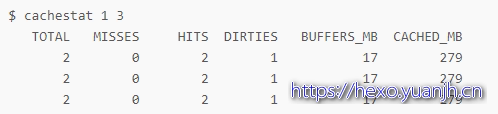
TOTAL ,表示总的 I/O 次数;
MISSES ,表示缓存未命中的次数;
HITS ,表示缓存命中的次数;
DIRTIES, 表示新增到缓存中的脏页数;
BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
CACHED_MB 表示 Cache 的大小,以 MB 为单位。
进程的缓存命中(进程)
相关命令:cachetop
默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES和DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而 READ_HIT 和 WRITE_HIT ,分别表示读和写的缓存命中率。
特定文件的缓存大小
相关命令: pcstat
pcstat 是一个基于 Go 语言开发的工具,所以安装它之前,你首先应该安装 Go 语言,下面就是一个 pcstat 运行的示例,它展示了 /bin/ls 这个文件的缓存情况: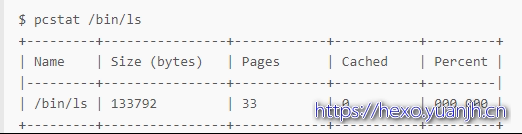
这个输出中,Cached 就是 /bin/ls 在缓存中的大小,而 Percent 则是缓存的百分比。你看到它们都是 0,这说明 /bin/ls 并不在缓存中。
接着,如果你执行一下 ls 命令,再运行相同的命令来查看的话,就会发现 /bin/ls 都在缓存中了: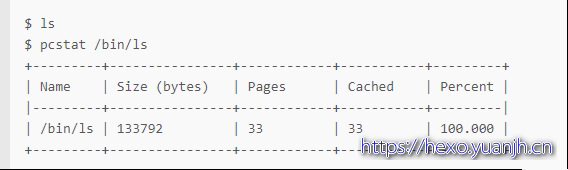
进程内存占用详情
相关命令:pmap
显示进程的内存映射,显示它们的大小、权限及映射对象。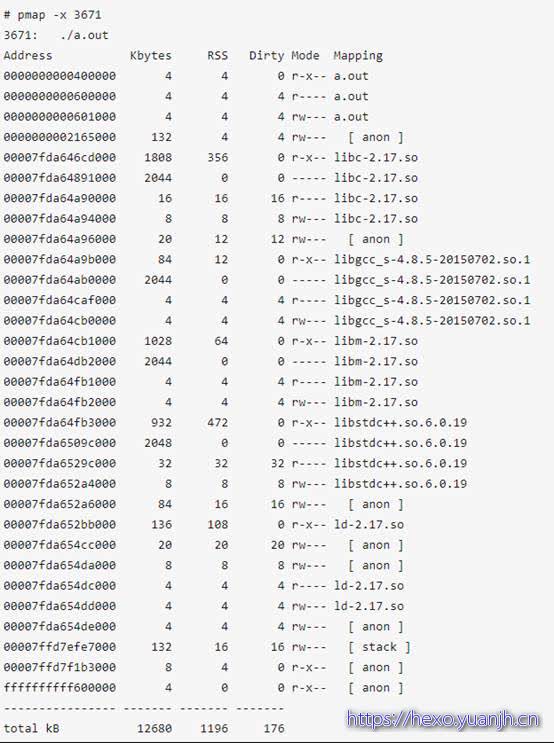
内存带宽
相关命令: mbw -q -n 10 256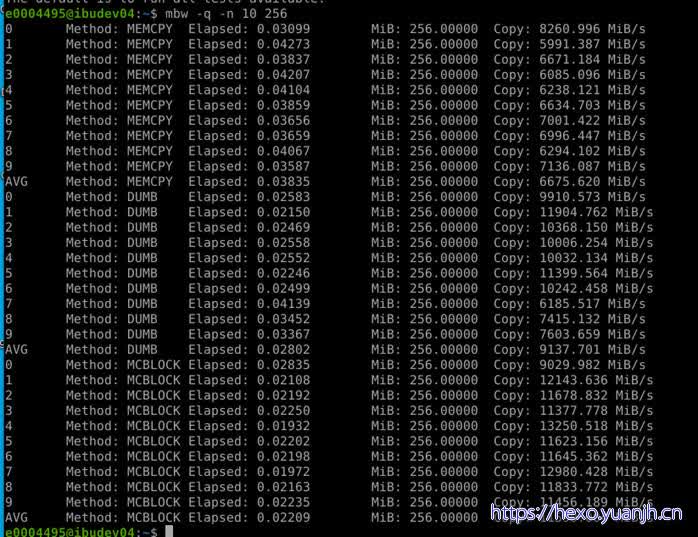
3种method类型含义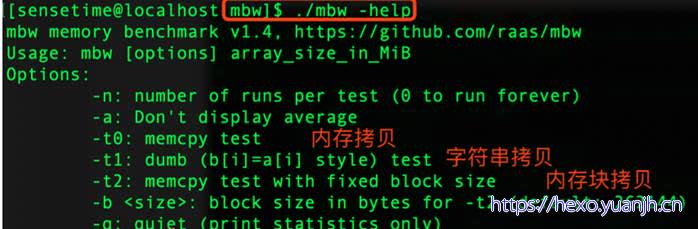
Io
概述
使用 iostat ,发现磁盘 I/O 存在性能瓶颈(比如 I/O 使用率过高、 响应时间过长或者等待队列长度突然增大等)后,可以再通过 pidstat、 vmstat 等,确认 I/O 的来源。接着,再根据来源的不同,进一步分析文件系统和磁盘的使用率、缓存以及进程的 I/O 等,从而揪出 I/O 问题的真凶。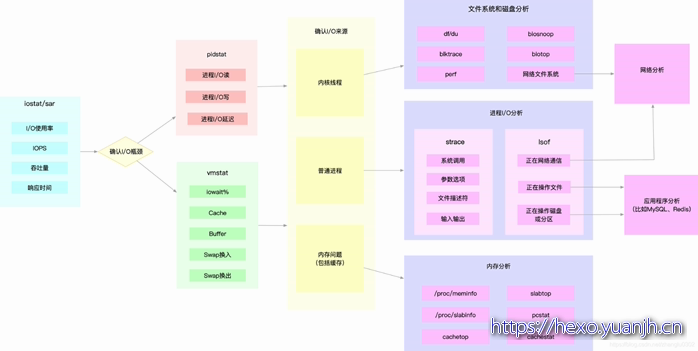
同 CPU 和内存性能类似,很多磁盘和文件系统的性能指标,也来源于 /proc 和 /sys 文件系统 (比如 /proc/diskstats、/sys/block/sda/stat 等)。自然,它们也应该通过监控系统监控起 来。这样,当收到 I/O 性能告警时,就可以从监控系统中,直接得到上图中的各项性能指标, 从而加快性能定位的过程。
比如,当发现某块磁盘的 I/O 使用率为 100% 时,首先可以从监控系统中。找出 I/O 最多的进程。然后,再登录到进程所在的 Linux 服务器中,借助 strace、lsof、perf 等工具,分析该进程的 I/O 行为。最后,再结合应用程序的原理,找出大量 I/O 的原因。
磁盘角度的io负载
相关命令: iostat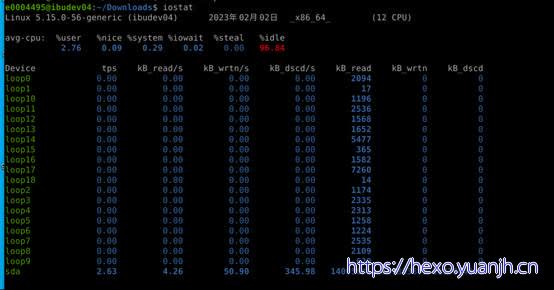
结果解析:
tps 该设备每秒的传输次数,“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”,“一次传输”请求的大小是未知的
kB_read/s 每秒从设备(drive expressed)读取的数据量
kB_wrtn/s 每秒向设备(drive expressed)写入的数据量
kB_read 读取的总数据量
kB_wrtn 写入的总数据量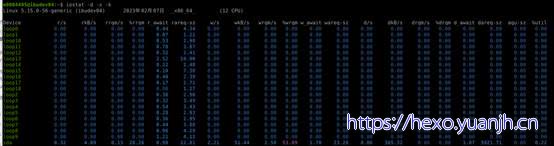
结果解析:
rrqm/s 每秒合并读操作的次数,如果两个读操作读取相邻的数据块时,可以被合并成一个,以提高效率。合并的操作通常是I/O scheduler(也叫elevator)负责的。
wrqm/s 每秒合并写操作的次数
r/s 每秒读操作的次数
w/s 每秒写操作的次数
rkB/s 每秒读取的字节数(KB)
wkB/s 每秒写入的字节数(KB)
avgrq-sz 每个IO的平均扇区数,即所有请求的平均大小,以扇区(512字节)为单位
avgqu-sz 平均未完成的IO请求数量,即平均意义上的请求队列长度
await 平均每个IO所需要的时间,包括在队列等待的时间,也包括磁盘控制器处理本次请求的有效时间
r_await 每个读操作平均所需要的时间,不仅包括硬盘设备读操作的时间,也包括在内核队列中的时间
w_await 每个写操平均所需要的时间,不仅包括硬盘设备写操作的时间,也包括在队列中等待的时间
svctm 表面看是每个IO请求的服务时间,不包括等待时间,但是实际上,这个指标已经废弃。实际上,iostat工具没有任何一输出项表示的是硬盘设备平均每次IO的时间
%util 表示该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有,由于硬盘设备有并行处理多个i/o请求的能力,所以%util即使达到100%也不意味着设备饱和了。
举个简化的例子:某硬盘处理单个I/O需要0.1秒,有能力同时处理10个I/O请求,那么当10个I/O请求依次顺序提交的时候,需要1秒才能全部完成,在1秒的采样周期里%util达到100%;而如果10个I/O请求一次性提交的话,0.1秒就全部完成,在1秒的采样周期里%util只有10%。可见,即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态。
不足
iostat 的输出结果大多数是 一段时间内的平均值,因此难以反映峰值情况;
iostat 仅能对 系统整体情况进行分析汇报,却不能针对某个进程进行深入分析;
iostat 未单独统计IO处理信息,而是 将IO处理时间 和 IO等待时间 合并统计,因此包括await在内的指标并不能非常准确地衡量磁盘性能表现。
进程io
相关命令:iotop,pidstat,ioprofile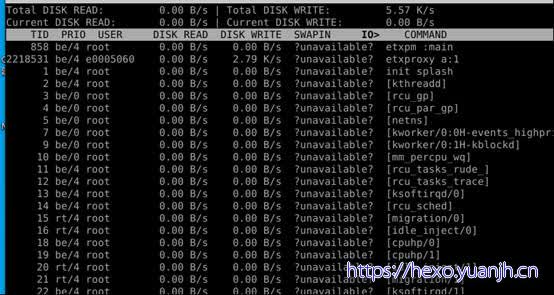
pidstat -p xxx -d 1 10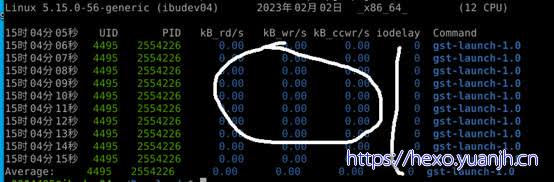
进程打开文件列表: lsof -p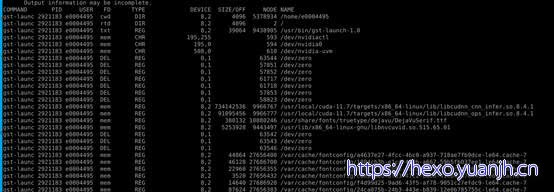
线程io
相关命令: pidstat
分析应用程序中哪一个线程占用的io比较高
shell> pidstat -dt -p 73739 1 执行两三秒即可
Average: 1000 - 73823 0.00 233133.98 0.00 |mysqld
Average: 1000 - 74674 0.00 174291.26 0.00 |mysqld
11:56:18 PM 1000 - 74770 124928.00 74688.00 0.00 |mysqld
11:56:17 PM 1000 - 74770 124603.77 73358.49 0.00 |mysqld
Average: 1000 - 74770 124761.17 74003.88 0.00 |__mysqld
由上可知:74770这个线程占用的io比较高
Net
概述
网络性能,其实包含两类资源,即网络接口和内核资源。网络性能的分析,要从 Linux 网络协议栈的原理来切入。下面这张图,就是 Linux 网络协议栈的基本原理,包括应用层、套机字接口、传输层、网络层以及链路层等。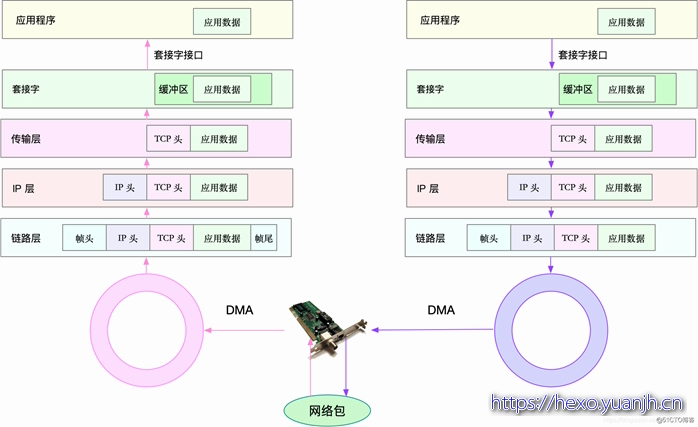
而要分析网络的性能,自然也是要从这几个协议层入手,通过使用率、饱和度以及错误数这几类 性能指标,观察是否存在性能问题。比如:
在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析;
在网络层,可以从路由、分片、叠加网络等角度进行分析;
在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度进行 分析;
在应用层,可以从应用层协议(如 HTTP 和 DNS)、请求数(QPS)、套接字缓存等角度进 行分析。
同前面几种资源类似,网络的性能指标也都来源于内核,包括 /proc 文件系统(如 /proc/net)、网络接口以及 conntrack 等内核模块。这些指标同样需要被监控系统监控。这样,当收到网络告警时,就可以从监控系统中,查询这些协议层的各项性能指标,从而更快定位出性能问题。
比如,当我们收到网络不通的告警时,就可以从监控系统中,查找各个协议层的丢包指标,确认丢包所在的协议层。然后,从监控系统的数据中,确认网络带宽、缓冲区、连接跟踪数等软硬件, 是否存在性能瓶颈。最后,再登录到发生问题的 Linux 服务器中,借助 netstat、tcpdump、 bcc 等工具,分析网络的收发数据,并且结合内核中的网络选项以及 TCP 等网络协议的原理,找出问题的来源。
连通性测试
相关命令:ping
累计流量
相关命令:ifconfig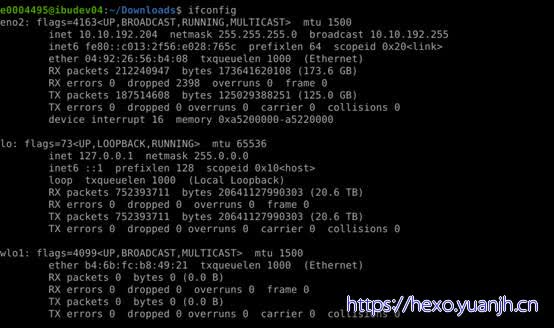
RX= =receive,接收,从开启到现在接收封包的情况,是下行流量。
TX= =Transmit,发送,从开启到现在发送封包的情况,是上行流量。
实时流量
相关命令:nload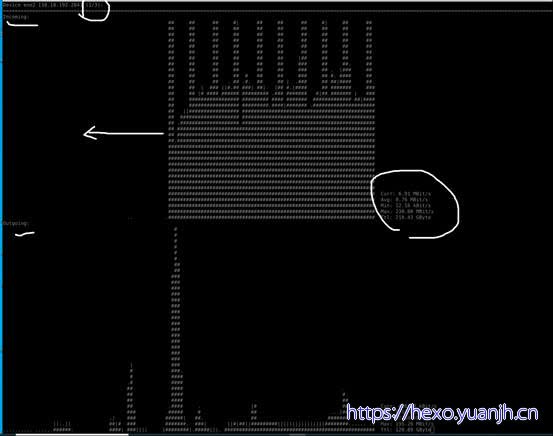
Nload –m
网络连接分析
相关命令: Iftop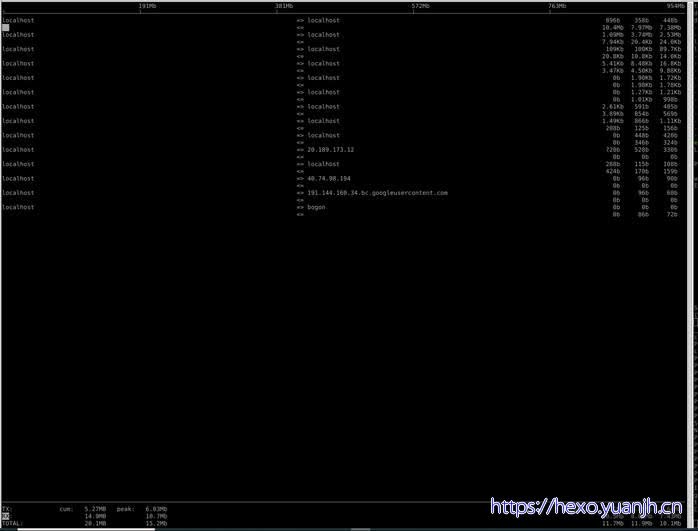
第一行,是带宽,下面带有标尺,用来标示每个连接上的实时流量占用的带宽
中间部分,是所有的连接,默认显示的是主机名,可以通过参数显示ip,箭头表示数据方向
中间右侧三列,分别是该连接2s、10s、40s的平均流量
底部三行,分别表示发送、接收、汇总的流量
底部三行第2列,为iftop启动到现在的流量汇总
底部三行第3列,为峰值速率
第4列,为平均值
注意,流量单位为bit,非Byte
可以看到,通过iftop可以很容易看到各个连接的流量使用情况。
进程占用流量
端口定位法:iftop(-P )+lsof(-i:xx)

命令:nethogs
网卡性能测试
ethtool,物理属性速度
dmesg|grep eno2 | grep up,物理速度属性
speedtest-cli:针对固定ip的测试
nload:实际流量测试
iftop,nethogs:进程流量统计
iperf:双网卡直连方式测试
两个网卡用网线连接到同一个交换机上,或者直连,交换机交换最大速率不能低于待测试网卡的标称速率。
在两台机器上分别运行命令:
服务端命令:iperf -s -P 0 -i 1 -p 5001 -w 2M -f k
客户端命令:iperf -c 192.168.1.3 -i 1 -w 2M -t 600(服务端IP地址:192.168.1.3)
其他
系统资源瓶颈识别和定位
在系统监控的综合思路篇中,系统资源的瓶颈,可以通过 USE 法,即使用率、饱和度以及错误数这三类指标来衡量。系统的资源,可以分为硬件资源和软件资源两类。
硬件资源:CPU、内存、磁盘和文件系统以及网络等
软件资源:文件描述符数、连接跟踪数、套接字缓冲区大小等
在收到监控系统的告警时,可以对照这些资源列表,再根据不同的指标来进行定位。
其中,硬件资源瓶颈相对容易定位,cpu占用率,内存使用率等明确且清晰。软件资源由于不同应用的差异,并没有明确的界限区别正常还是异常。一个对A程序属于正常范畴的指标,对B程序则是异常,只能具体问题具体分析。
应用程序瓶颈
部分瓶颈,直接来自应用程序。比如,最典型的应用程序性能问题,就是吞吐量(并发请求数)下降、错误率升高以及响应时间增大。
这些应用程序性能问题虽然各种各样,但就其本质来源,实际上只有三种,也就是资源瓶颈、依赖服务瓶颈以及应用自身的瓶颈。
第一种资源瓶颈,其实还是指刚才提到的 CPU、内存、磁盘和文件系统 I/O、网络以及内核资源等各类软硬件资源出现了瓶颈,从而导致应用程序的运行受限。对于这种情况,我们就可以用前面系统资源瓶颈模块提到的各种方法来分析。
第二种依赖服务的瓶颈,也就是诸如数据库、分布式缓存、中间件等应用程序,直接或者间接调用的服务出现了性能问题,从而导致应用程序的响应变慢,或者错误率升高。这说白了就是跨应用的性能问题,使用全链路跟踪系统,就可以帮你快速定位这类问题的根源。
最后一种,应用程序自身的性能问题,包括了多线程处理不当、死锁、业务算法的复杂度过高等等。对于这类问题,在应用程序指标监控以及日志监控中,观察关键环节的耗时和内部执行过程中的错误,就可以帮你缩小问题的范围。
不过,由于这是应用程序内部的状态,外部通常不能直接获取详细的性能数据,所以就需要应用程序在设计和开发时,就提供出这些指标,以便监控系统可以了解应用程序的内部运行状态。
如果这些手段过后还是无法找出瓶颈,我们还可以用系统资源模块提到的各类进程分析工具,来进行分析定位。比如:
可以用 strace,观察系统调用;
使用 perf 和火焰图,分析热点函数;
甚至使用动态追踪技术,来分析进程的执行状态。
当然,系统资源和应用程序本来就是相互影响、相辅相成的一个整体。实际上,很多资源瓶颈, 也是应用程序自身运行导致的。比如,进程的内存泄漏,会导致系统内存不足;进程过多的 I/O 请求,会拖慢整个系统的 I/O 请求等。
所以,很多情况下,资源瓶颈和应用自身瓶颈,其实都是同一个问题导致的,并不需要我们重复分析。
性能分析工具集特征
工具体系非常庞大,围绕硬件的(英伟达nsight,英特尔Vtune等),围绕系统的(vmstat,mpstat),围绕app的(perf,gprof,strace内核态),围绕语言的(go的gprof,java,pyton等均有特定工具)
不同层次工具之间,功能上存在交叉
没有严谨的方法论,比如:按照一个手册12345后,就得得到确定结论,大多都需要具体问题具体分析
问题排查,定位进程->线程->gstack线程堆栈现场
CPU飙高排查步骤:https://blog.csdn.net/weixin_50914566/article/details/141939462
性能分析之CPU分析-从CPU调用高到具体代码行(C/C++):https://www.cnblogs.com/GaoLou/p/14897144.html
命令响应解析
Top
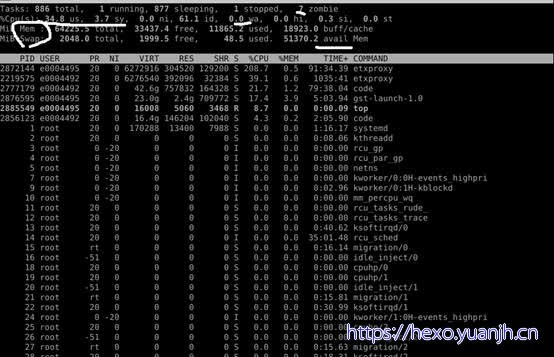
命令参考
一文辨析,性能分析top命令中进程NI和PR:https://zhuanlan.zhihu.com/p/503042646
理解virt、res、shr之间的关系(linux系统篇):https://baijiahao.baidu.com/s?id=1743908545937632735&wfr=spider&for=pc
mpstat
针对多核问题,比如多线程程序任务分配不均匀,无法充分利用cpu等
mpstat -P ALL
参考:
系统调优–mpstat命令详解:https://blog.csdn.net/weixin_44175418/article/details/124986740
Vmstat
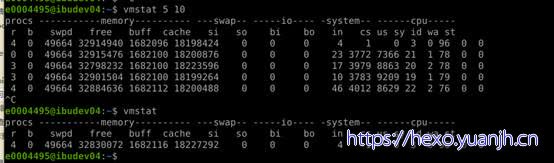
上面每项的输出解释如下:
procs
r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。
b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
memory
swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。
free列表示当前空闲的物理内存数量(以k为单位)
buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。
IO
磁盘读写状况
Bi列表示从块设备读入数据的总量(即读磁盘)(每秒kb)。
Bo列表示写入到块设备的数据总量(即写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题,应该考虑提高磁盘的读写性能。
system
采集间隔内发生的中断数
in列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数。
上面这2个值越大,会看到由内核消耗的CPU时间会越多。
CPU
CPU的使用状态,此列是我们关注的重点。
us列显示了用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。
根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。
id 列显示了CPU处在空闲状态的时间百分比。
wa列显示了IO等待所占用的CPU时间百分比。wa值越高,说明IO等待越严重,根据经验,wa的参考值为20%,如果wa超过20%,说明IO等待严重,引起IO等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作)。
综上所述,在对CPU的评估中,需要重点注意的是procs项r列的值和CPU项中us、sy和id列的值。
NetData
安装
sudo apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libjudy-dev libssl-dev libmnl-dev gcc make git autoconf autoconf-archive autogen
sudo apt-get install netdata
基本操作
1 | # 启动NetData服务,并设置开机启动 |
功能开关
修改文件:/etc/netdata/netdata.conf
修改[plugins]中的配置。原配置文件中大部分默认开启的,如果我们不需要某些图表的话,可以将注释去掉,改为no。然后重启服务,就可以禁用相应的图表。
降低内存占用
修改文件:/etc/netdata/netdata.conf
核心配置中的数据刷新率。
1 | # 降低cpu占用: |
第三方扩展插件(NVIDIA-SMI)
1 | # 使用官方提供的脚本,生成对应文件的配置文件 |
监控数据的保存
存入mongdb后端
sudo ./edit-config mongodb.conf
设置MongoDB URI,数据库名称和集合名称
Glances
安装
pip install glances
本机直接运行
Glances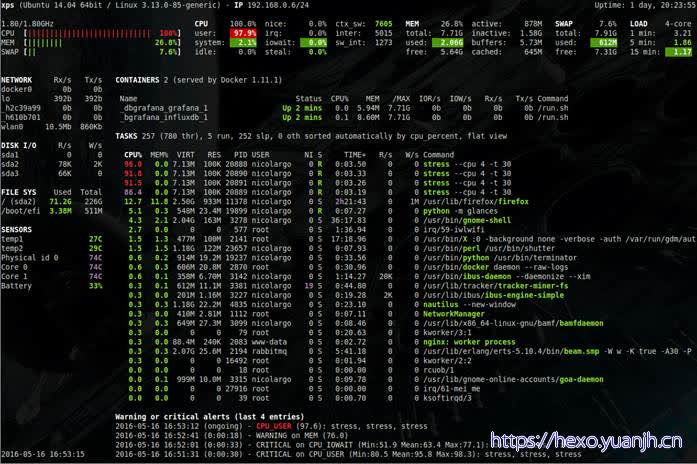
说明:这个页面的说明文档在这,官方github的docs/aoa文件夹下
关于字段说明,交互项,排序规则,字符颜色控制等,想了解或修改相关模块配置,到aoa文件夹下查阅。
比如修改:进度显示样式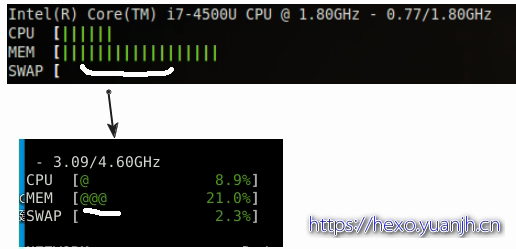
对应文档:aoa/quicklook.rst
其他类似的
1 | aoa/connections.rst,tcp连接模块, |
较为常用的还有ps的过滤
这里需要留意的是文档中:
第一个意思是输入:python可以匹配出python开始的进程,亲测不行,其余3个ok
怀疑是软件版本问题,当前04上安装软件,提示如下: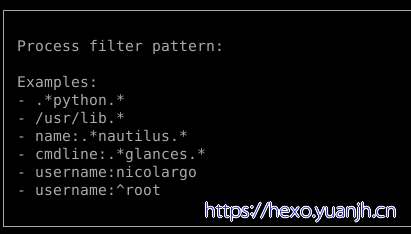
监控其他机器(客户端服务端模式)
server$ glances -s #服务侧启动服务
glances -c @server \s#客户端连接服务端显示数据
网页模式:
glances -w
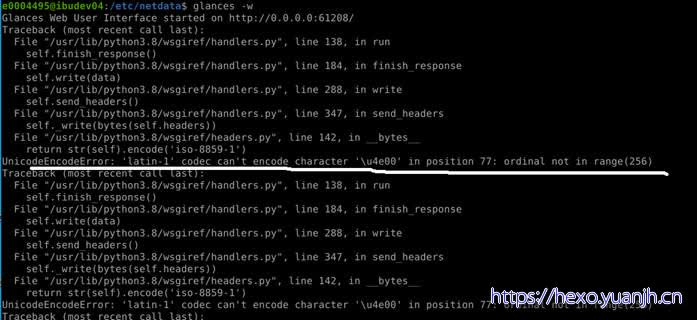
浏览器打开:http://0.0.0.0:61208/
本机测试时报错: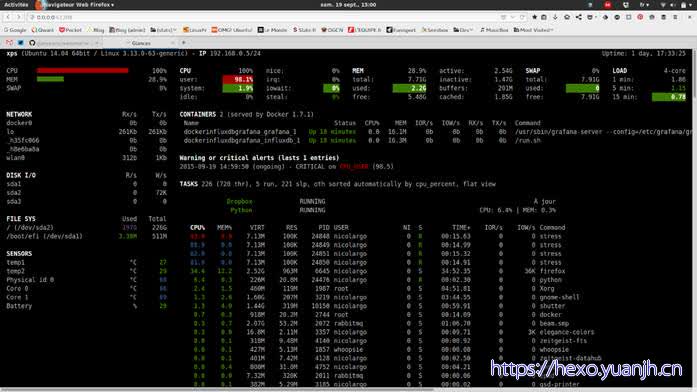
不同颜色的含义:
◆绿色:正常(OK)
◆蓝色:小心(careful)
◆紫色:警告(warning)
◆红色:致命(critical)
默认设置下,Glances 的阀值设置是:careful=50,warning=70,critical=90。你可以通过 “/etc/glances/” 目录下的默认配置文件 glances.conf 来自定义这些阀值。
常用的热键列表:
◆m:按内存占用排序进程
◆p:按进程名称排序进程
◆c:按 CPU 占用率排序进程
◆i:按 I/O 频率排序进程
◆a:自动排序进程
◆d:显示/隐藏磁盘 I/O 统计信息
◆f:显示/隐藏文件系统统计信息
◆s:显示/隐藏传感器统计信息
◆y:显示/隐藏硬盘温度统计信息
◆n:显示/隐藏网络统计信息
◆q:退出
还有一些特性体现再和外部平台对接上
比如:docs/api.rst,对外暴露的restful接口
docs/docker.rst,docker代替原生安装,对外暴露web服务
aoa/actions.rst,某状态持续多久后,执行特定命令(脚本)