人社大赛算法赛题解题思路分享+季军+三马一曹团队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.485a311fu9lqGt&postId=2981
就诊频次
就诊不同医院个数
各费用的汇总统计量,包括最大值,最小值,均值
选出出现次数最多的24种药品,计算每个社保用户每个药品的取药金额的总和。描述社保人员购买药品情况。
医院欺诈率对医院ID进行排序处理,然后对所有的医院进行分箱,设计医院欺诈等级特征,用来描述社保人员看病医院偏好。
我们决定根据模型输出的特征重要性得分进行特征选择,通过选择不同个数的特征数进行对比实验,最终选取了top150特征,对样本进行重新训练。
人社大赛算法赛场解题思路分享+第四名+DPS
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.485a311fu9lqGt&postId=2982

由于人社数据具有数据不平衡的特点(欺诈类样本占3%-5%左右),因此相比随机森林这样的Bagging方法,XGBoost、GBDT、LightGBM这类Gradient Boosting Machine会有更好的效果,因此我们主要是选用了这三类模型作为后续模型融合的基模型。不仅如此,我们还为样本设置了权重,从而可以避免Boosting在不平衡数据上的“冷启动”问题,最开始训练的树就能对所占比例较少的正样本有比较优的预测结果。
另外,因为我们选用的融合方法对基模型的效果要求比较高,因此我们选用的都是经过交叉验证确定的最优参数,于是我们结合了人社数据的特点在训练集多样性又进行了一些工作——我们为每个模型训练都构造一份训练集。如图8,具体来说,考虑到欺诈类样本非常珍贵,我们予以全部保留,非欺诈类样本我们随机去除10%的样本,以此构造训练集。这样既考虑到欺诈类样本的宝贵性,也兼顾了模型融合对多样性的需求。
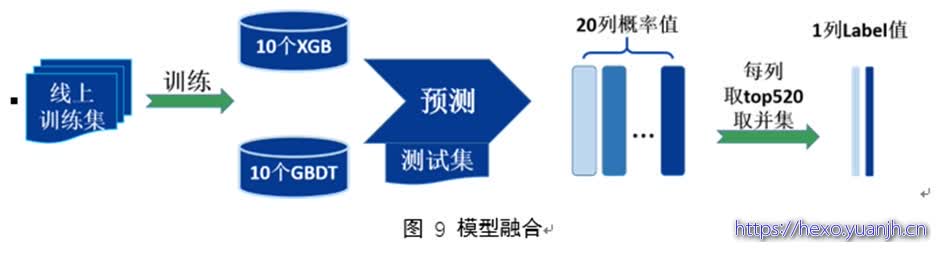
我们的融合策略简单,但有效,如图9,首先按图8流程构造20份训练集,作为10个XGBoost、10个GBDT的训练数据,最终训练得到20个GBM模型,利用这些模型对测试集进行预测,得到20组预测为欺诈的概率,对每组取概率最大的前520个用户作为欺诈用户,将20组欺诈用户再取并集,最终得到920个左右的欺诈用户,以此作为我们最终的预测结果。值得一提的是,这种融合方式的主要优点是能稳定模型结果,使线下线上尽可能一致,缺点是需要基模型有较好的性能,比较容易达到上限,无法超越基模型的效果。
人设大赛算法赛场解题思路分享+亚军+赵大大大大头
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.485a311fu9lqGt&postId=3026
从图中可以看出,训练集和测试集的就诊人数比较均匀的分布在了7月到12月之间,因此可以利用这个分布分别对7-12月的数据以月为窗口进行局部维度特征提取。
3.4 模型融合
综上可知,对训练出的六个模型进行交叉验证确定最优参数,并通过线上验证证实其预测能力,我们可以得出六个模型“表现良好”的结论。再结合特征版本的差异与算法原理的差异,我们可以得出各个模型具有“差异性”的结论。
因此根据以上结论,我们可以利用以上六个模型进行平均融合生成最终的预测结果。最后,得益于模型间的差异性,融合后的模型在预测准确性和泛化性能上都有了较大的提升。
1、 对于数据的理解要以数据分析结果为基础,切记不可想当然。例如在对于就诊次数的统计时,前期想当然的认为每条记录代表一次就诊,但是后来通过数据分析发现这其实是多对一的关系。
2、 欺诈行为是一个持续的过程,要从局部多维度去提取特征,局部维度特征提取对模型性能提升起到了关键性作用。
人社大赛算法赛题解题思路分享+第五名+璞映
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.485a311fu9lqGt&postId=2990
使用随机森林和GBDT的特征重要性组件对特征进行分组分析。经过实验,只有排名靠前的特征对模型结果影响较大。有些特征虽然重要性靠前,但是人眼观察怀疑为导致过拟合,将其删除。删除特征之后,在验证集上重新训练模型,观察分数是否上升。所删特征包括:双周双月三周三月的统计、重要性弱的医院、中药饮片等。
人社大赛算法赛场解题思路分享+第六名+少生病爱家人
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.485a311fu9lqGt&postId=3010
智慧交通预测挑战赛hair团队思路分享-rank3
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.193d158032QvJJ&postId=2710
数据集的划分:如何保持线上和线下的同增同减是每次比赛大家都会特别注意的问题,毕竟线上评测一天就一次,不可能完全覆盖我们想测试的模型。我们这边也经过了一些不同线下验证集的划分策略探索,最终将2017.03~2017.06的[07:00, 09:00),[14:00, 16:00),[17:00, 19:00)作为训练集,2017.07的7点,14点,17点数据作为线下验证集。线上测试集则为2017.07的8点,15点和18点。基于此,我们基本做到了线上和线下的同增同减。
模型其实就是简单的seq2seq模型,输入为上述提取的时空特征(30个数据点),输出为下一个小时的30个数据点。
我们的模型完全抛弃了传统数据挖掘比赛中广泛应用的基于boosting-tree的模型,而是涉及了一套端对端的深度序列模型。其中的好处不言而喻,完全没有人为规则的加入,并充分利用了深度序列模型强大的长短期建模能力,模型及其稳定。在复赛后一阶段,我们的成绩基本稳定在第三,不过我们模型还有一部分没有完美的是对空间特征的端对端的建模,个人猜测top2的团队应该这方面比我们要有优势。
如果赛题组可以给出具体的道路地图,那么我们可以利用CNN来进行空间建模,从而达到完全的时空端对端系统。当然我们也可以利用有向图进行Graph Convolution,这些都是值得改进的地方。
智慧交通预测挑战赛-rank2
https://tianchi.aliyun.com/forum/postDetail?postId=2749
在生成这些特征的时候为了方便会对整个训练集做统计,然后把它当做特征来训练。这样训练时会有数据泄露,但是依然能提高线上的成绩。
第一个是这两小时最后一个时间片的travel_time,比如要预测8:00到9:00的travel_time,就把7:58-8:00这个时间片的travel_time作为一个特征。想到加这个特征是当时觉得一般来讲travel_time 的变化都是比较连续的,跳跃的情况相对较少出现,所以加这个特征可以帮助更好的预测第一个时间片即8:00-8:02的travel_time。事实证明效果非常的明显。
第二个是要预测的时间片距离前面两个小时的峰值的距离(谷值也类似)。比如6:00-8:00的travel_time的最大值在7:30-7:32,要预测的时间片是8:10-8:12,那这个特征的值就是8:10-7:30=40分钟。直觉是因为峰值一般都会间歇性出现,所以离峰值比较近的时间片travel_time可能会偏小,离得远的更可能比较大。
,最重要的要根据题目的情景找到“强特征”,比如节假日和第四类提到的两个直觉上有用的特征。这些特征基本上一个顶10个,提升非常明显。要找到这些特征需要大胆假设和联想,还有不断地实验,因为不是所有感觉上有用的特征都会实际上在你用的这个模型上有用。甚至有时候试验了一个特征发现没什么用,但是过了一段时间,加了一些其他特征之后再加这个特征又变得很有用了,这是因为不同的特征配合起来也有不同的效果,所以多尝试是有好处的。
我们使用xgboost时需要用到损失函数的二阶导数,但是MAPE的二阶导数其实是0,而如果把xgboost二阶导数设为0的时候程序会出错。这个时候咋办呢?改造二阶导数。我们其实经过了许多的探索,探索过程这里就不说了。最终如果采用的二阶导数是 1/y(真实值)**2的话。收敛速度非常块,而且LOSS的下限非常低。具体可以参考下面的这个图:在碰到使用xgboost时,LOSS FUNCTION 二阶导数为0或者不存在的时候要大胆的改造一下这个二阶导数,说不定能够找到一个更快更好的拟合方向。
具体代码:
Loss
云上贵州智慧交通预测-团队师傅被妖怪抓走了-建模思路分享-first place
https://tianchi.aliyun.com/forum/postDetail?postId=2748
尝试的深度模型有
- 仅建模时间相关性
a) Simple LSTM
b) Simple Conv1D - 时空相关性同时建模
a) Graph Convolution (Main model)
b) 使用邻接矩阵抽特征,使得Simple LSTM/Conv1D也能同时建模时空相关性。
「智慧交通预测挑战赛」藍鯨团队解决方案分享
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.193d158032QvJJ&postId=2762
我们主要采用时间序列加权回归模型(SJH)来做出预测。预测一个时间片的平均通行时间,可以用来参考的当然包括历史每一天同一时段的平均通行时间,和当天早些时候的平均通行时间。所以我们的解决方案可以分为两部分,历史预测和近左预测。
我们认为一个路段在相近的时间的平均通行时间相差较小。例如,一个路段在某一天的8:13和8:15分的平均通行时间可能比较接近。因而对于某一路段某一日某一待测时间片,我们用来预测的样本包括历史各日的同一时间片和其附近的(前后三十个)时间片。例如,待测时间片为8:31,则样本为历史各日的8:01、8:03、…、9:01。
样本的权重,显然应该和它与待测时间片的距离有关,距离越大的,权重应该越小,反之亦然,我们用距离的倒数作为权重;此外,平均通行时间受曜日的影响,因而权重还应该和曜日有关。与待测日同曜日的日子的权重最大,同为工作日或周末的日子的权重要小一些,其馀日子的权重最小,我们将这三种情况的权重分别设为1、0.5和0。将上述两种权重相乘,即为我们最终采用的权重。
用上述所选样本和所计算出的权重,利用SJH函式做出预测,即为历史预测。
四、融合
就是简单的加权融合啦。将上面两种预测加权融合。每一个路段的权重不一样,有的路段近左预测的权重大一些,有的小一些。我也没找到什么规律,我也不知道这个跟道路的长度和宽度是不是有关系。
于是我采用了比较粗暴的办法。我把测试集向前移了30天,然后对于每个路段,以0.05为步长,从0遍历到1,看看哪个权重在这30天表现最好,就对这个路段使用这个权重。就是这样
智慧交通预测挑战赛-浙闵交通大队思路分享-rank5
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.193d158032QvJJ&postId=2772
最后对于较大范围的缺失(如第12条和第93条道路在6、7月份的缺失),在训练集上不做填补(强行填补会尝试较大误差),在测试集上进行历史数据的均值填补,包括前后值、历史同时刻,历史同时段数据。
模型融合
前期模型融合有线性融合(非stacking)和线性融合(stacking)两种,交通高峰8-9时及18-19时采用线性融合(stacking),交通平峰15-16时采用线性融合(非stacking)
了不起的特技|截榜之日反超冠军
https://mp.weixin.qq.com/s?spm=5176.12282029.0.0.737815801vaJUn&__biz=MzAwNjM1ODkxNQ==&mid=400341222&idx=1&sn=868b9c0a84c6a8391889e1b5186cb832#rd
我决定删特征,大岑神决定重头实现一遍所有特征找bug,茂杰决定调参试试,三管齐下
不要被以往的经验误导,经验告诉我们,GBDT吊打RF吊打LR,然而这个微博比赛呢,大家都懂的。还是尝试,只有多尝试,才有发言权说哪个好用哪个不起作用
。 数据分析的重要性。拿到了数据,不要立即想着提特征,实现算法。而要大体知道数据是什么样的,数据的分布如何?统计一下微博等级的分布,观察一下数据
还是数据分析,看一看模型的输出结果,究竟是哪些微博被误判了,是屌丝被误判成高富帅的多,还是高富帅被误判成屌丝了,接下来才知道应该提取什么特征,还有哪些不足
定期检查!定时检查一下现有的代码,从头梳理一遍,看看有没有bug,有bug的特征不如不加。画出特征思维导图,在画的过程中,你就会发现,哦,我好想这个特征还没加,这俩特征是不是可以叉乘一下。
快速的代码迭代,不断地去验证想法。有的时候,你有了一个想法,不知道好不好用,就先实现了,然后结合以前的结果看看效果。不断地往特征池里面添加会使最终结果变好的特征
时间序列规则法快速入门
https://www.jianshu.com/p/31e20f00c26f?spm=5176.12282029.0.0.5df1311f9KqNjx
周期因子的计算和使用
A股上市公司季度营收预测-东风又绿江南岸团队技术方案(复赛第四)
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.20901580nSr5FO&postId=12040

特征筛选
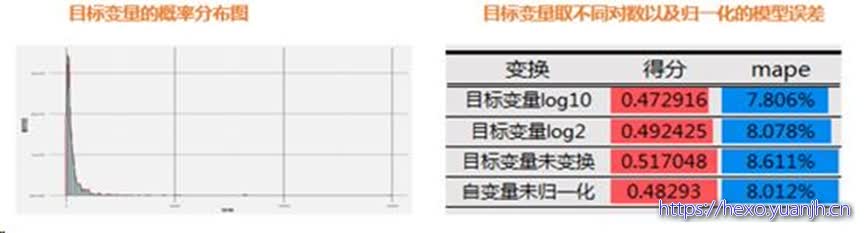
通过随机森林计算因子重要性与排名,并统计因子重要性百分比与准确率、数据量的关系;随着因子重要性百分比的增加,准确率也随之增加。当因子重要性百分比超过99%时,此时准确率仍有较大提升的空间,但因子的数量和数据量大小也显著增加;鉴于机器性能与运行时间限制,我们最终选择涵盖99.9%重要性的因子集合。
参数层评比
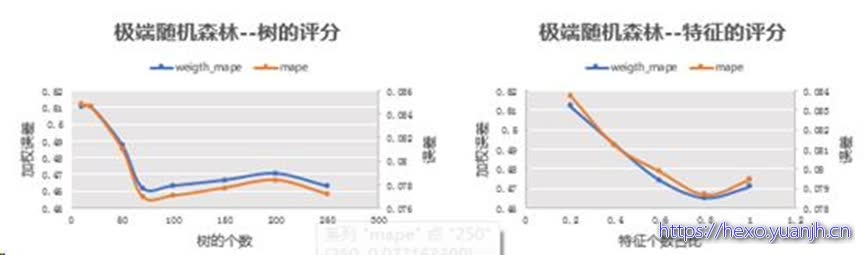
极端随机森林:当树的数量在70颗的时候,加权误差为0.462,此时的误差最小,基于确定最佳树(70)的情况下,调节特征数的大小,当特征个数占比为0.8时,此时的加权误差最小。
其他的模型也是通过上述的方式寻找最佳参数
FDDC2018金融算法挑战赛01-A股上市公司季度营收预测-Alassea lome(Rank 1)解决方案
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.20901580nSr5FO&postId=12435
1、按公司筛选:
剔除其中B股,ST,ST,测试集上的公司不删除
剔除营收数据少于4条的公司(新上市)
剔除近期停牌,存在明显财务造假的公司
2、按时间段筛选
剔除2010年之前的所有数据(考虑到久远的数据可能会导致误差)
剔除公司上市之前的数据
若公司某一时间段出现营业收入为0或者负值,剔除期间异常时间段所有数据
测试机上的公司某一时间段为ST、ST的,剔除期间所有数据 5、营业收入少于100万的时间段,剔除期间所有数据(因为测试集上的1493家公司的历史营收几乎都大于100万,且历史数据量比较多)
在剔除完这些之后,我们开始构建特征,根据申银万国提供的行业分类信息,我们将公司的一级分类作为类别特征,将一级分类中的“非银金融”拆分成了“证券”、“保险”、“多元金融”三个分类,共计30个类别特征(one-hot-encoding),由于各个公司的财务报表存在差异,所以这会导致大面积的数据稀疏的情况,对于绝大部分为空的特征,则剔除此特征,否则空的部分填0。其余的所有特征,在按照金融经验剔除了部分特征外,选择了全部暂留。
,不同的行业不同的公司,其平稳性也大相径庭。图1为某房地产公司和某银行的营收对比。房地产这种行业的波动性极大,这是预测的难点。但是银行的营收相对稳定。稳定的数据不需要很复杂的模型就可以得到让人满意的结果,所以我们决定采用了Holt-Winters和Arima时序模型。
对于季节性较强的行业(电气、电力、化工),我们加入了fiscal_period类别特征和行业特征加强季节性和反季节性的学习
对于行业整体不景气的行业(证券),我们考虑引入申万1-3级行业指数和其他行业特征
四、特征选择
步骤一:训练集默认特征全开,多轮预跑后得到所有特征的重要性
步骤二:挑选重要性前n=100的特征训练,观察loss是否下降,n的数值由机器自动搜索
步骤三:挑选loss最低的特征个数,生成新的训练集
步骤四:新的训练集进行不同参数组的grid search,确定最优参数组(模型)
步骤五:步骤三中,人为指定某些特征一定要被选中 例如:申万1级行业分类,财务报表中的某些重要特征
总而言之,将特征的个数也作为了超参数
五、模型融合
最终由于不同的组合方式,获得20+个模型,我们按照不同的行业,在2018年一季度上使用线性回归模型,确定单个行业的各模型的权重参数
FDDC大赛赛题1—季军解决方案
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.20901580nSr5FO&postId=12714
FDDC2018金融算法挑战赛01-A股上市公司季度营收预测-Quant_duet亚军解决方案
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.20901580nSr5FO&postId=12505
另外在因子方面,我们尽可能不共享因子,因此多因子模型的因子中,我们去除了营收,在深度学习模型中我们的主要输入因子就是营收。
深度学习模型
基本信息:使用历史上前四期的营业收入(以及其他一些市场数据)预测T的营收,所有季度统一训练,所有公司/相同类别的所有公司一起训练。
在深度学习模型中,我们最直接的联想是使用RNN+FC的模式,
我们进行stacking,stacking的方式是线性叠加结果,严格意义上这应该叫bagging。得到的结果优于两个模型中的任意一个。值得注意的是,如果我们在XGBoost中加入了营收这个因子,虽然XGBoost单模型的结果有了很大的改善,但是在模型结合后,结果将差与神经网络模型的结果。
初赛前10/复赛前10的比赛方案
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.6c47311fzxZaOa&postId=4472
无论是复赛,还是初赛,我们都先只预测每天的上牌量总和。
我的思路是采用决策树回归来预测具体每天的数据和当月日均数据的比值,用的是 kaggle 中广受好评的 xgboost 库。
我提取了如下几个方面20多个特征来做预测:
星期
月份
放假/工作日/调休
放假前1天/2天/3天
放假后1天/2天/3天
长假/短假等
github代码
zhchaoo/YanCityCarBand_tianchi
盐城上牌量预测,date数据反演为真实日期,论节假日的重要性
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.6c47311fzxZaOa&postId=4245
使用:Prophet
推演假期时间方法
上牌量总决赛季军比赛攻略_爱冒泡的大笨鱼320
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.6c47311fzxZaOa&postId=4939
从其中分离出两类特征出来,即星期和日期的周期性特征和节假日影响因素特征,以及潜在的线性增长趋势特征,而这两类特征,如果用同一模型来学习,效果肯定不是很好,因此分别用GBDT树模型和LR线性模型来分别学习。
说明:其中日期特征,我发现使用农历来表示,比使用阳历效果更好,可能是由于车管所上牌严格按照准守法定节假日,而法定节假日大都是按照农历来划分的,因此使用农历日期的特征可以更好捕获上牌受节假日的影响
上牌量总决赛季军比赛攻略_顺其自然657团队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.6c47311fzxZaOa&postId=4941
Prophet是一个加法模型,模型认为预测或者拟合的时间序列值是由趋势加上季节性变化(包括普通的季节性变化和节假日特征)加上不确定因素所构成的,由于统计学上的意义,不确定性的因素在一个高度拟合的合适模型中是随机噪声,那么我们由估计量的一致性可以得到,对于点估计,多次预测的统计量的均值是等于实际值的。因此在模型中,我们首先使用已知的数据进行拟合,这个拟合是基于MCMC的,也就是蒙特卡洛模拟,拟合之后所得到的参数即可用于预测。为了确定参数选取达到了最优水平,我们不断在已给的数据集上测算均方误差,从而得到最终结果。
上牌量总决赛亚军比赛攻略_北方的郎队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.6c47311fzxZaOa&postId=4882
特征评估和验证: 选择特征的时候使用了相关性,pca,selectkbest等方法。程序对调整后的特征自动进行实验验证及记录,以Xgboost和LightGBM的线下成绩为判断依据。 使用过类似贪心法的办法进行自动模型探索,即先放入必不可少的几个特征后,通过代码对比每次增加新特征之后的成绩,确定是否保留这个特征。然后继续直到把所有特征都过一遍。
印象盐城·数创未来大数据竞赛 - 盐城汽车上牌量预测题解
https://github.com/thuwyh/tianchi-shangpai-solution?spm=5176.12282029.0.0.20e519b7ZBKngv
阿里天池比赛 印象盐城·数创未来大数据竞赛 - 盐城汽车上牌量预测
https://github.com/gammagao/tianchi1?spm=5176.12282029.0.0.1200311fDZ366j
天池工业AI总决赛季军比赛攻略_SoapII 团队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.2996311fWWIdny&postId=4043
311X53特征存在跳变的缺失值,而且从数据的分布中可以看出,存在突然增大和较小的值,因此用mean进行补全会使得数据受到较小的和较大的值的影响,因此针对缺失值,采用median进行补全。补全以后效果如下:
补全以后的311X53特征如图5所示,该特征值的表现很好,使得在XGBOOST中的数据得分为第二。
可以看出:MSE的值越小代表预测的结果和真实值越接近,效果越好。因此,为了使得预测结果更能符合真实值,我们将标签值Value扩大10,20,40…,140,到100倍进行实验,实验结果如图9所示。然后将得出的真实值再除以100,即为最终的xgb预测值。这是因为xgb训练是根据目标函数和进行不断迭代的训练,目的也是使得mse最小。
首先在复赛初期我们采用单一树模型,当到达一定成绩后线下cv分数下降,线上分数反而高,产生了过拟合。
数据中0值也许作为缺失值来处理,我们通过使用中位数、平均值等来填充后发现,中位数的效果最好,通过补全后原有模型的线下cv有明显提升,线上也有大幅提升。
工业AI赛季军攻略_大熊猫大人队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.2996311fWWIdny&postId=4018
因此数据样本只有几百个,而特征却有几千个,是一个特征数大于样本数的问题。赛题数据中的几千个特征代表不同的工序参数,但是特征的意义不明。因为特征太多,没有具体研究每个特征的分布。
主要关注了Y值的分布,发现Y值基本上符合正态分布;关注了缺失值的分布情况,认为缺失值信息不能作为一种有用的信息;关注了类别特征的分布。
Lasso模型使用了L1正则化,我将其用于特征选择,在初赛中的取得的预测效果不错。后来我意识到这种特征选择方法地鲁棒性也许不够强。比方说,对这批数据用可以选出一批特征,对另一批数据也许就不能选出完全相同的特征。
因此,为了提高特征选择的鲁棒性,从训练集中抽取了多个不同的子集,然后对每个子集进行L1正则化特征选择,得到多个特征子集,最后统计几乎在每个子集中都被选中的特征作为最终的特征集。至此总共还剩下一百多个特征。
天池工业AI季军比赛攻略_itself队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.2996311fWWIdny&postId=4037
总决赛亚军比赛攻略_px1008队
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12282027.0.0.2996311fWWIdny&postId=4015
这次比赛也是比较坎坷,在初赛的时候成绩是一度达到了300多名,当时是想着组合好多模型,能够提高成绩,结果越做越复杂,成绩是稳步下降。直到换数据的时候就抱着试一试,自己已经试了这么久复杂的不行,那就简单点,就用了最简单的单模型提交了结果。万万没想到,竟然顺利进入了复赛。其实,个人的想法是模型不一定要多复杂,有时候简单的模型反而拥有更好的稳定性,能够适用于更多的数据。经过评委老师的点评,感觉上还是对数据的认识不够,并没有完全立足数据。
列表
【天池大赛】历届比赛资料:
https://tianchi.aliyun.com/forum/postDetail?spm=5176.12281976.0.0.3ff876d8wJVR3p&postId=3192
https://tianchi.aliyun.com/forum/?#raceId=231591
https://tianchi.aliyun.com/forum/#type%3D%E5%A4%A7%E8%B5%9B%26pageIndex%3D1%26raceId%3D231660
https://tianchi.aliyun.com/forum/?#raceId=231646
https://tianchi.aliyun.com/forum/?#raceId=231641
https://tianchi.aliyun.com/forum/?#raceId=231640
https://tianchi.aliyun.com/forum/?#raceId=231633