某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
RNN结构
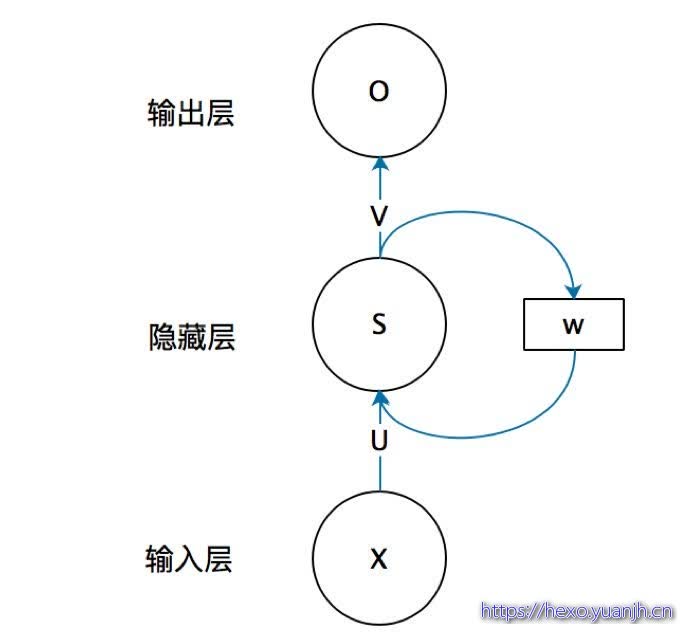

这个抽象图对应的具体图:
DNN的权重矩阵每层都不一样,而RNN每个时刻的权重矩阵都是相同的,即一个单层RNN的权重矩阵只有三个:U UU、V VV、W WW,和两个权重向量b bb、c cc。这说明RNN每个时刻做的事情是一样的,即接收输入信息和上个时刻的输出信息,输出当前时刻的信息。
可以把隐藏层节点s t s_ts
当成一个记忆单元,它用来捕获之前所有时刻的信息。
上面图中每个时刻都有输出,但是有的任务没必要这样做。比如文本分类时,我们只关心最后的输出,而不需要每个词都有输出;同理我们也可能不需要每个时刻都输入。
RNN存在问题:
a、梯度消失 ;梯度消失就是一定深度的梯度对模型更新没有帮助。
b、梯度爆炸;
b、长期依赖问题
梯度消失原因简述:
更新模型参数的方法是反向求导,越往前梯度越小。而激活函数是 sigmoid 和 tanh 的时候,这两个函数的导数又是在两端都是无限趋近于0的,会使得之前的梯度也朝向0,最终的结果是到达一定”深度“后,梯度就对模型的更新没有任何贡献。
梯度爆炸原因简述:
长期依赖问题:相关信息和当前预测位置之间的间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
解决办法:升级版的RNN——LSTM。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
CNN vs RNN
CNN 需要固定长度的输入、输出,RNN 的输入和输出可以是不定长且不等长的
CNN 只有 one-to-one 一种结构,而 RNN 有多种结构,如下图: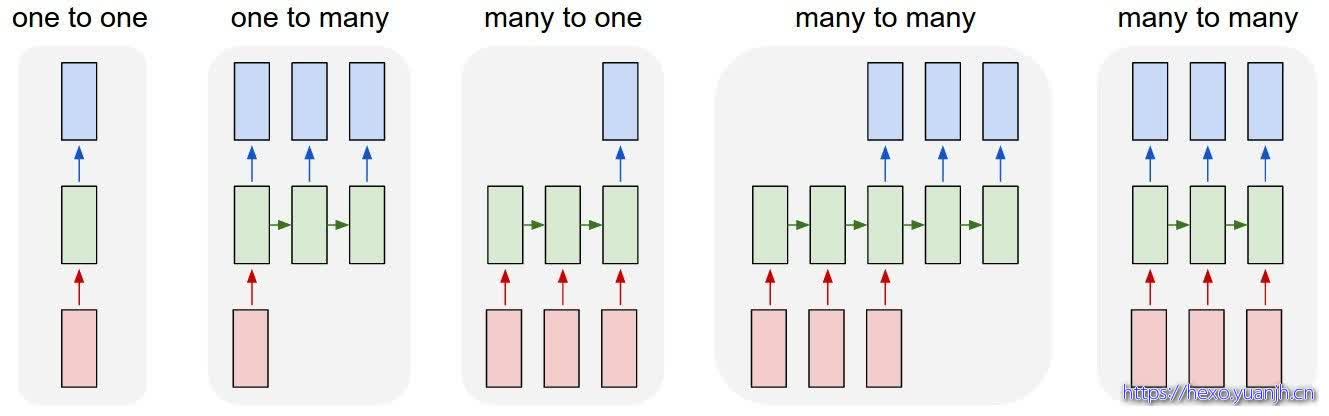
LSTM 网络
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。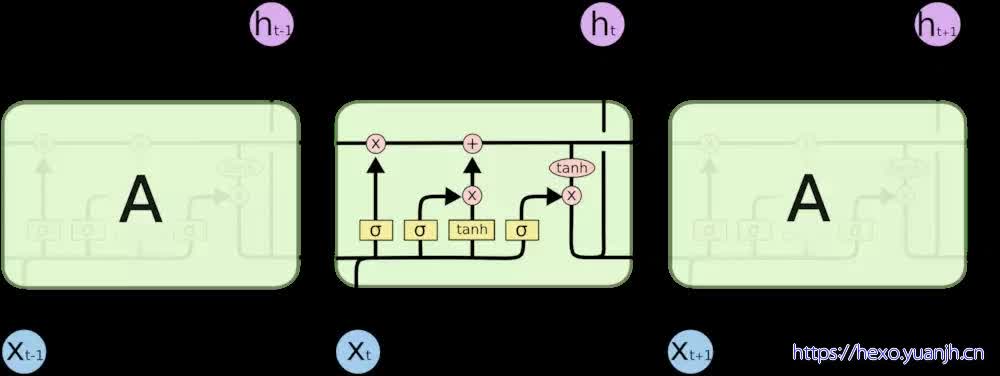
参考
一文搞懂RNN(循环神经网络)基础篇:https://zhuanlan.zhihu.com/p/30844905
RNN 结构详解(Rnn的多种结构):https://www.jiqizhixin.com/articles/2018-12-14-4
【转载】RNN详解:https://www.cnblogs.com/veagau/articles/11767977.html
RNN快速入门(超赞讲解):https://www.jianshu.com/p/1a12623f24eb