宏观资料
源码:https://cdn.kernel.org/pub/linux/kernel/tools/perf/v5.9.0/perf-5.9.0.tar.gz
或者:linux-tools-common,linux-tools-4.4.0-62-generic
在线手册:https://man7.org/linux/man-pages/man1/perf-stat.1.html
命令大全手册:Linux性能分析工具合集之——perf(一):命令介绍:https://zhuanlan.zhihu.com/p/544496209
支持多线程,支持内核态,用户态
基础原理
ftrace的跟踪方法是一种总体跟踪法,换句话说,你统计了一个事件到下一个事件所有的时间长度,然后把它们放到时间轴上,你可以知道整个系统运行在时间轴上的分布(这部分可参考,参考文献,一文搞懂 | Ftrace 的实现原理)。这种方法准确度很高,但跟踪成本也很高。
perf提供的是一种抽样形态的跟踪方法。其原理是:每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。这个原理图示如下: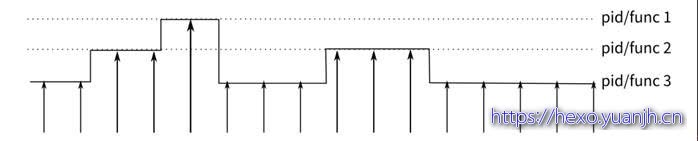
perf使用更多是CPU的PMU计数器,PMU计数器是大部分CPU都有的功能,它们可以用来统计比如L1 Cache失效的次数,分支预测失败的次数等。PMU可以在这些计数器的计数超过一个特定的值的时候产生一个中断,这个中断,我们可以用和时钟一样的方法,来抽样判断系统中哪个函数发生了最多的Cache失效,分支预测失效等。
通过改变采样的触发条件可以获得不同的统计数据:
以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布。
以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。
perf 中能够触发采样的事件有哪些。
事件分为以下三种:
1)Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
2)Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
3)Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
上述每一个事件都可以用于采样,并生成一项统计数据,时至今日,尚没有文档对每一个 event 的含义进行详细解释。
命令概况
全局性概况:
perf list**查看当前系统支持的性能事件;**
perf bench对系统性能进行摸底;
perf test对系统进行健全性测试;
perf stat**对全局性能进行统计;**
全局细节:
perf top可以实时查看当前系统进程函数占用率情况;
perf probe可以自定义动态事件;
特定功能分析:
perf kmem针对slab的系统性能分析;
perf kvm针对kvm虚拟化分析;
perf lock分析锁性能;
perf mem分析内存slab性能;
perf sched分析内核调度器性能;
perf trace记录系统调用轨迹;
最常用功能perf record,可以系统全局,也可以具体到某个进程,更可以具体到某一进程某一事件;可宏观,也可以很微观。
pref record记录信息到perf.data;
perf report生成报告;
perf diff对两个记录进行diff;
perf evlist列出记录的性能事件;
perf annotate**显示perf.data函数代码;**
perf archive将相关符号打包,方便在其它机器进行分析;
perf script将perf.data输出可读性文本;
可视化工具perf timechart
perf timechart record记录事件;
perf timechart生成output.svg文档;
由于涉及命令太对,不可能依次研究测试,仅测试加粗体部分。
命令详情
perf list
简介
列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。
perf list不能完全显示所有支持的事件类型,需要sudo perf list。同时还可以显示特定模块支持的perf事件:hw/cache/pmu都是硬件相关的;tracepoint基于内核的ftrace;sw实际上是内核计数器。
参数:
hw/hardware显示支持的硬件事件相关,如:sudo perf list hardware
sw/software显示支持的软件事件列表:
cache/hwcache显示硬件cache相关事件列表:
pmu显示支持的PMU事件列表:
tracepoint显示支持的所有tracepoint列表,这个列表就比较庞大:
常见命令:
sudo perf list
sudo perf list hardware
示例
sudo perf list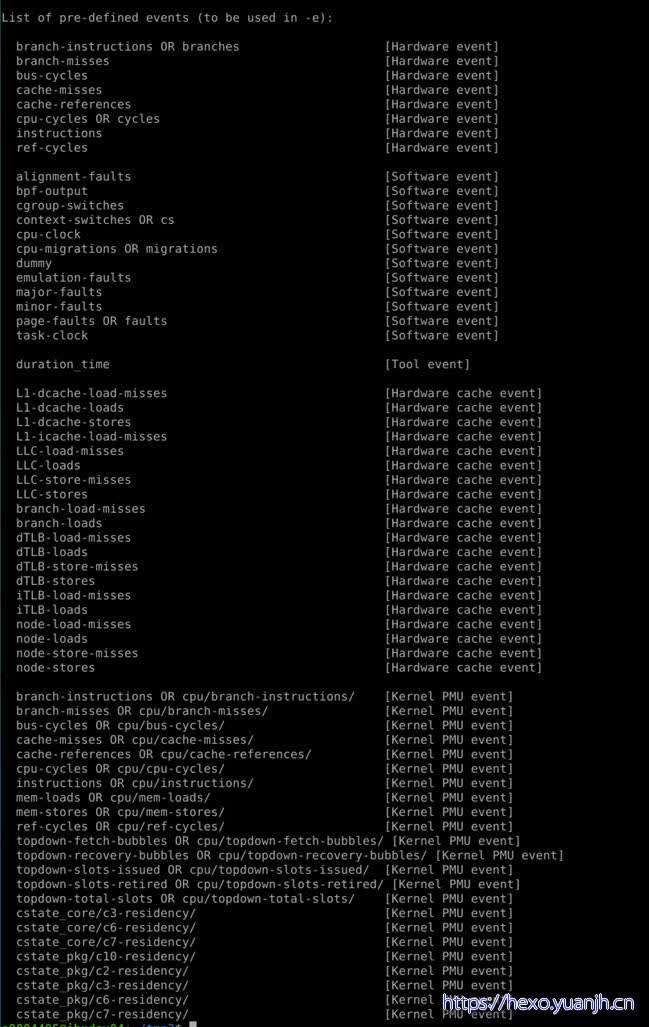
sudo perf list hardware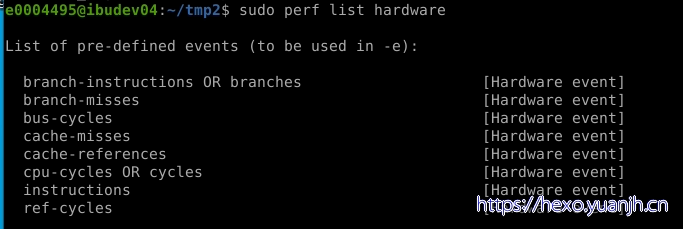
sudo perf list sw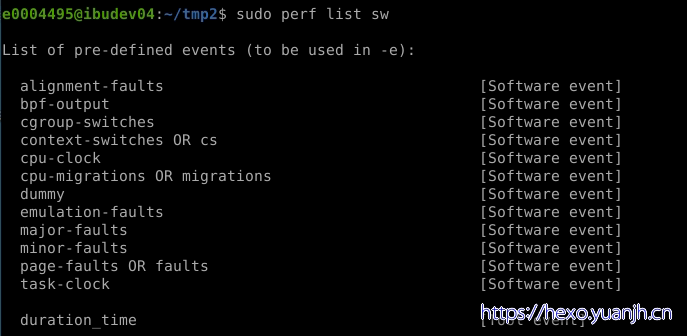
page fault缺页异常
major page fault,这种类型的缺页可以通过 Disk IO来满足,
minor page fault,这种缺页可以直接利用内存中的缓存页满足。
为什么数据已经被加载内核中的Page Cache了,理论上说直接访问就行了,为什么还要触发一次minor fault呢?
这里给出答案,懂得人可以略过,主要是因为虚拟地址和物理地址的映射关系并没有建立,我们知道Linux进程访问一块内存实际上使用的是虚拟内存,必须把对应虚拟地址空间和物理页面进行了映射才能够正常访问,那么vma结构体实际仅仅表示一个虚拟地址空间,必须把内核中Page Cache中的物理地址与进程vma虚拟地址空间进行映射才能正常被进程访问到
关于cpu-clock和taks-clock
1 | PERF\_COUNT\_SW\_CPU\_CLOCK |
Stackoverflow上的解释:
1 | 1) By default, **perf stat shows task-clock,** and does not show cpu-clock. Therefore we can tell task-clock was expected to be **much more useful.** |
perf stat
简介
执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等。虽然perf top也可以指定pid,但是必须先启动应用才能查看信息。perf stat能完整统计应用整个生命周期的信息。
参数:
1 | -e:选择性能事件 |
常用命令:
1 | 分析系统:sudo perf stat -a ^C |
测量多个事件,只需提供一个用逗号分隔的列表,其中没有空格:
1 | perf stat -e cycles,instructions,cache-misses \[...\] |
示例
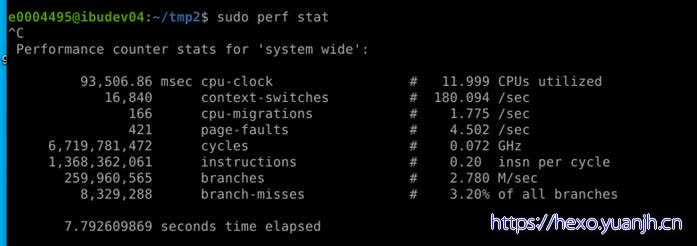
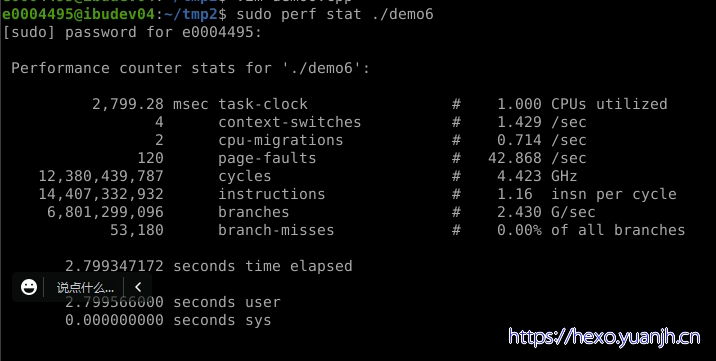
1 | Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。 |
仅测量用户级别,有增加一个修饰词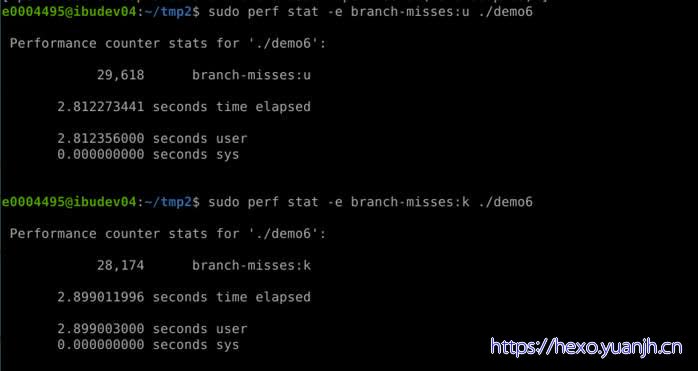
所有用户态,用*:u?实测不行
perf record
简介
收集采样信息,并将其记录在数据文件perf.data中。随后可通过perf report对数据文件进行分析。
perf record和perf report可以更精确的分析一个应用,perf record可以精确到函数级别。并且在函数里面混合显示汇编语言和代码。
参数:
1 | -e:选择性能事件 |
常见命令:
1 | sudo perf record -a -g ./demo6 |
特定频率采样特定进程:
1 | perf record -F 999 -p 997 #采样频率设置为999Hz,每秒采样999次 |
示例

perf report
简介
读取perf record创建的perf.data数据文件,并给出热点分析结果。
参数:
1 | -i:输入的数据文件 |
常用命令:
1 | sudo perf report -i perf.data |
thread后界面和上面命令,当前命令区别是啥
或者直接annotate
annotate 来单独分析函数信息:sudo perf annotate func2
示例
sudo perf report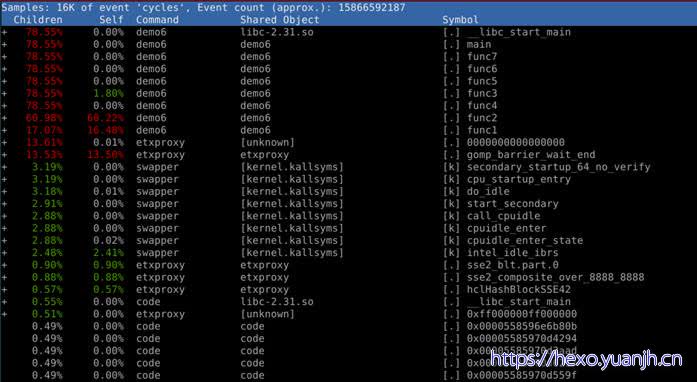
字段含义:
1 | Children:总时间(包含调用其他函数事件) |
问题:report -c demo6 进去在出来后不同(单进程的)
sudo perf report -c demo6,显示左1
之后进到main中,再zoom into demo6 thread,则显示左二,二者应该是相同的吧。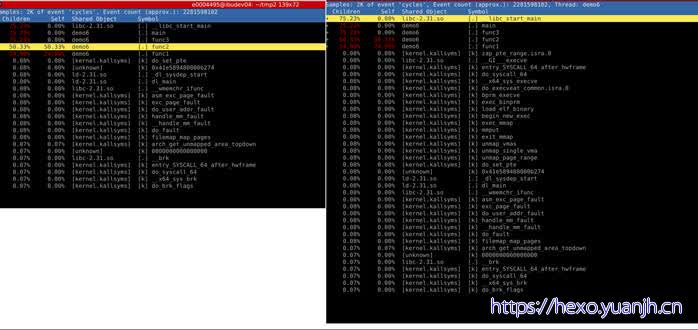
1 | sudo perf report -D |
问题:这个和perf script结果差异较大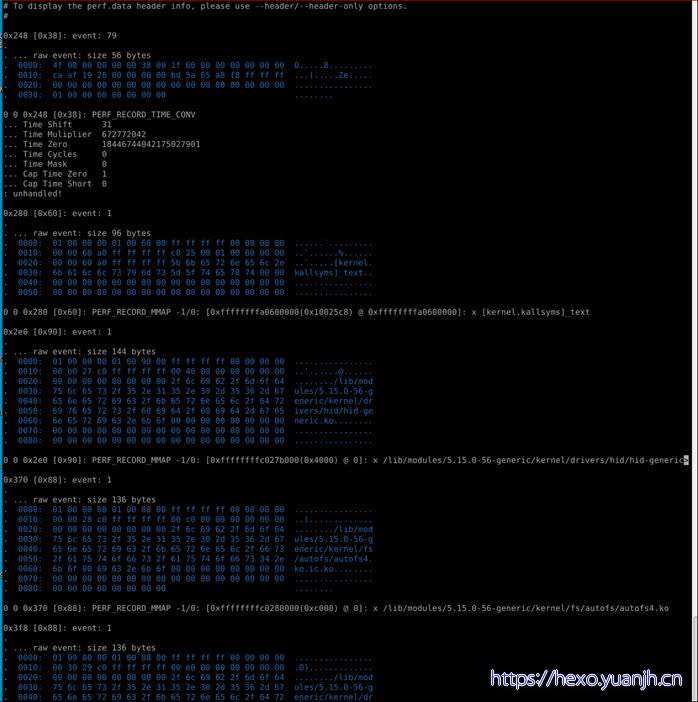
根据paraent过滤:sudo perf report -g -c demo6 –parent main
问题:右侧和other也会混进来,而且main也不会那么多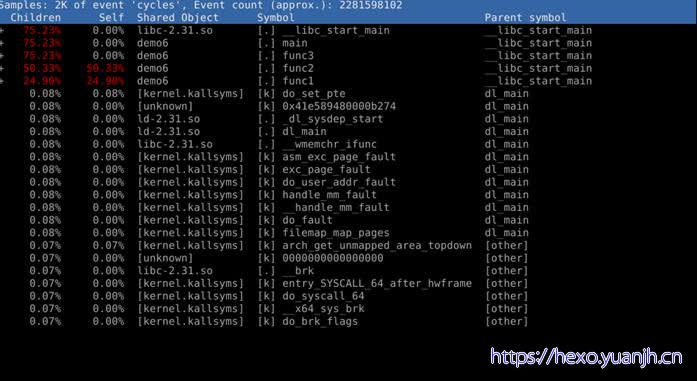
导出到文件:perf report -i perf.data > perf.txt
控制显示字段
1 | sudo perf report -g -c demo6 -F sample,period,pid,symbol,parent,cpu,transaction,trace,time,local_weight,weight,trace |
不好理解:demo6而言libc_start_main只会执行一次,为何下面这么多?Func1,func2一样的。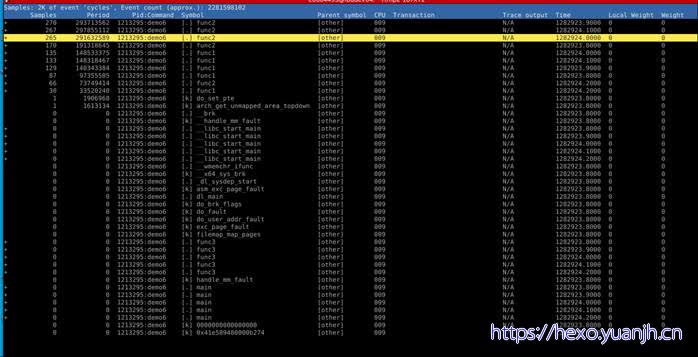
显示超过一定阈值的记录
1 | sudo perf report -c demo6 --percent-limit 1.0 |

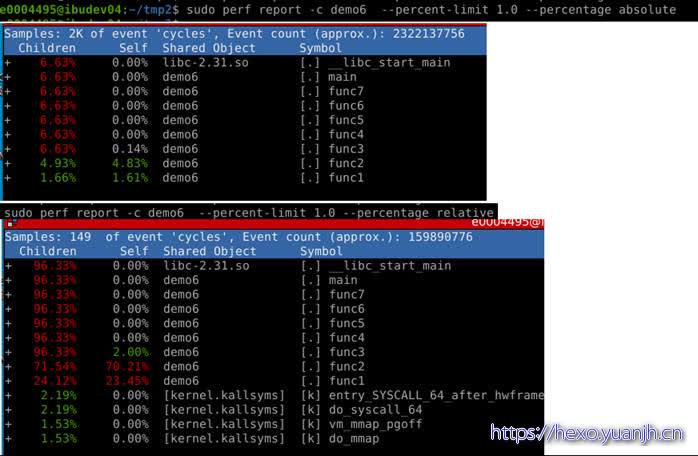
显示总时间,采集次数
sudo perf report -c demo6 –show-total-period –n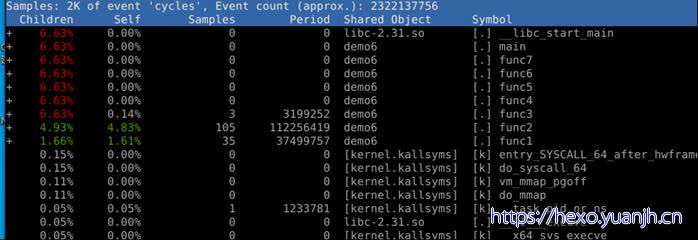
限制采集层次
sudo perf report -c demo6 –percent-limit 1.0 –show-total-period -n –max-stack 4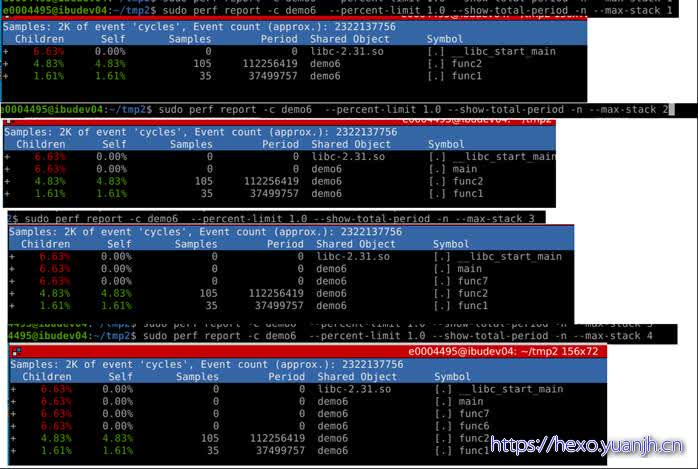
问题:不用-g进行编译,一样可以分析出结果,todo why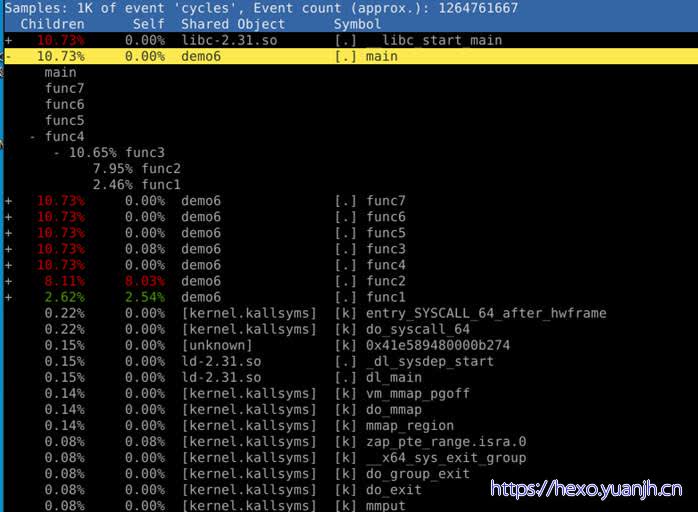
使用-g编译,分析出结果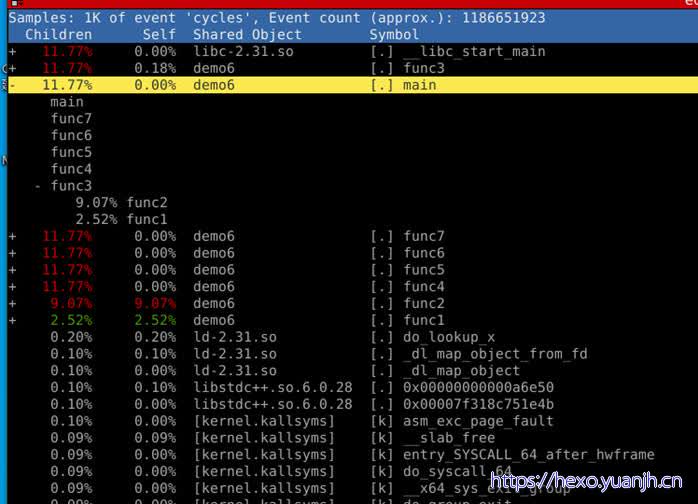
想进一步切入函数内部?汇编级别解析。
annotate 来单独分析函数信息:sudo perf annotate func2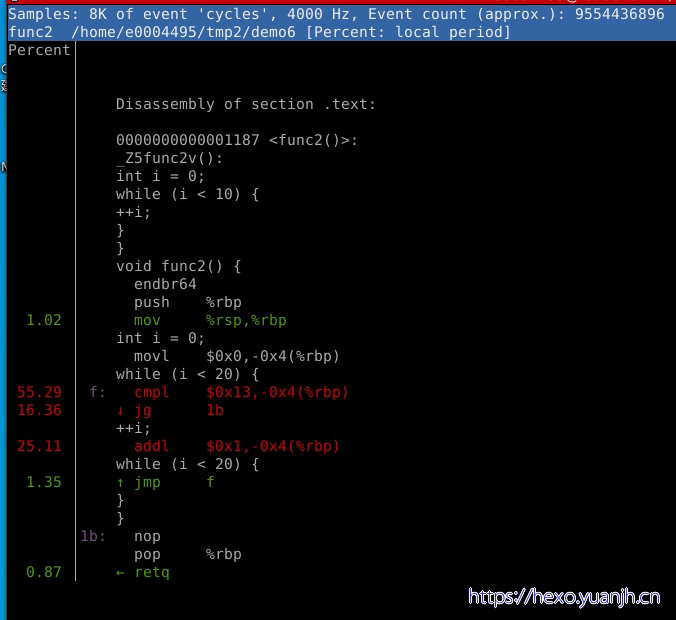
perf timechart
简介
针对测试期间系统行为进行可视化的工具。
1 | perf timechart record <option> <command>用于记录整个系统或者一个应用的事件,还可以加option记录指定类型的事件。 |
-w调整输出的svg文件长度,可以查看更多细节。
-p可以指定只查看某些进程输出,使用方式:sudo perf timechart -p test1 -p thermald
当线程太多影响svg解析速度的时候,可以通过-p指定特定线程进行分析。如果需要几个线程,每个线程采用-p xxx。
sudo perf timechart record -T ./demo6 && sudo perf timechart –p demo6
示例
1 | # 运行测试程序 |
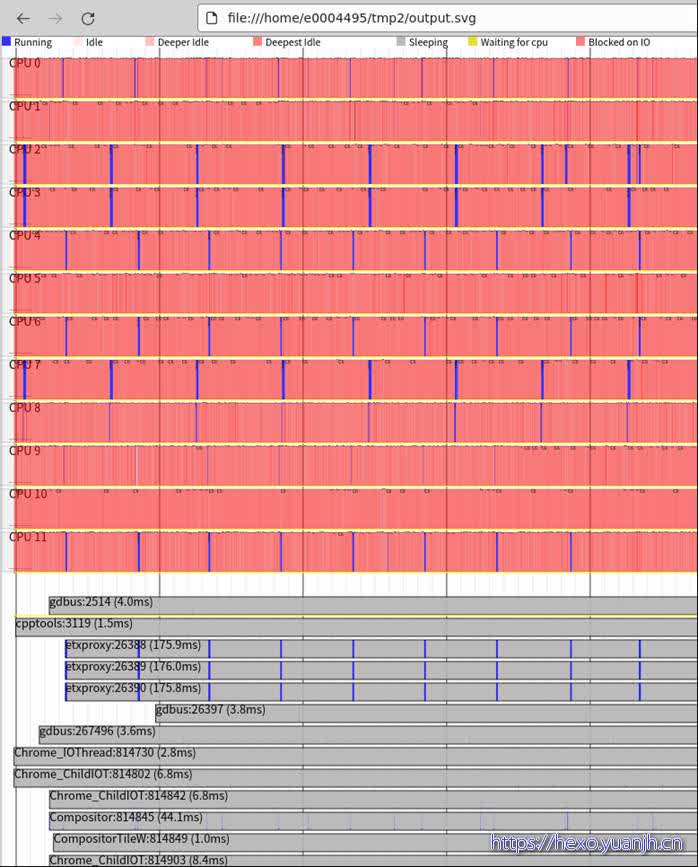
只能做基础的缩放动作,其他动作均不响应。
1 | sudo perf timechart record –T |
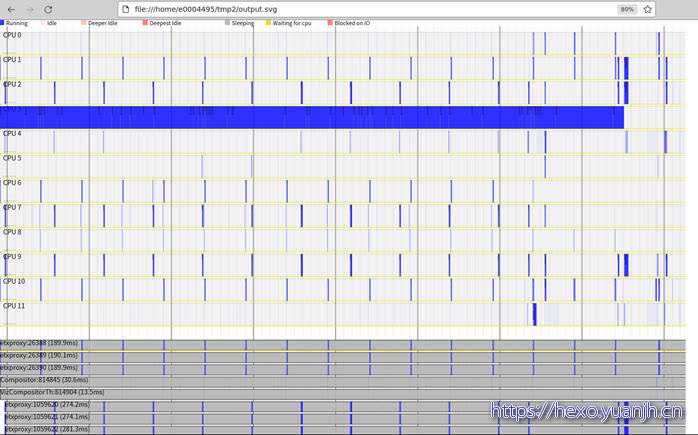
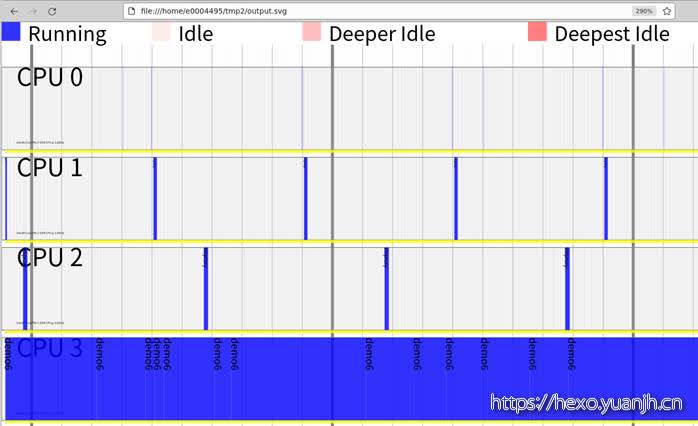
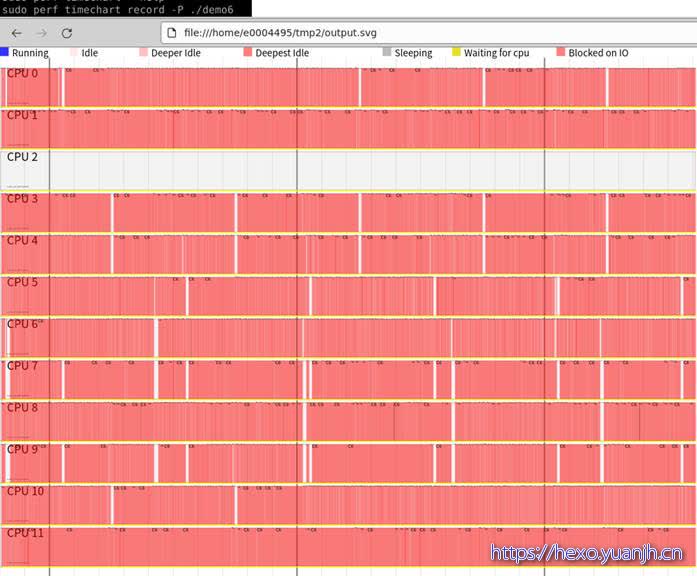
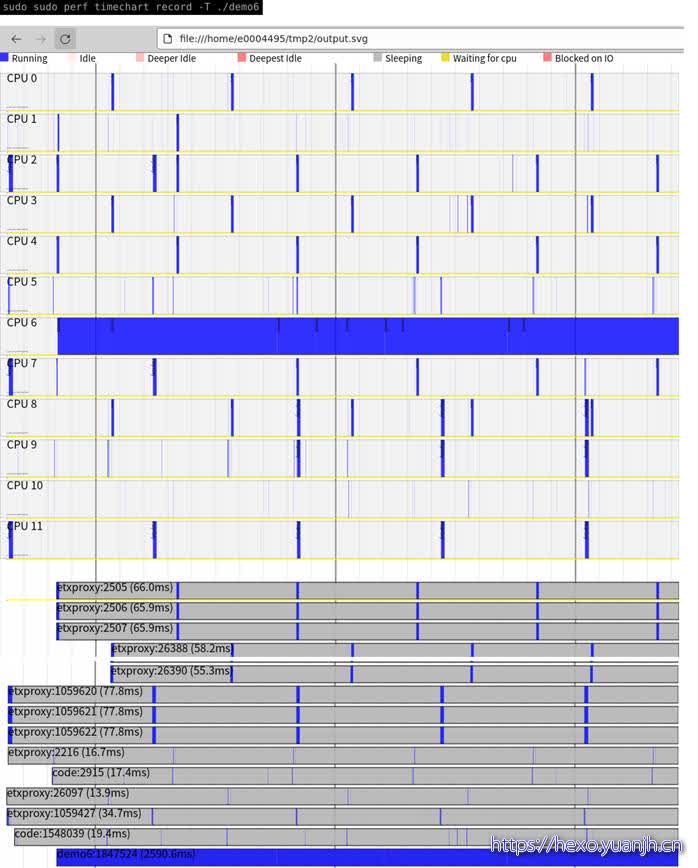
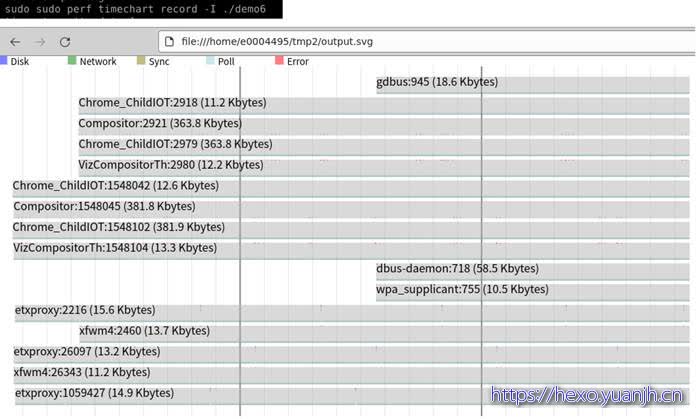
问题:上面几个图和参数的关系,感觉参数含义注解和图含义对应不起来
sudo perf timechart –highlight demo6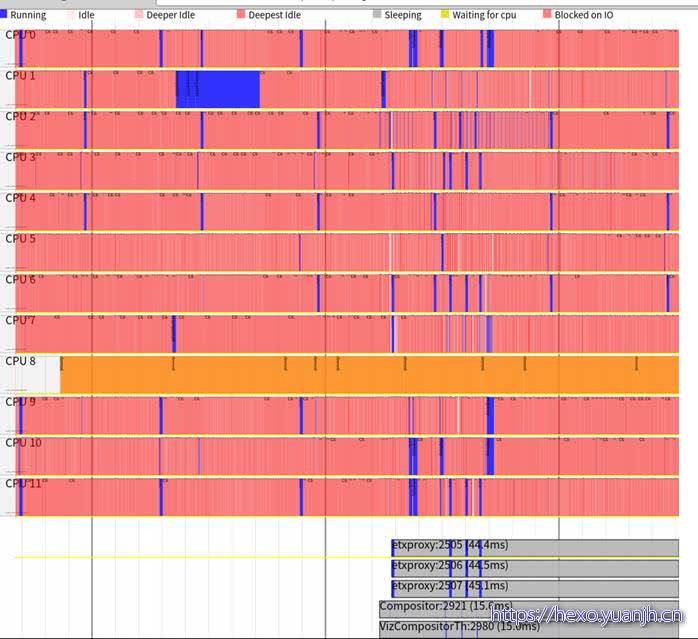
采集特定的app,命令行传入app或指定pid
问题:采集特定app,支持,但实际依然是全局采集,还需要结合pid过滤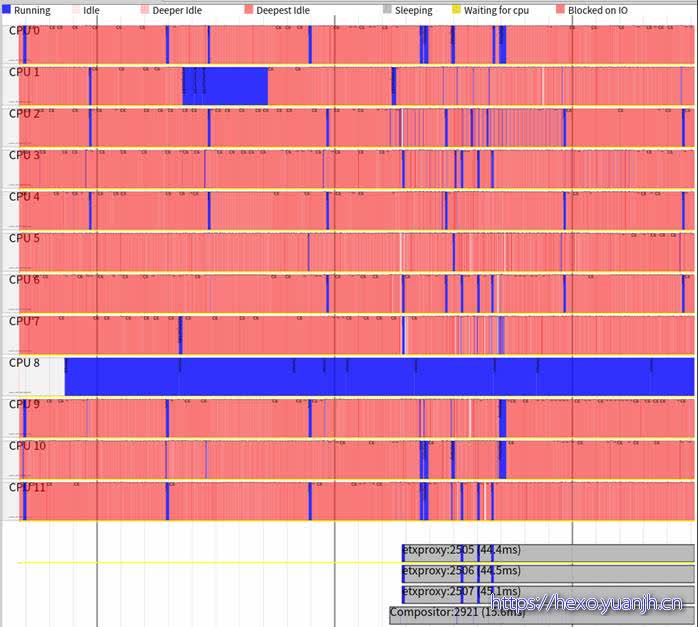
采集特定pid:可采用显示时过滤方式,
-p, –process
Select the processes to display, by name or PID
sudo perf timechart record ;sudo perf timechart -p 1330371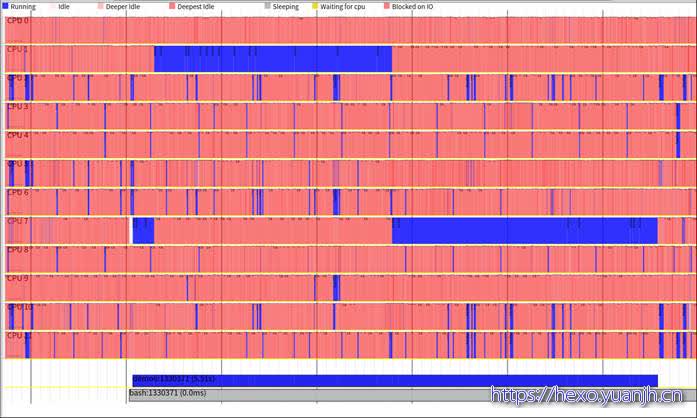
上部的cpu部分并没有少(直观理解应该只显示demo6相关进程),但底部的app变少了。
sudo perf timechart -p demo6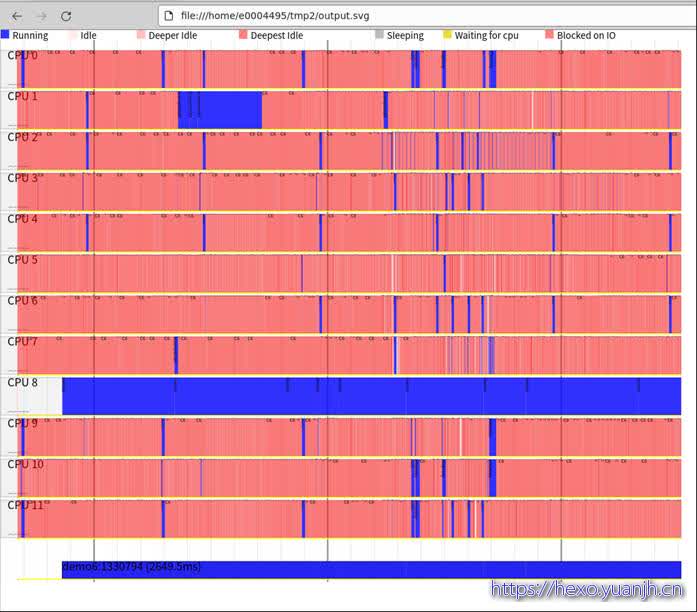
和上面结果还是有差异的,截图底部少了一个进程,主要是bash进程。
xperf script
简介
执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等。
Tom Zanussi 将 perl 和 python 解析器嵌入到 perf 程序中,从而使得 perf 能够自动执行 perl 或者 python 脚本进一步进行处理,从而为 perf 提供了强大的扩展能力。因为任何人都可以编写新的脚本,对 perf 的原始输出数据进行所需要的进一步处理。这个特性所带来的好处很类似于 plug-in 之于 eclipse。
参数:
1 | --header,实测多了无用的header信息 |
示例
基础命令,解析perf.data内容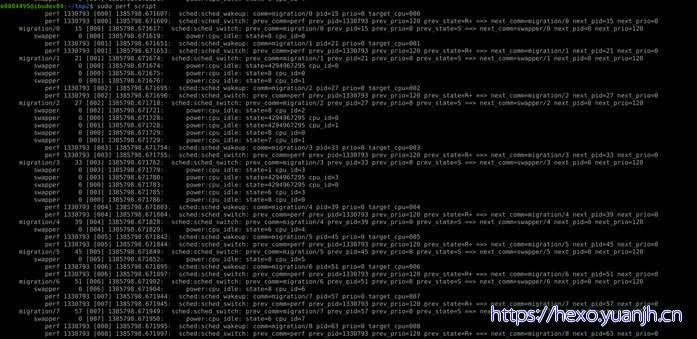
字段含义:
perf probe
用于定义动态检查点。
详情参考:暂不做重点研究,不可能每个函数手工添加检查点
perf probe笔记:https://blog.csdn.net/qq_38349235/article/details/126143881
简介
能够动态地在想查看的地方插入动态监测点
root@VM-0-9-ubuntu:~#perf probe schedule:12 cpu
上例利用 probe 命令在内核函数 schedule() 的第 12 行处加入了一个动态 probe 点,和 tracepoint 的功能一样,内核一旦运行到该 probe 点时,便会通知 perf。可以理解为动态增加了一个新的 tracepoint
示例
定义追踪的事件:sudo perf probe –add tcp_sendmsg –f
追踪1s内的系统事件:sudo perf record -e probe:tcp_sendmsg_1 -aR sleep 1
查看结果:perf script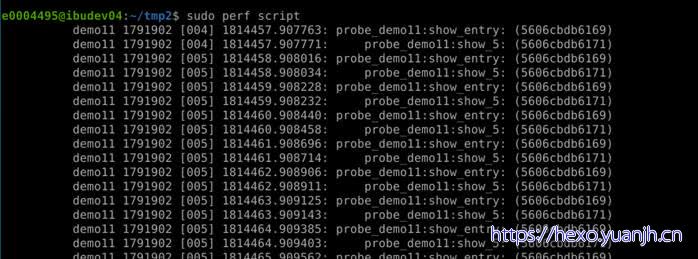
各字段含义:
Name pid CPU time/us group:event address
test 15423 [002] 12704.994176 probe_test:show_entry (555b8f07b4)
xperf sched
简介
perf sched提供了许多工具来分析内核CPU调度器的行为。你可以用它来识别和量化调度器延迟的问题。
参数:
1 | record <command>:记录测试过程中的调度事件 |
统计每轮 task switch 时,之前在 CPU 上运行的那个 “prev” 线程得到的执行时间 (run time) ,以及该线程在获得这次执行机会前的休眠态等待 (wait time) 和运行态等待 (sch delay) 时间
示例
perf sched latency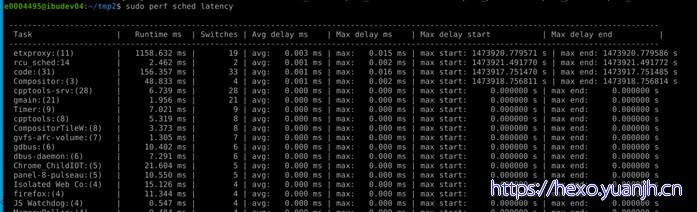
Task:进程的名字和 pid
Runtime:实际运行时间
Switches:进程切换的次数
Average delay:平均的调度延迟
调度延迟:调度延迟是保证每一个可运行进程都至少运行一次的时间间隔,翻译一下,是指一个task的状态变成了TASK_RUNNING,然后从进入 CPU 的runqueue开始,到真正执行(获得 CPU 的执行权)的这段时间间隔。
调度周期,调度周期的含义就是所有可运行的task都在CPU上执行一遍的时间周期,而Linux CFS中这个值是不固定的,当进程数量小于8的时候,sched period就是一个固定值6ms,如果runqueue数量超过了8个,那么就保证每个task都必须运行一定的时间,这个一定的时间还叫最小粒度时间,CFS的默认最小粒度时间是0.75ms,使用sysctl_sched_min_granularity保存。
Maximum delay:最大延迟
perf sched timehist:每次任务切换的信息都展现出来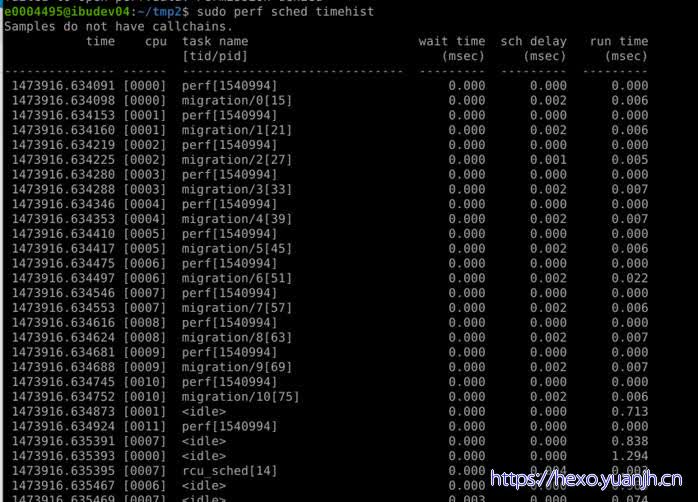
更详细的任务切换信息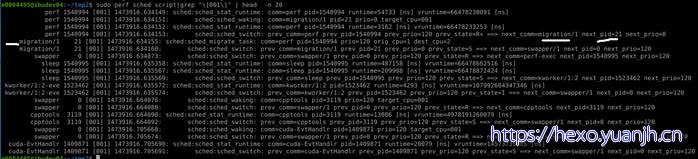
问题:字段解析样例,没看懂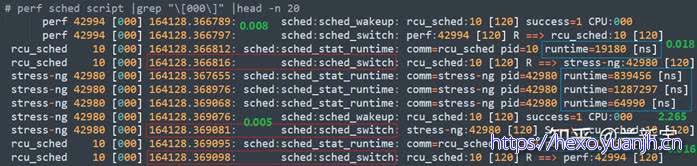
此处也用到了 “sched_wakeup” 和 “sched_switch” 这 2 个 tracepoint,后者的时间点(上图红框部分)和前面 “timehist” 输出的第一列完全吻合,而如果 “wakeup” 和 “switch” 是前后连在一起的,那两者的时间差正好是 “timehist” 输出中第五列 “sch delay” 的时长。
另外,”script” 还包括了 “sched_stat_runtime”,其统计的是每两次 task switch 之间的 “runtime”(上图蓝框部分),求和的话,就正好等于 “timehist” 输出中第六列 “run time” 的时长。
update_curr() –> trace_sched_stat_runtime
事实上,在使用 “timehist” 功能时,如果加上 “-wn –state” 的参数,也能显示一个任务被 awaken 的时刻,和作为 “prev” 的线程 schedule-out 后的状态。
perf trace
简介
strace inspired tool(类似strace)。
参数:
1 | -p, --pid <pid> trace events on existing process id |
特定进程:perf trace -p $PID -s
示例
sudo perf trace –s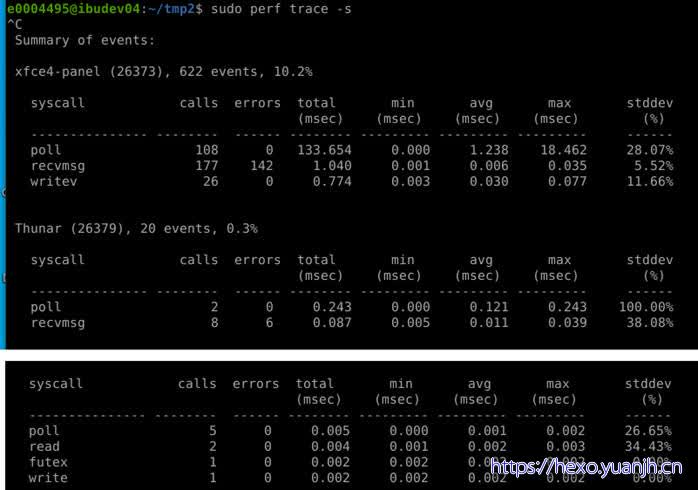
sudo perf trace ls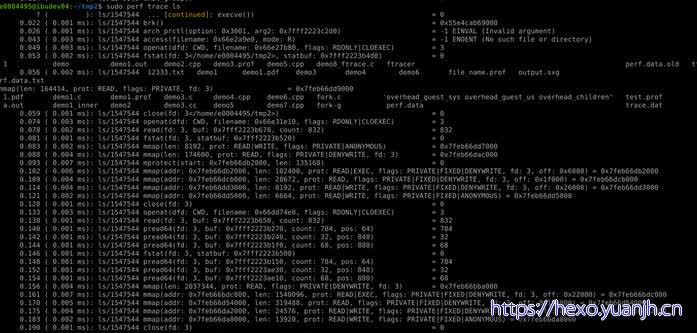
问题:字段含义找不到相关说明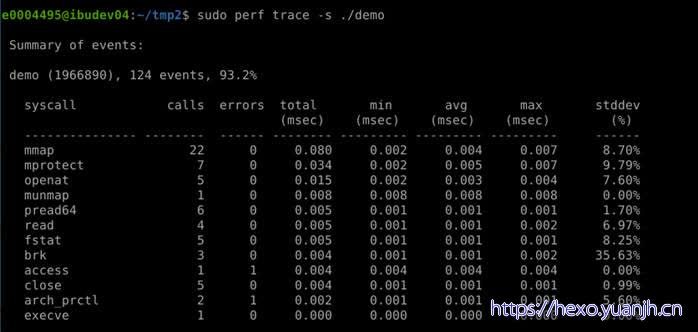
问题:都是系统调用,没有针对用户态函数的统计
strace
简介
strace 究竟能做什么呢?
它能够打开应用进程的这个黑盒,通过系统调用的线索,告诉你进程大概在干嘛。
strace 有两种运行模式。
一种是通过它启动要跟踪的进程。用法很简单,在原本的命令前加上 strace 即可。比如我们要跟踪 “ls -lh /var/log/messages” 这个命令的执行,可以这样:
strace ls -lh /var/log/messages
另外一种运行模式,是跟踪已经在运行的进程,在不中断进程执行的情况下,理解它在干嘛。 这种情况,给 strace 传递个 -p pid 选项即可。
Strace典型使用场景,参考:
strace 可以解决什么问题? | Linux 中国:https://zhuanlan.zhihu.com/p/362348075
案例三:用调试工具掌握软件的工作原理:https://blog.51cto.com/ahuo/5317283
Strace的介绍与使用:https://www.cnblogs.com/skandbug/p/16264609.html
示例
strace -c 统计系统调用分析的结果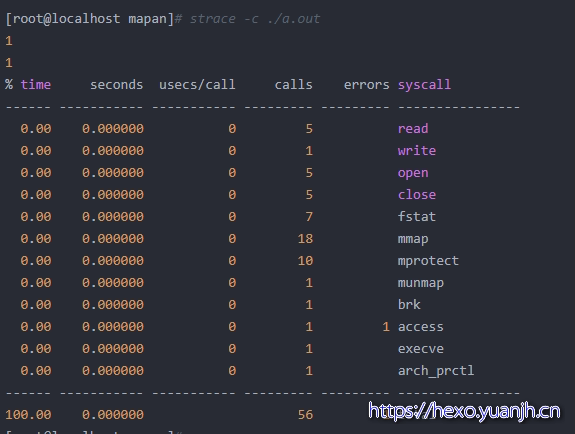
strace -T 打印每个系统调用所花的时间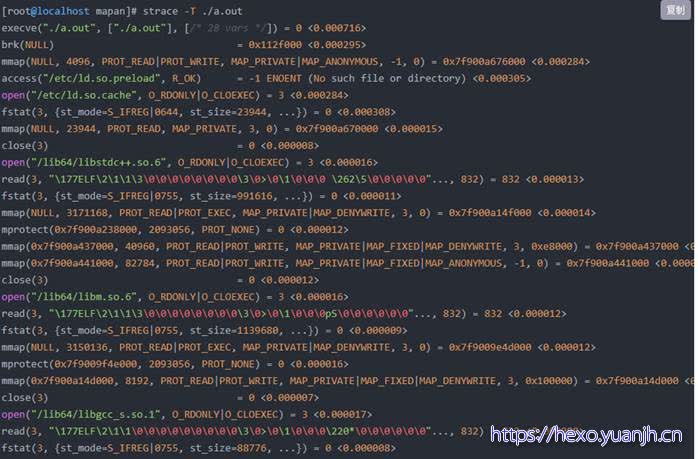
字段含义:函数,入参,返回值
使用方法步骤
其他
工具的宏观理解
两部分:
第一部分:非严谨采样方法,某个特定事件,总发生再哪些地方,
特例:如果这个特定时间是时钟周期,那么统计就是各函数的运行时间
第二部分:严谨的统计方法,特定系统函数(接口)的调用次数,各次调用时间,以及基于此的相关统计量。
Perf是对一系列内核工具的封装的简易接口(工具),或者和其他工具的对标。
常见问题:
问题01
Perf report为例,实际调用链应该非常深的,实际看起来还行,主要原因是只会在对内核态的采集,只会再检查点检查,并非所有函数都显示。
目前测试结果看,用户态的是全部显示的,可以采用层次过滤,稍微控制下
问题02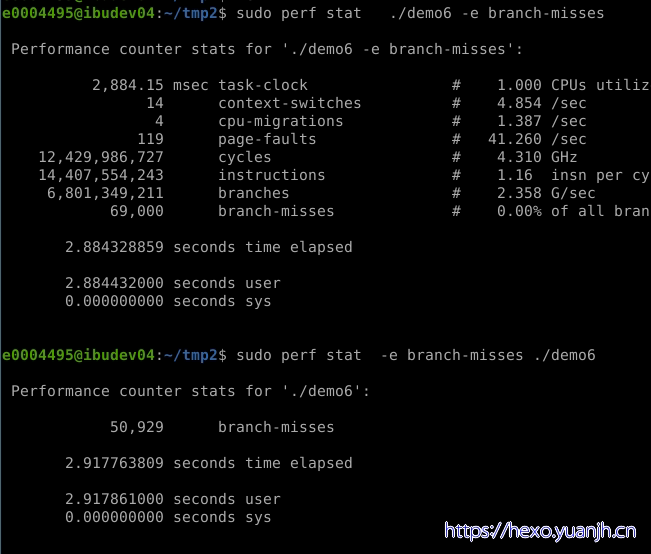
事件可以指定后缀,比如我想只跟踪发生在用户态时产生的分支预测失败,我可以这样:
sudo perf top -e branch-misses:u,cycles
全部事件都有这个要求,我还可以:
sudo perf top -e ‘{branch-misses,cycles}:u’
看看perf-list的手册,会找到更多的后缀,后缀我也用得比较少,读者对这个有兴趣,可以自己深入挖掘一下,如果有什么好的使用经验,希望也可以告诉我。
火焰图:参考,https://blog.csdn.net/xuhaitao23/article/details/124016932
perf sched replay 这个工具更是专门为调度器开发人员所设计,它试图重放 perf.data 文件中所记录的调度场景。很多情况下,一般用户假如发现调度器的奇怪行为,他们也无法准确说明发生该情形的场景,或者一些测试场景不容易再次重现,或者仅仅是出于“偷懒”的目的,使用 perf replay,perf 将模拟 perf.data 中的场景,无需开发人员花费很多的时间去重现过去,这尤其利于调试过程,因为需要一而再,再而三地重复新的修改是否能改善原始的调度场景所发现的问题。
perf 记录的默认行为是什么?:https://qa.1r1g.com/sf/ask/4744087631/
锁
1 | # perf lock record ls #记录 |
内存
1 | # perf kmem record ls #记录 |
调度
1 | # perf sched record sleep 10 |
TASK:进程名和pid。
Runtime:实际的运行时间。
Switches:进程切换的次数。
Average delay:平均的调度延迟。
Maximum delay:最大的调度延迟。
Maximum delay at:最大调度延迟发生的时刻。
原理:堆栈分析
在Linux下做性能分析3:perf:https://zhuanlan.zhihu.com/p/22194920
==堆栈跟踪==
perf的跟踪有一个错觉需要我们注意,假设我们有一个函数abc(),调用另一个函数def(),在perf的统计中,这两者是分开统计的,就是说,执行def的时间,是不计算abc的时间的,图示如下: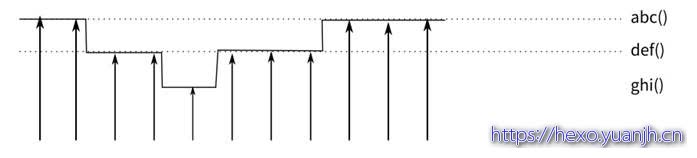
这里,abc()被击中5次,def()被击中5次,ghi被击中1次。这会给我们不少错觉,似乎abc的计算压力不大,实际上不是,你要把def和ghi计算在内才行。
但这又带来另一个问题:可能def不仅仅是abc这个函数调用啊,别人也会调用它呢,这种情况,我们怎么知道是谁导致的?
这种情况我们可以启动堆栈跟踪,也就是每次击中的时候,向上回溯一下调用栈,让调用者也会被击中,这样就就更容易看出问题来,这个原理类似这样: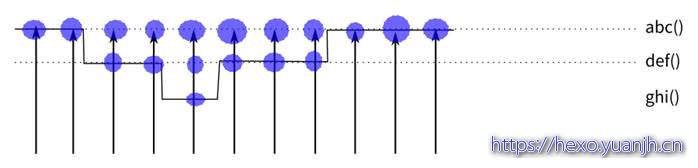
这种情况,abc击中了11次,def击中了6次,而ghi击中了1次。这样我们可以在一定程度上更容易判断瓶颈的位置。-g命令可以实现这样的跟踪,下面是一个例子: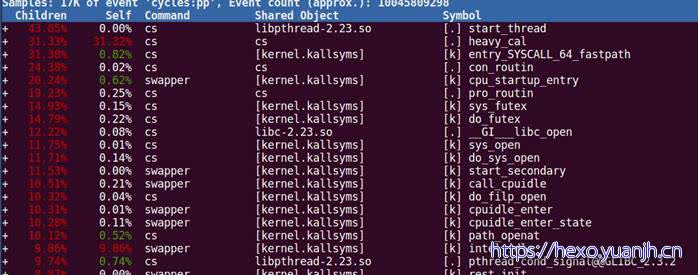
使用堆栈跟踪后,start_thread上升到前面去了,因为正是它调的heavy_cal。
使用堆栈跟踪要注意的是,堆栈跟踪受扫描深度的限制,太深的堆栈可能回溯不过去,这是有可能影响结果的。
另一个问题是,有些我们从源代码看来是函数调用的,其实在汇编一级并不是函数调用。比如inline函数,宏,都不是函数调用。另外,gcc在很多平台中,会自动把很短的函数变成inline函数,这也不产生函数调用。还有一种是,fastcall函数,通过寄存器传递参数,不会产生调用栈,也有可能不产生调用栈,这个通过调用栈回溯是有可能看不到的。
还有一种更奇葩的情况是,部分平台使用简化的堆栈回溯机制,在堆栈中看见一个地址像是代码段的地址,就认为是调用栈,这些情况都会引起堆栈跟踪上的严重错误。使用者应该对系统的ABI非常熟悉,才能很好驾驭堆栈跟踪这个功能的。
问题:这里的perf原理的函数嵌套和实际测试不大相符,进一步验证
Perf的原理、编译以及使用:https://blog.csdn.net/u013983194/article/details/112209853
每隔一个固定时间,CPU上产生一个中断,看当前是哪个进程、哪个函数,然后给对应的进程和函数加一个统计值,这样就知道CPU有多少时间在某个进程或某个函数上了。具体原作原理就是直接通过系统调用syscall/ioctl或者监听SW的event来看性能。
在Linux下做性能分析3:perf:https://zhuanlan.zhihu.com/p/22194920
读取和解析perf.data:https://qa.1r1g.com/sf/ask/834528971/
读取和解析perf.data
我正在使用命令perf record来记录性能计数器frm linux。
我想将结果perf.data用作其他编程应用程序的输入。您知道如何读取和解析其中的数据perf.data吗?有没有办法将其转换为.text文件或.csv?
带有子命令“script”的linux工具的工具中有内置的perf.data解析器和打印机perf。
转换perf.data文件
perf script > perf.data.txt
要在其他文件 ( perf record -o filename.data) 中转换 perf 记录的输出,请使用-i选项:
perf script -i filename.data > filename.data.txt
perf script记录在man perf-script,可在http://man7.org/linux/man-pages/man1/perf-script.1.html在线获得
perf-script - Read perf.data (created by perf record) and display
trace output
This command reads the input file and displays the trace recorded.
‘perf script’ to see a detailed trace of the workload that was
recorded.
`perf script` 的输出是文本并且是可读的,但是用 python/perl/awk/something 脚本解析它可能并不容易。 (2认同)
`perf script` 特别允许使用 python 和 perl 脚本处理 pref 事件。见[`man perf-script-python`](https://github.com/torvalds/linux/blob/master/tools/perf/Documentation/perf-script-python.txt) (2认同)
问题:内核态用户态,event:u解决,全部的用户态事件?未知
perf list,perf evnlist关系
evlist事件和采样频率的联动
其他工具
linux 高级测试性能工具:https://www.lmlphp.com/user/12842/article/item/431835/
无水干货-如何快速分析Linux服务器的性能问题:https://www.linuxprobe.com/performance-issues-linux-servers.html
参考
page fault的两种区别(major、minor):https://blog.csdn.net/rikeyone/article/details/108623187
Linux perf events: cpu-clock and task-clock - what is the difference:https://stackoverflow.com/questions/23965363/linux-perf-events-cpu-clock-and-task-clock-what-is-the-difference
手把手教你系统级性能分析工具perf的介绍与使用(超详细):https://blog.csdn.net/youzhangjing_/article/details/124671286
学会使用perf性能分析工具–这一篇就够了:https://qmiller.blog.csdn.net/article/details/123048333?spm=1001.2101.3001.6661.1
用Perf寻找程序中的性能热点(perf step by step):https://zhuanlan.zhihu.com/p/134721612
【开发工具】【perf】性能分析工具perf的编译和使用说明:https://blog.csdn.net/Ivan804638781/article/details/122700909
一文搞懂 | Ftrace 的实现原理:https://blog.csdn.net/melody157398/article/details/120124294
简洁说明
perf –help之后可以看到perf的二级命令。
序号 命令 作用
1 annotate 解析perf record生成的perf.data文件,显示被注释的代码。
2 archive 根据数据文件记录的build-id,将所有被采样到的elf文件打包。利用此压缩包,可以再任何机器上分析数据文件中记录的采样数据。
3 bench perf中内置的benchmark,目前包括两套针对调度器和内存管理子系统的benchmark。
4 buildid-cache 管理perf的buildid缓存,每个elf文件都有一个独一无二的buildid。buildid被perf用来关联性能数据与elf文件。
5 buildid-list 列出数据文件中记录的所有buildid。
6 diff 对比两个数据文件的差异。能够给出每个符号(函数)在热点分析上的具体差异。
7 evlist 列出数据文件perf.data中所有性能事件。
8 inject 该工具读取perf record工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。
9 kmem 针对内核内存(slab)子系统进行追踪测量的工具
10 kvm 用来追踪测试运行在KVM虚拟机上的Guest OS。
11 list 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。
12 lock 分析内核中的锁信息,包括锁的争用情况,等待延迟等。
13 mem 内存存取情况
14 record 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析。
15 report 读取perf record创建的数据文件,并给出热点分析结果。
16 sched 针对调度器子系统的分析工具。
17 script 执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等。
18 stat 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等。
19 test perf对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持perf的所有功能。
20 timechart 针对测试期间系统行为进行可视化的工具
21 top 类似于linux的top命令,对系统性能进行实时分析。
22 trace 关于syscall的工具。
23 probe 用于定义动态检查点。
Demo6.cpp源码
1 | #include <iostream> |
关于最大采样频率
相关参数:
1 | /proc/sys/kernel/ |