做应用时,会涉及到算法切换,有时会迷茫,为啥要改成这种算法?这种算法和之前有啥区别。
这篇文章就是自我扫盲的
LeNet-5
LeNet-5的特点:
使用了卷积来提取特征,结构单元一般为卷积 - 池化 -非线性激活
已经加入了非线性激活,激活函数采用了tanh和sigmoid,目前大多数情况下我们使用的是relu
池化层使用的是平均值池化,目前大多数情况下我们使用最大值池化
分类器使用了Gaussian Connections,目前已经被softmax替代
AlexNet
AlexNet的特点:
采用relu替代了tanh和sigmoid激活函数。relu具有计算简单,不产生梯度弥散等优点,现在已经基本替代了tanh和sigmoid
全连接层使用了dropout来防止过拟合。dropout可以理解为是一种下采样方式,可以有效降低过拟合问题。
卷积-激活-池化后,采用了一层LRN,也就是局部响应归一化。将一个卷积核在(x,y)空间像素点的输出,和它前后的几个卷积核上的输出做权重归一化。
使用了重叠的最大值池化层。3x3的池化核,步长为2,因此产生了重叠池化效应,使得一个像素点在多个池化结果中均有输出,提高了特征提取的丰富性
数据增强。随机的从256x256的原始图片中,裁剪得到224x224的图片,从而使一张图片变为了(256-224)^2张图片。并对图片进行镜像,旋转,随机噪声等数据增强操作,大大降低了过拟合现象。
为什么Dropout有效?
Dropout背后理念和集成模型很相似。在Drpout层,不同的神经元组合被关闭,这代表了一种不同的结构,所有这些不同的结构使用一个的子数据集并行地带权重训练,而权重总和为1。如果Dropout层有n个神经元,那么会形成2^n个不同的子结构。在预测时,相当于集成这些模型并取均值。这种结构化的模型正则化技术有利于避免过拟合。Dropout有效的另外一个视点是:由于神经元是随机选择的,所以可以减少神经元之间的相互依赖,从而确保提取出相互独立的重要特征。
Dropout有效的另外一个视点是:由于神经元是随机选择的,所以可以减少神经元之间的相互依赖,从而确保提取出相互独立的重要特征。
VGG16
VGG16是牛津大学VGG组提出的。VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
VGG的特点:
采用了较深的网络,最多达到19层,证明了网络越深,高阶特征提取越多,从而准确率得到提升。
串联多个小卷积,相当于一个大卷积。VGG中使用两个串联的3x3卷积,达到了一个5x5卷积的效果,但参数量却只有之前的9/25。同时串联多个小卷积,也增加了使用relu非线性激活的概率,从而增加了模型的非线性特征。
VGG-16中使用了1x1的卷积。1x1的卷积是性价比最高的卷积,可以用来实现线性变化,输出通道变换等功能,而且还可以多一次relu非线性激活。
VGG有11层,13层,16层,19层等多种不同复杂度的结构。使用复杂度低的模型的训练结果,来初始化复杂度高模型的权重等参数,这样可以加快收敛速度。
GoogLeNet/Inception
Google Inception是一个大家族,包括inceptionV1 inceptionV2 inceptionV3 inceptionV4等结构。它主要不是对网络深度的探索,而是进行了网络结构的改进。
InceptionV1
inceptionV1是一个设计十分精巧的网络,它有22层深,只有500万左右的参数量,模型大小仅为20M左右,但错误率却只有6.7%。它的网络结构特点如下:
去除了最后的全连接层,而使用全局平均池化来代替。这是模型之所以小的原因。AlexNet和VGG中全连接几乎占据了90%的参数量。而inceptionV1仅仅需要1000个参数,大大降低了参数量
inception module的使用。借鉴与Network in Network的思想,提出了inception module的概念,允许通道并联来组合特征。其结构如下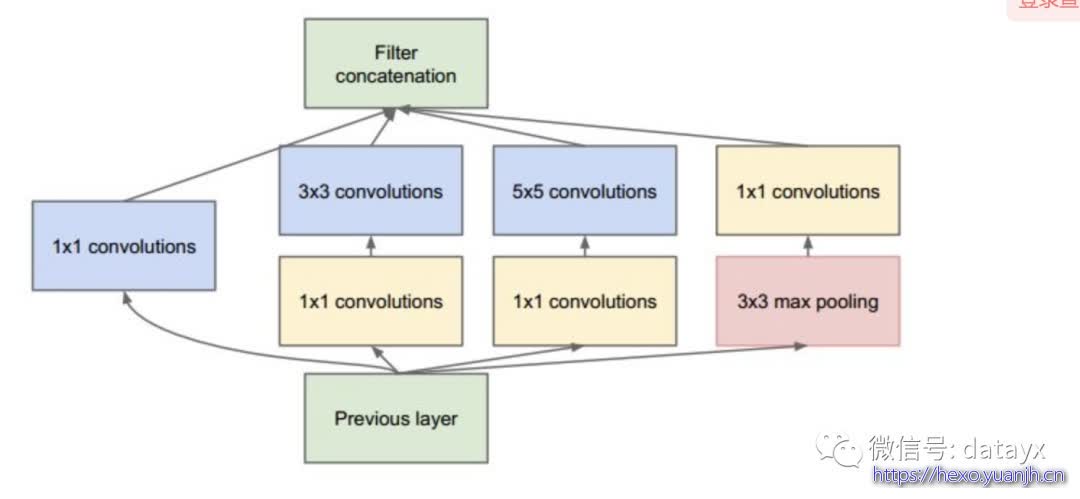
使用了1x1,3x3,5x5等不同尺寸的卷积,增加了提取特征面积的多样性,从而减小过拟合
inceptionV2
inceptionV2和V1网络结构大体相似,其模型大小为40M左右,错误率仅4.8%,低于人眼识别的错误率5.1%。主要改进如下
使用两个串联3x3卷积来代替5x5卷积,从而降低参数量,并增加relu非线性。这一点参考了VGG的设计
提出了Batch Normalization。在卷积池化后,增加了这一层正则化,将输出数据归一化到0~1之间,从而降低神经元分布的不一致性。这样训练时就可以使用相对较大的学习率,从而加快收敛速度。在达到之前的准确率之后还能继续训练,从而提高准确率。V2达到V1的准确率时,迭代次数仅为V1的1/14, 从而使训练时间大大减少。最终错误率仅4.8%
inceptionV3
inceptionV3的网络结构也没太大变化,其模型大小96M左右。主要改进如下
使用非对称卷积。用1x3+3x1的卷积来代替一个3x3的卷积,降低了参数的同时,提高了卷积的多样性
分支中出现了分支。如下图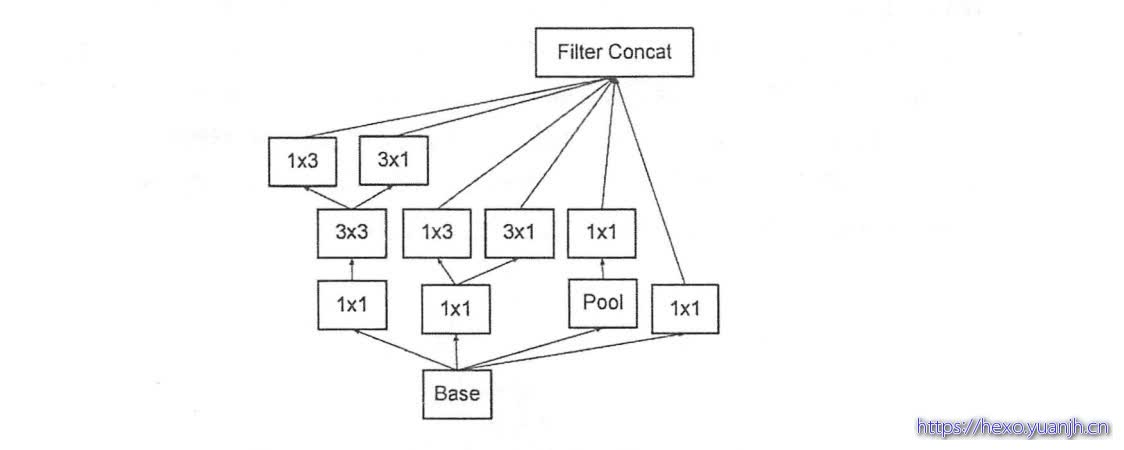
inceptionV4
inceptionV4主要是借鉴了resNet残差网络的思想,可以看做是inceptionV3和resNet的结合。inceptionV4模型大小163M,错误率仅仅为3.08%。主要在ResNet网络中讲解
ResNet
ResNetV1
ResNet提出了残差思想,将输入中的一部分数据不经过神经网络,而直接进入到输出中。这样来保留一部分原始信息,防止反向传播时的梯度弥散问题,从而使得网络深度一举达到152层。当前有很多人甚至训练了1000多层的网络,当然我们实际使用中100多层的就远远足够了。残差网络如下图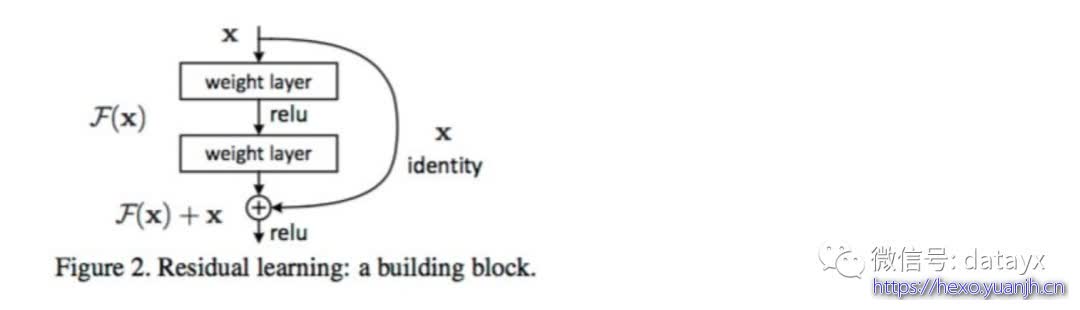
深度网络的训练问题称为退化问题,残差单元可以解决退化问题的背后逻辑在于此:想象一个网络A,其训练误差为x。现在通过在A上面堆积更多的层来构建网络B,这些新增的层什么也不做,仅仅复制前面A的输出。这些新增的层称为C。这意味着网络B应该和A的训练误差一样。那么,如果训练网络B其训练误差应该不会差于A。但是实际上却是更差,唯一的原因是让增加的层C学习恒等映射并不容易。为了解决这个退化问题,残差模块在输入和输出之间建立了一个直接连接,这样新增的层C仅仅需要在原来的输入层基础上学习新的特征,即学习残差,会比较容易。
与GoogLeNet类似,ResNet也最后使用了全局均值池化层。利用残差模块,可以训练152层的残差网络。其准确度比VGG和GoogLeNet要高,但是计算效率也比VGG高。152层的ResNet其top-5准确度为95.51%。
ResNet的主要特点,就一个字,深!
ResNetV2
ResNetV2相对于V1的最大变化,就是借鉴了inceptionV2的BN归一化思想,这样来减少模型训练时间。
MobileNet(略)
为了能将模型部署在终端上,需要在保证准确率的前提下,减小模型体积,并降低预测时的计算时间,以提高实时性。
总结
TensorFlow等框架的成熟和GPU等硬件性能的提升,使得网络结构的设计和验证日趋平民化。各种网络结构,百花齐放。
其实本质上也是在解决神经网络的几大痛点问题:
1 | 减少模型参数量,降低模型体积 |
学习网络模型,不应该去死记硬背,因为有源源不断的网络结构涌现。我们应该重点掌握每个模型的特点,以及他们是如何来解决上面列举的这些神经网络痛点的。
参考
VGG16 、VGG19 、ResNet50 、Inception V3 、Xception介绍:https://cloud.tencent.com/developer/article/1621045
一文读懂物体分类AI算法:LeNet-5 AlexNet VGG Inception ResNet MobileNet:https://blog.csdn.net/maoreyou/article/details/80612467