# . 匹配字符串中的任意一个字符,包括回车和换行 # * 匹配多个该符号之前的字符,包含0和1个 # + 匹配多个该字符之前的字符,包括1个 SELECT * FROM table WHERE column REGEXP '^a[bcd]e{2,3}f.z$';
2.、NOT IN对NULL值的处理
1 2 3 4 5
SELECT * FROM `learn`; #[id,bro] => [1=>a,2=>b, 3=>null] SELECT * FROM `learn` WHERE bro NOT IN ('a'); # [2=>b] # 如果想要[2=>b,3=>null] select * FROM learn WHERE bro NOT IN ('a') OR bro is NULL; ## ps: unique约束对null值无效,null值还会降低索引效率,所以无特殊情况,字段应设置为not null
UNION / UNION ALL 数据合并时与单独子查询的字段名无关,与字段位置有关
1 2 3 4 5 6 7 8 9
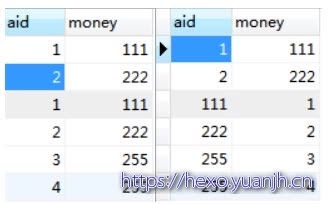
# 对应下面第一个图 SELECT id as aid,money FROM test WHERE id<3 UNION ALL SELECT id,money FROM test WHERE id<5;
# 对应下面第二个图 SELECT id as aid,money FROM test WHERE id<3 UNION ALL SELECT money,id FROM test WHERE id<5;
SELECT name,course, MAX(CASE course WHEN '数学' THEN score ELSE 0 END) as '数学', MAX(CASE course WHEN '语文' THEN score ELSE 0 END) as '语文', MAX(CASE course WHEN '英语' THEN score ELSE 0 END) as '英语' FROM `property` GROUP BY name; ####结果如下#### name course 数学 语文 英语 张三 数学 3 4 5 李四 数学 6 7 8 王五 数学 9 10 11
中间sql,便于理解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
SELECT name,course, CASE course WHEN '数学' THEN score ELSE 0 END as '数学', CASE course WHEN '语文' THEN score ELSE 0 END as '语文', CASE course WHEN '英语' THEN score ELSE 0 END as '英语' FROM `property`; ####结果如下#### name course 数学 语文 英语 张三 数学 3 0 0 张三 语文 0 4 0 张三 英语 0 0 5 李四 数学 6 0 0 李四 语文 0 7 0 李四 英语 0 0 8 王五 数学 9 0 0 王五 语文 0 10 0 王五 英语 0 0 11
然后愉快的新增用户:INSERT INTO test_user(name) VALUES(“我是”),接着愉快的反思人生:
1
Incorrect string value: '\xF0\x9F\x98\x81' for column 'name' at row 1
我是谁?我来自哪里?我在干嘛?难道是我代码里面的字符集用错了?不对啊我所有地方都用的utf8啊……
MySQL的UTF8编码是什么? 首先来看官方文档:
1 2 3
The character set named utf8 uses a maximum of three bytes per character and contains only BMP characters. The utf8mb4 character set uses a maximum of four bytes per character supports supplementary characters: For a BMP character, utf8 and utf8mb4 have identical storage characteristics: same code values, same encoding, same length. For a supplementary character, utf8 cannot store the character at all, whereas utf8mb4 requires four bytes to store it. Because utf8 cannot store the character at all, you have no supplementary characters in utf8 columns and need not worry about converting characters or losing data when upgrading utf8 data from older versions of MySQL.
我们再看看维基百科对UTF8编码的解释:
1
UTF-8 is a variable width character encoding capable of encoding all 1,112,064 valid code points in Unicode using one to four 8-bit bytes.
mysql> SELECT -> r.id, -> r.role_name AS role, -> count( u.sex ) AS sex -> FROM -> role r -> LEFT JOIN USER u ON r.id = u.role_id -> AND u.sex = 2 -> GROUP BY -> r.role_name -> ORDER BY -> r.id ASC; +----+-----------+-----+ | id | role | sex | +----+-----------+-----+ | 1 | 管理员 | 0 | | 2 | 总经理 | 2 | | 3 | 科长 | 1 | | 4 | 组长 | 2 | +----+-----------+-----+ 4 rows in set (0.00 sec)
mysql> SELECT -> r.id, -> r.role_name AS role, -> count( u.sex ) AS sex -> FROM -> role r -> LEFT JOIN USER u ON r.id = u.role_id -> WHERE -> u.sex = 2 -> GROUP BY -> r.role_name -> ORDER BY -> r.id ASC; +----+-----------+-----+ | id | role | sex | +----+-----------+-----+ | 2 | 总经理 | 2 | | 3 | 科长 | 1 | | 4 | 组长 | 2 | +----+-----------+-----+ 3 rows in set (0.00 sec)
mysql> SELECT -> r.id, -> r.role_name AS role, -> count( u.sex ) AS sex -> FROM -> role r -> LEFT JOIN USER u ON r.id = u.role_id -> WHERE -> r.role_name = '总经理' -> GROUP BY -> r.role_name -> ORDER BY -> r.id ASC; +----+-----------+-----+ | id | role | sex | +----+-----------+-----+ | 2 | 总经理 | 3 | +----+-----------+-----+ 1 row in set (0.00 sec)
mysql> SELECT -> r.id, -> r.role_name AS role, -> count( u.sex ) AS sex -> FROM -> role r -> LEFT JOIN USER u ON r.id = u.role_id -> AND r.role_name = '总经理' -> GROUP BY -> r.role_name -> ORDER BY -> r.id ASC; +----+-----------+-----+ | id | role | sex | +----+-----------+-----+ | 1 | 管理员 | 0 | | 2 | 总经理 | 3 | | 3 | 科长 | 0 | | 4 | 组长 | 0 | +----+-----------+-----+ 4 rows in set (0.00 sec)
这里可以看到数据多余了
总结:在 left join 语句中,左表过滤必须放 where 条件中,右表过滤必须放 on 条件中,这样结果才能不多不少,刚刚好。 类似案例参考:left join 注意事项
任何字段与null比较,结果都是false(即使是null与null比较)
多个字段关联查询时,如果其中一个字段为null,关联结果就是false,比如null = null and 1 = 1。 在写多字段关联的sql时,需要结合业务场景,考虑当其中一个字段为null时,本次关联还生不生效。 比如a和b都是学生表,两个表都有s_id(学生id)和c_id(班级id)列,求两个表共同的学生(学生id和班级id同时相等时,判定为同一个学生),sql为:
1
select * from a, b where a.s_id = b.s_id and a.c_id = c.c_id
-- 插入测试数据 insert into mysql_pitfalls(c1,c2,c3,c4) values(1,'1',now(),now()); insert into mysql_pitfalls(c1,c2,c3,c4) values(2,'2',now(),now()); insert into mysql_pitfalls(c1,c2,c3,c4) values(3,'3',now(),now()); insert into mysql_pitfalls(c1,c2,c3,c4) values(4,'4',now(),now());
mysql> delete from mysql_pitfalls where c4 = ( select max(c4) d from mysql_pitfalls); ERROR 1093 (HY000): You can't specify target table 'mysql_pitfalls' for update in FROM clause