前置知识
01,基础Python 编程
02,数组相关的知识
03,机器学习基础,感知机,神经网络
学习目的:tensorflow大概做什么的(近似”极值“(可能是局部极值)靠近器)
基本概念
张量(Tensor)数组or列表
TensorFlow 内部使用tf.Tensor类的实例来表示张量,每个 tf.Tensor有两个属性:
1 | dtype Tensor 存储的数据的类型,可以为tf.float32、tf.int32、tf.string… |
可以敲几行代码看一下 Tensor 。在命令终端输入 python 或者 python3 启动一个 Python 会话,然后输入下面的代码:
1 | # 引入 tensorflow 模块 |
print 一个 Tensor 只能打印出它的属性定义,并不能打印出它的值,要想查看一个 Tensor 中的值还需要经过Session 运行一下:
1 | >>> print(sess.run(t1)) |
数据流图(Dataflow Graph)有向图
数据流是一种常用的并行计算编程模型,数据流图是由节点(nodes)和线(edges)构成的有向图:
1 | 节点(nodes) 表示计算单元,也可以是输入的起点或者输出的终点,在 TensorFlow 中,每个节点都是用 tf.Tensor的实例来表示的,即每个节点的输入、输出都是Tensor |
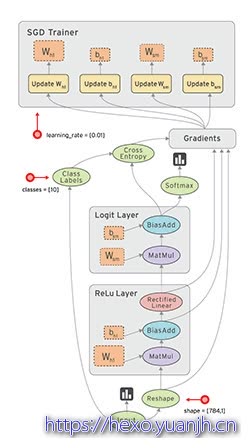
TensorFlow 中的数据流图有以下几个优点:
1 | 可并行 计算节点之间有明确的线进行连接,系统可以很容易的判断出哪些计算操作可以并行执行 |
Sesssion
我们在Python中需要做一些计算操作时一般会使用NumPy,NumPy在做矩阵操作等复杂的计算的时候会使用其他语言(C/C++)来实现这些计算逻辑,来保证计算的高效性。但是频繁的在多个编程语言间切换也会有一定的耗时,如果只是单机操作这些耗时可能会忽略不计,但是如果在分布式并行计算中,计算操作可能分布在不同的CPU、GPU甚至不同的机器中,这些耗时可能会比较严重。
TensorFlow 底层是使用C++实现,这样可以保证计算效率,并使用 tf.Session类来连接客户端程序与C++运行时。上层的Python、Java等代码用来设计、定义模型,构建的Graph,最后通过tf.Session.run()方法传递给底层执行。
构建计算图
上面介绍的是 TensorFlow 和 Graph 的概念,下面介绍怎么用 Tensor 构建 Graph。
Tensor 即可以表示输入、输出的端点,还可以表示计算单元,如下的代码创建了对两个 Tensor 执行 + 操作的 Tensor:
1 | import tensorflow as tf |
上面print的输出为
1 | Tensor("add:0", shape=(), dtype=float32) |
上面使用tf.constant()创建的 Tensor 都是常量,一旦创建后其中的值就不能改变了。有时我们还会需要从外部输入数据,这时可以用tf.placeholder 创建占位 Tensor,占位 Tensor 的值可以在运行的时候输入。
在TensorFlow 中建立模型
TensorFlow 的2个基本组件
1)占位符(Placeholder):表示执行梯度下降时将实际数据值输入到模型中的一个入口点。例如房子面积 (x) 和房价 (y_)。
2)变量:表示我们试图寻找的能够使成本函数降到最小的「good」值的变量,例如 W 和 b。
然后 TensorFlow 中的线性模型 (y = W.x + b) 就是: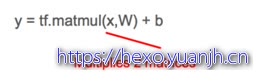
TensorFlow 中的成本函数
与将数据点的实际房价 (y_) 输入模型类似,我们创建一个占位符。
成本函数的最小方差就是:
梯度下降
有了线性模型、成本函数和数据,我们就可以开始执行梯度下降从而最小化代价函数,以获得 W、b 的「good」值。
0.00001 是我们每次进行训练时在最陡的梯度方向上所采取的「步」长;它也被称作学习率(learning rate)。
训练模型
训练包含以预先确定好的次数执行梯度下降,或者是直到成本函数低于某个预先确定的临界值为止。
1.TensorFlow 的怪异
所有变量都需要在训练开始时进行初始化,否则它们可能会带有之前执行过程中的残余值。
2.TensorFlow 会话
虽然 TensorFlow 是一个 Python 库,Python 是一种解释性的语言,但是默认情况下不把 TensorFlow 运算用作解释性能的原因,因此不执行上面的 init 。相反 TensorFlow 是在一个会话中进行;创建一个会话 (sess) 然后使用 sess.run() 去执行。
类似地我们在一个循环中调用 withinsess.run() 来执行上面的 train_step。
你需要将由 x, y_ 所组成的实际数据输入再提供给输入,因为 TensorFlow 将 train_step 分解为它的从属项:
从属项的底部是占位符 x,y_;而且正如我们之前提到的,tf.placeholders 是用来表示所要提供的实际数据点值房价 (y_) 和房子面积 (x) 的位置。
训练变量
随机、mini-batch、batch
在上面的训练中,我们在每个 epoch 送入单个数据点。这被称为随机梯度下降(stochastic gradient descent)。我们也可以在每个 epoch 送入一堆数据点,这被称为 mini-batch 梯度下降,或者甚至在一个 epoch 一次性送入所有的数据点,这被称为 batch 梯度下降。
选择随机、mini-batch、batch 梯度下降的优缺点总结在下图中:
计算成本和执行梯度下降所需的计算资源(减法、平方、加法)会增加
模型的学习和泛化的速度增加
学习率变化
学习率(learn rate)是指梯度下降调整 W 和 b 递增或递减的速度。学习率较小时,处理过程会更慢,但肯定能得到更小成本;而当学习率更大时,我们可以更快地得到最小成本,但有「冲过头」的风险,导致我们没法找到最小成本。
为了克服这一问题,许多机器学习实践者选择开始时使用较大的学习率(假设开始时的成本离最小成本还很远),然后随每个 epoch 而逐渐降低学习率。
常见的tensorflow的OP
| 类型 | 实例 |
|---|---|
| 标量运算 | add、sub、mul、div、exp、log、greater、less、equal |
| 向量运算 | concat、slice、splot、constant、rank、spape、shuffle、 |
| 矩阵运算 | matmul、matrixinverse、matrixdateminant |
| 带状态的运算 | Variable、assgin、assginadd |
| 神经元组件 | softmax、sigmoid、relu、convolution、max_pool |
| 存储、恢复 | Save、Restroe |
| 队列与同步运算 | Equeue、Dequeue、MutexAxquire、MutexRelease |
| 控制流 | Merge、Switch、Enter、Leave、Nextiteration |
参考
TensorFlow入门:第一个机器学习Demo:https://blog.csdn.net/geyunfei_/article/details/78782804
机器学习与tensorflow入门教程(任何人都能看懂):https://blog.csdn.net/ebzxw/article/details/86609997
TensorFlow入门教程:https://www.cnblogs.com/mq0036/p/12690638.html#会话的run
TensorFlow是什么:http://c.biancheng.net/view/1880.html
简单粗暴 TensorFlow 2 | A Concise Handbook of TensorFlow 2:https://tf.wiki/zh_hans/