在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
EXPLAIN用法详解
举例:EXPLAIN SELECT ……
变体: 1. EXPLAIN EXTENDED SELECT ……将执行计划“反编译”成SELECT语句,运行SHOW WARNINGS 可得到被MySQL优化器优化后的查询语句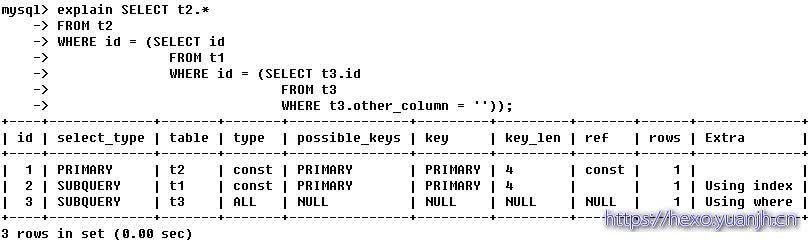
id
select 查询的序列号,标识执行的顺序
1 | id 相同,执行顺序由上至下 |
select_type
查询的类型,主要是用于区分普通查询、联合查询、子查询等。
1 | SIMPLE:简单的 select 查询,查询中不包含子查询或者 union |
table
查询涉及到的表。
1 | 直接显示表名或者表的别名 |
type
访问类型,SQL 查询优化中一个很重要的指标,结果值从好到坏依次是:system > const > eq_ref > ref > range > index > ALL。查询至少达到range级别,最好能达到ref。
1 | system:系统表,少量数据,往往不需要进行磁盘IO |
举例:
1 | system:explain select * from mysql.time_zone; |

再举一个例子,内层嵌套(const)返回了一个临时表,外层嵌套从临时表查询,其扫描类型也是 system,也不需要走磁盘 IO,速度超快。
const 扫描的条件为:
1 | 命中主键(primary key)或者唯一(unique)索引 |
如上例,id 是 主键索引,连接部分是常量1。
eq_ref 扫描的条件为,对于前表的每一行(row),后表只有一行被扫描。
再细化一点:
1 | join 查询 |
ref 扫描,可能出现在 join 里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比 eq_ref 要慢,但它仍然是一个很快的 join 类型。
range 扫描就比较好理解了,它是索引上的范围查询,它会在索引上扫码特定范围内的值。
index:该 count 查询需要通过扫描索引上的全部数据来计数,它仅比全表扫描快一点。
1 | explain count (*) from user; |
possible_keys
指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
key
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
TIPS:查询中若使用了覆盖索引,则该索引仅出现在key列表中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
Extra
十分重要的额外信息。
1 | Using filesort:MySQL 对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取。 |
关于MySQL执行计划的局限总结如下:
1.EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
2.EXPLAIN不考虑各种Cache
3.EXPLAIN不能显示MySQL在执行查询时所作的优化工作
4.部分统计信息是估算的,并非精确值
5.EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划
对于非select语句查看执行计划
在实际的工作中也经常需要查看一些诸如update、delete的执行计划,(mysql5.6的版本已经支持直接查看)但是这时候并不能直接通过explain来进行查看,而需要通过改写语句进行查看执行计划;
参考
MySQL执行计划分析工具EXPLAIN用法详解:blog.chinaunix.net/uid-25723371-id-5598143.html
MYSQL查看执行计划:https://blog.51cto.com/xiaocao13140/2126580
MySQL 执行计划详解:https://www.cnblogs.com/yinjw/p/11864477.html
MySQL——执行计划(较好的案例列表,可作为练习手册):https://www.cnblogs.com/sunjingwu/p/10755823.html
数据库系列
数据库01mysql常用操作速查
数据库02mongodb异常错误
数据库03mongodb占用磁盘空间过大
数据库04sqlite转mysql
数据库05redis常用命令整理
数据库06redis事务
数据库07redis分布式锁
数据库08redis其他
数据库09mysql常用查询实例
数据库10mysql之坑
数据库11mysql之坑null专题
数据库12经验之谈
数据库13mysql执行计划
数据库14mysql的redolog与binlog
数据库15mysql报错2006
数据库16mysql之初始密码
数据库17mysql锁机制
数据库18mysql事务和MVCC