字符,字符集,字符编码概念
字节
1 | 字节(Byte)是计算机中数据存储的基本单元,一字节等于一个8位的比特,计算机中的所有数据,不论是保存在磁盘文件上的还是网络上传输的数据(文字、图片、视频、音频文件)都是由字节组成的。 |
简单理解:0101 1100等二进制序列 ,1个字节8个0或1,
字符
1 | 你正在阅读的这篇文章就是由很多个字符(Character)构成的,字符一个信息单位,它是各种文字和符号的统称,比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符。 |
简单理解:一个约定好的,固定的,方块的“图像”或者点阵列。
字符集
1 | 字符集(Character Set)就是某个范围内字符的集合,不同的字符集规定了字符的个数,比如 ASCII 字符集总共有128个字符,包含了英文字母、阿拉伯数字、标点符号和控制符。而 GB2312 字符集定义了7445个字符,包含了绝大部分汉字字符。 |
简单理解:一个“字符”的集合,一堆特定“字符”的集合,
字符码
1 | 字符码(Code Point)指的是字符集中每个字符的数字编号,例如 ASCII 字符集用 0-127 连续的128个数字分别表示128个字符,例如 "A" 的字符码编号就是65。 |
字符编码
1 | 字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,常见的字符编码有 ASCII 编码、UTF-8 编码、GBK 编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII 字符集对应 有 ASCII 编码。ASCII 字符编码规定使用单字节中低位的7个比特去编码所有的字符。例如"A" 的编号是65,用单字节表示就是0×41,因此写入存储设备的时候就是b'01000001'。 |
综述:计算机无法存储原始的”点阵图像“(或者存储成本过高),所以计算机实际内部保存数字,然后通过 查询 数字=>图像 的映射的小本本,获取到对应的点阵信息(这里做了简单化,实际字符有可显示字符,和看不到的控制类字符,原理相同,为便于理解,本文说的字符都是可见的普通字符),这里的数字就是指字符码,而字符码需要保存到“字节”中,字节只认识0101二进制。
比如,仅支持ASCII机器上,
输入 字符A(属于ascii字符集)=>字符码的小本本=>数字(字符码)65,
按下键盘ctrl+s,保存后,
数字(字符码)65=>ASCII字符编码小本本=>0(ASCII首位必然0) 110(二进制6) 0101(二进制5)=>0110 0101
编码、解码
编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符。
基于ASCII(初代128版)的分析,字符,字符集,字符码(集)
为了方便表示截取ascii部分编码为例: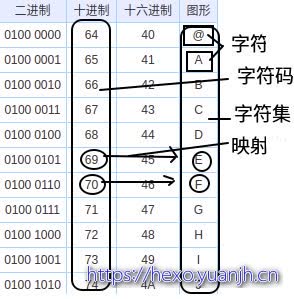
上图可以看出:大家俗称的字符集,包含2实体和1关系
2实体:字符码(集),字符(集),1关系:字符码和字符映射关系
至此,我们了解3个概念,字符,字符集和字符码.
基于ASCII的分析,字符编码,字节
再来谈谈字符编码,字符编码乍一看容易错误的理解为“字符集和字符码映射关系”
而实际上其代表的是,字符码和二进制字节的映射,也就是说,命名为“字符二进制编码“.才更为准确。
将ASCII的二进制部分划分为2部分,
第一部分,象征码,没实际含义,仅仅是约定而已。
第二部分,意义码,代表了字符码对应的二进制。有人说,好像没啥区别啊,100 0000转成十进制和 0100 0000,是一样的啊,二进制前面加0不影响转换关系。的确,对于ASCII,的确没啥影响,但需要知道首位的0的来历,首位的0属于”协议约定”,也就是说,并不具备”二进制数值0”的含义。(也就是说假如给你一个ASCII字节流,你看到了有字节首位为1,那就只能是数据保存错误。而不会尝试去映射表中查找数值为2xx,或13x的键值取,因为首位本来就无意义,仅仅约定0而已。这个约定的好处是 字符码(恰好)=二进制字节)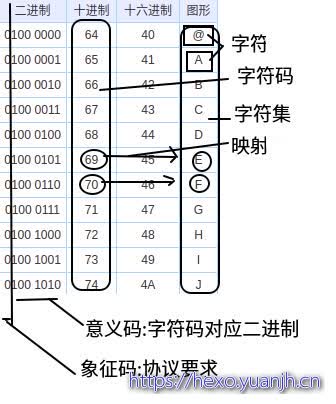
仅从ascii编码是很难体会到,字符编码和字节关系的。
基于Unicode,Utf8分析,字符编码,字节
再来看看utf8协议吧。
目前大家俗称的utf8协议,其实包含2部分,第一部分,unicode的字符码-字符关系.第二部分,utf8的字符码-二进制字节关系.
先谈谈Unicode编码
它只是字符集(其实也包含字符码集和映射关系,单纯的字符集是没有意义的)(没有规定这个二进制该如何存储、传输的)。它的字符集称为Universal Character Set (UCS),它规定了需要多少字节存储字字符,分别有2个字节和4个字节,各自对应UCS-2、UCS-4。而UTF(Unicode Transformation Format)规定了字符如何传输和存储。UTF又分为UTF-8、UTF-16和UTF-32。我们重点介绍下UTF-8。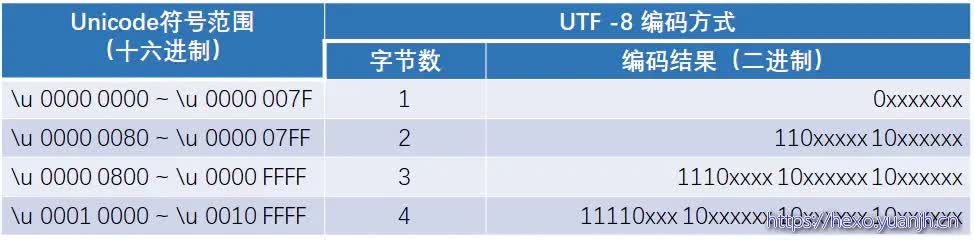
首先(本例)unicode本身是四个字节的。
那么最简单的方式,unicode直接保存到硬盘就行了呗?没错,这个的确简单,也就是ASCII的思路,可以理解为字符码的原样保存(由于ASCII首位为0的约定,其字符码恰好等于二进制字节码,所以可看做原样保存)
但问题也很明显,占用过大存储空间。所以,需要将字符码和保存的二进制字节做一种映射,力求达到最大可能的压缩存储空间。这种实现压缩的方法就是UTF8。
Unicode 和 UTF-8 之间的转换
以汉字 “柯” 为例。已知 “柯” 的Unicode码是 \u 67ef(0110 0111 1110 1111),根据上表,我们可以知道 “柯”这个Unicode对应的UTF-8编码需要3个字节。然后,从0110 0111 1110 1111从由往左依次取数放入到1110 xxxx 10xx xxxx 10xx xxxx中,得到最终的结果是 1110 0110 1001 1111 1010 1111,转换成十六进制是E6 9F AF。
完整转换流程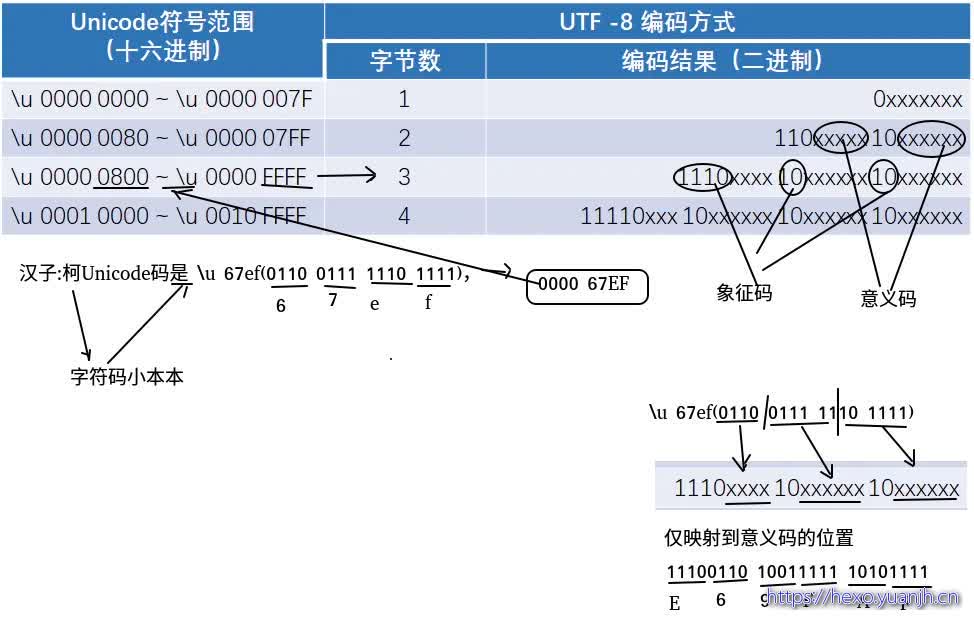
这里很明显,字符码!=二进制字节码
回看GBK

看不懂?
例如,二进制:1000 0001 0100 0001=>81 41=>纵轴81,横轴41,就是图中a点,将a点对应的 字符 取出来即可。

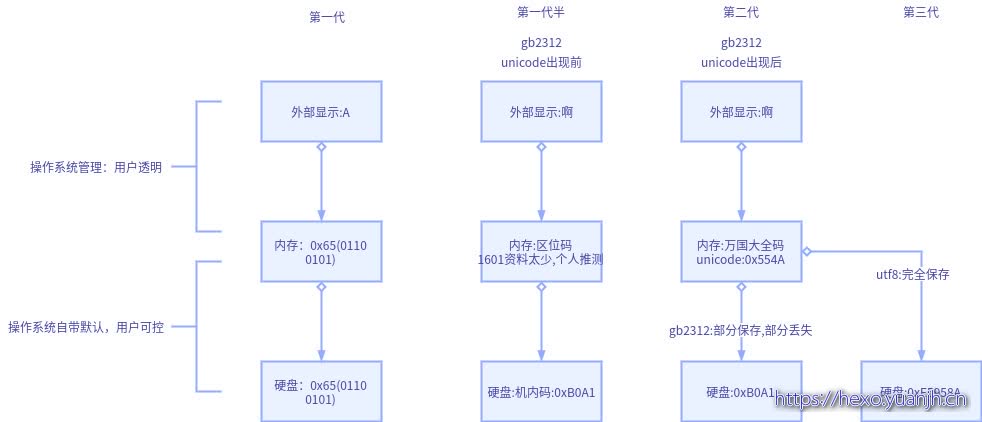
再次理解ASCII,GBK,UTF8
一代:ASCII,最简单,字符A=》数字65(0110 0101)=>保存(0110 0101)(保存的首0是约定,不同于65翻译来的0,实际效果等价于字符码的直接保存)
二代:GBK,ASCII的扩大版+压缩增强版,相比ASCII,双字节可保存更多字符集,同时,也支持单字符表示,所以等价于也有了压缩效果。
三代:UTF8+unicode
二代gbk的字符码和二进制字节码也是对应的,可将二进制字节码看做字符码的直接保存。由于采用压缩编码,效果也不错。而三代将字符码和二进制字节码解耦,unicode,仅仅约定字符码和字符关系,对字符码的保存未做限制(其实稍稍限制了位数),所以需要另一个工具进行规定,这个工具就是UTF8。
所以从使用和功能层次角度,UTF8+unicode,才和GBK,以及ASCII是同等级对象。单独的UTF8仅仅是一种数值压缩方式。现实中,我们常说UTF8其实就是unicode+utf8,也可以看作和gbk同级别东西(主要原因是unicode是”大全码”,但协议角度是”半协议”(字符=>int),utf8也是”大全压缩法”,协议角度也是”半协议”(int=>binary),而ascii,gbk等本身是”非大全码/残缺码”(无法表示世界所有字符),但协议角度又是”完整协议”(字符=>int=>binary),所以自然那2个“大全码”但“半协议”经常成双入对了)。
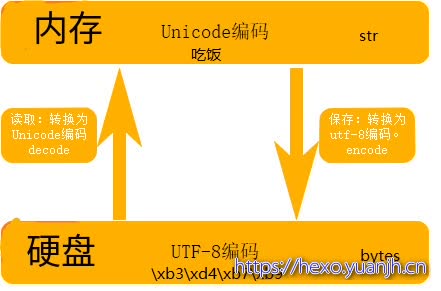
编码和解码
研发过程中,如果将字符转utf8保存,往往容易写成str.encode(‘utf8’).其实恰恰相反,encode含义是encode为bytes。
应该使用str.decode(‘utf8’)
参考文献
字符集和字符编码的区别
理清字符集和字符编码关系
深入理解Python字符编码
GBK编码具体解析(附GBK码位分布图)
ASCII、Unicode、GBK、UTF-8之间的关系
字符集与编码(九)——GB2312,GBK,GB18030
【2020Python修炼记13】Python语法入门—字符编码