数据预处理常用python方法
01 从数据中读取数据
1 | import pandas as pd |
02 从csv中读取数据
1 | df = pd.read_csv(loggerfile, header=None, sep=',') |
03 数据标准化(z-score)
计算方式是将特征值减去均值,除以标准差。
sklearn.preprocessing.scale(X)
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
1 | scaler = sklearn.preprocessing.StandardScaler().fit(train) |
实际应用中,需要做特征标准化的常见情景:SVM
标题:【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
地址:http://www.cnblogs.com/chaosimple/p/4153167.html
04 正则化
将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
p-范数的计算公式:||X||p=(|x1|^p+|x2|^p+...+|xn|^p)^1/p该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性。
1 | 1、可以使用preprocessing.normalize()函数对指定数据进行转换: |

标题:python中常用的九种预处理方法分享
地址:http://www.jb51.net/article/92408.htm
05 归一化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
sklearn.preprocessing.normalize(X, norm=’l2’)
得到:
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2 norm,变换后每个样本的各维特征的平方和为1。
类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。
还有max norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
06 特征二值化(Binarization)
给定阈值,将特征转换为0/1
1 | binarizer = sklearn.preprocessing.Binarizer(threshold=1.1) |
07 标签二值化(Label binarization)
1 | lb = sklearn.preprocessing.LabelBinarizer() |
08 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
1 | enc = preprocessing.OneHotEncoder() |
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
1 | newdf=pd.get\_dummies(df,columns=\["gender","title"\],dummy\_na=True) |
09 标签编码(Label encoding)
1 | le = sklearn.preprocessing.LabelEncoder() |
10 特征中含异常值时
1 | sklearn.preprocessing.robust_scale |
11 生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
1 | poly = sklearn.preprocessing.PolynomialFeatures(2) |
原始特征: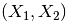
转化后: