噪声
模型学习的上限(也可以说是误差的下限),不可控的错误很难避免,这被称为不可约偏差(irreducible error),即噪声无法通过模型来消除。噪声通常是出现在“数据采集”的过程中的,且具有随机性和不可控性,比如数据标注(通常会有人工参与)的时候手滑或者打了个盹、采集用户数据的时候仪器产生的随机性偏差、或者被试在实验中受到其他不可控因素的干扰等。(另一个角度,将信息数量化过程中的量纲(米,厘米,千克,克,精度等,测试环境温度湿度等等)都无法获取到100%的精确信息)
方差
不同样本集上模型输出值的变异性,方差的大小反应了样本在总体数据中的代表性,或者说不同样本下模型预测的稳定性。比如现在要通过一些用户属性去预测其消费能力,结果有两个样本,一个样本中大多数都是高等级活跃会员,另一个则是大部分是低质量用户,两个样本预测出来的数据的差异就非常大,也就是模型在两个样本上的方差很大。如果模型在多个样本下的训练误差(经验损失)“抖动”比较厉害,则有可能是样本有问题。
偏差
模型对训练数据的拟合能力。把模型比喻成一支猎枪,预测的目标是靶心,假设射手不会手抖且视力正常,那么这支枪(模型)的能力就可以用多次射击后的中心(相当于预测值的期望,即)和靶心的距离来衡量(偏离了靶心有多远)。
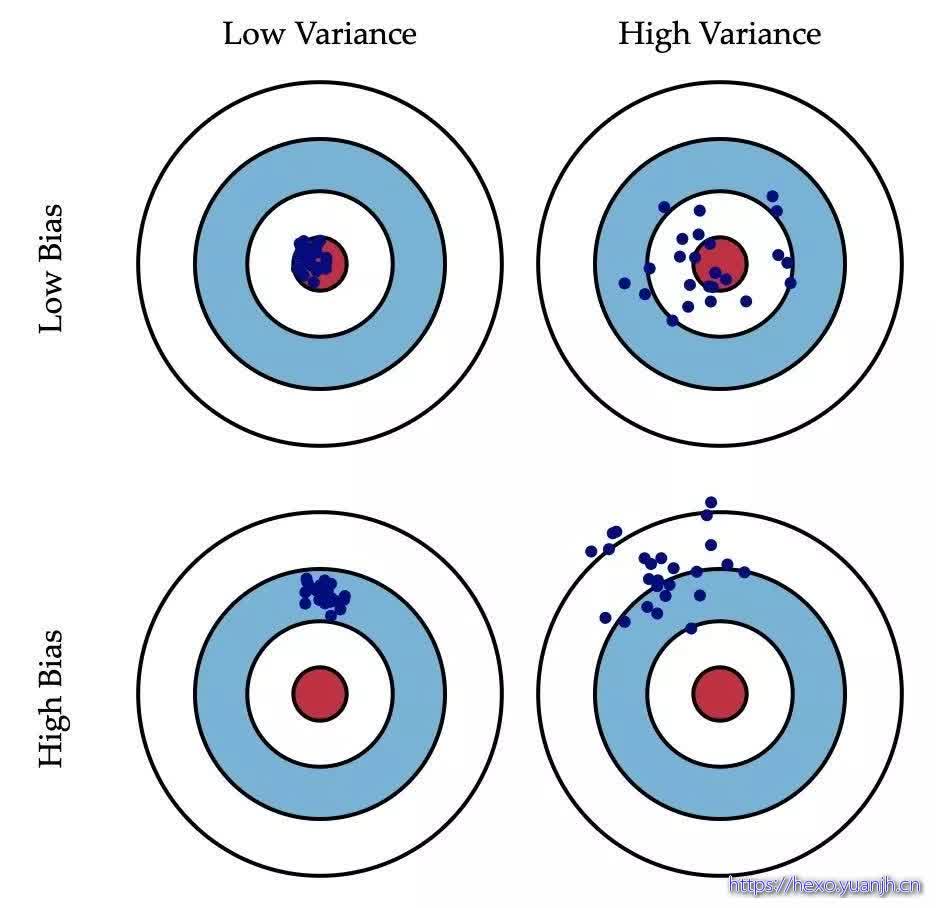

偏差和方差的权衡
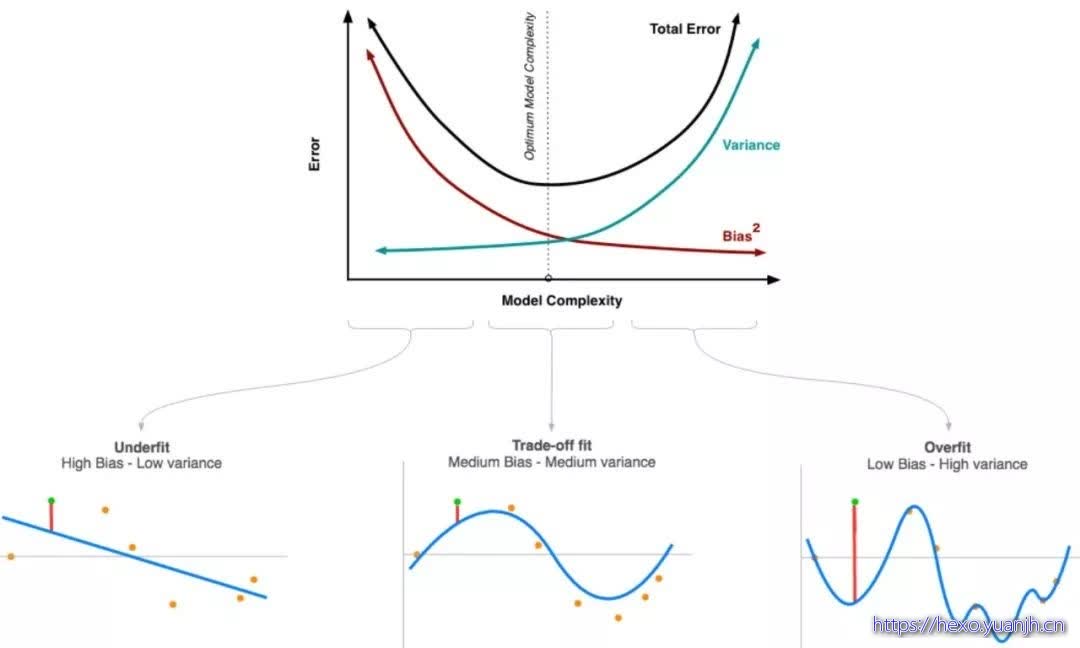
模型训练不足时,就出现欠拟合(under-fitting),此时模型的误差主要来自偏差,如果是在分类任务中可能在训练集和测试集上的准确率都非常低(反过来说就是错误率都很高);训练模型时用力过猛时就会发生“过拟合” (over-fitting),在分类任务上可能会出现训练集上准确率高,测试集上准确率低。此时样本本身的特异性也会纳入模型之中,导致预测值的变异性更大。
如何降低偏差?
参考Machine Learning Yearning,Andrew Ng
增加算法的复杂度,比如神经网络中的神经元个数或者层数,增加决策树中的分支和层数等。不过增加模型复杂度可能会导致方差(variance)的增加,如果有必要,需要添加正则化项来惩罚模型的复杂度(降低方差);
优化输入的特征,检查特征工程中是否遗漏掉具有预测意义的特征。增加更多的特征也许能同时改善方差(variance)和偏差(bias),不过理论上来说,特征越多方差(variance)也就越大(可能又需要正则化);
削弱或者去除已有的正则化约束(L1正则化,L2正则化,dropout等),不过有增加方差的风险;
调整模型结构,比如神经网络的结构;
如何降低方差?
参考Machine Learning Yearning,Andrew Ng
扩大训练样本,样本太小(代表性不够)是方差大的首要原因,增加样本是减少方差最简单有效的方式;
增加正则化约束(比如L1正则化,L2正则化,dropout等),正则化降低方差的同时也可能增大偏差;
筛选输入的特征(feature selection),这样输入的特征变少后,方差也会减小;
降低算法模型复杂度,比如对决策树的剪枝、减少神经网络的层数等;
优化模型的结构有时候也会有用;
参考
如何理解算法中的偏差、方差和噪声?:https://www.sohu.com/a/317862976_654419
偏差 / 方差 / 噪声:https://blog.csdn.net/weixin_44695969/article/details/102532099
机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?:https://www.zhihu.com/question/27068705